MAX Image Resolution Enhancer
v1.1.0

Dieses Repository enthält Code, um einen Bildauflösung Enhancer zu instanziieren und bereitzustellen. Dieses Modell ist in der Lage, ein pixeliges Bild um den Faktor 4 zu verbessern und gleichzeitig photo-realistische Details zu erzeugen.
Der GaN basiert auf diesem Github -Repository und auf diesem Forschungsartikel.
Das Modell wurde auf 600.000 Bildern des OpenImages V4 -Datensatzes trainiert, und die Modelldateien werden auf dem Speicher IBM Cloud -Objekts gehostet. Der Code in diesem Repository stellt das Modell als Webdienst in einem Docker -Container bereit. Dieses Repository wurde als Teil des IBM Developer Model Asset Exchange entwickelt und die öffentliche API wird von IBM Cloud angetrieben.
| Domain | Anwendung | Industrie | Rahmen | Trainingsdaten | Eingabedatenformat |
|---|---|---|---|---|---|
| Vision | Super-Auflösung | Allgemein | Tensorflow | OpenImages v4 | Bild (RGB/HWC) |
| Set5 | Srgan des Autors | Dieser Srgan |
|---|---|---|
| PSNR | 29.40 | 29,56 |
| Ssim | 0,85 | 0,85 |
| Set14 | Srgan des Autors | Dieser Srgan |
|---|---|---|
| PSNR | 26.02 | 26.25 |
| Ssim | 0,74 | 0,72 |
| BSD100 | Srgan des Autors | Dieser Srgan |
|---|---|---|
| PSNR | 25.16 | 24.4 |
| Ssim | 0,67 | 0,67 |
Die Leistung dieser Implementierung wurde auf drei Datensätzen bewertet: SET5, SET14 und BSD100. Die Metriken PSNR (Peak Signal zu Rauschverhältnis) und SSIM (Strukturähnlichkeitsindex) wurden bewertet, obwohl das Papier die MOS (mittlere Meinungsbewertung) als die günstigste Metrik erörtert. Im Wesentlichen handelt die SRGAN -Implementierung mit einem besseren PSNR- oder SSIM -Score für ein Ergebnis, das das menschliche Auge anspricht. Dies führt zu einer Sammlung von Ausgabebildern mit klaren und realistischeren Details.
Hinweis: Die SRGAN in der Zeitung wurde auf 350.000 Bildnetierproben trainiert, während dieser Srgan auf 600.000 Openimages V4 -Bildern trainiert wurde.
| Komponente | Lizenz | Link |
|---|---|---|
| Dieses Repository | Apache 2.0 | LIZENZ |
| Modellgewichte | Apache 2.0 | LIZENZ |
| Modellcode (3. Partei) | MIT | LIZENZ |
| Testproben | CC um 2.0 | Asset Readme |
| CC0 | Asset Readme |
docker : Die Docker-Befehlszeilenschnittstelle. Befolgen Sie die Installationsanweisungen für Ihr System.Um das Docker -Image auszuführen, das automatisch die API des Modells startet, rennen Sie:
$ docker run -it -p 5000:5000 quay.io/codait/max-image-resolution-enhancer
Dadurch wird ein vorgefertigtes Bild aus der Registrierung von Quay.IO Container (oder verwendet ein vorhandenes Bild, falls bereits vor Ort zwischengespeichert). Wenn Sie das Modell vor Ort eher auschecken und die folgenden Schritte ausführen können.
Sie können den modellbezogenen Microservice für Red Hat OpenShift bereitstellen, indem Sie die Anweisungen für die OpenShift-Webkonsole oder die OpenShift-Containerplattform CLI in diesem Tutorial befolgen und quay.io/codait/max-image-resolution-enhancer als Bildname angeben.
Sie können das Modell auch auf Kubernetes über das neueste Docker -Bild auf Quay bereitstellen.
Führen Sie auf Ihrem Kubernetes -Cluster die folgenden Befehle aus:
$ kubectl apply -f https://github.com/IBM/max-image-resolution-enhancer/raw/master/max-image-resolution-enhancer.yaml
Das Modell wird intern in Port 5000 erhältlich sein, kann aber auch extern über den NodePort aufgenommen werden.
Hier finden Sie hier ein ausführlicheres Tutorial zur Bereitstellung dieses MAX -Modells für die Produktion auf IBM Cloud.
Klonen Sie dieses Repository lokal. Führen Sie in einem Terminal den folgenden Befehl aus:
$ git clone https://github.com/IBM/max-image-resolution-enhancer.git
Wechseln Sie das Verzeichnis in den Repository -Basisordner:
$ cd max-image-resolution-enhancer
Um das Docker -Bild lokal zu erstellen, laufen Sie:
$ docker build -t max-image-resolution-enhancer .
Alle erforderlichen Modellvermögen werden während des Erstellungsprozesses heruntergeladen. Beachten Sie , dass dieses Docker -Bild derzeit nur CPU ist (wir werden später Unterstützung für GPU -Bilder hinzufügen).
Um das Docker -Image auszuführen, das automatisch die API des Modells startet, rennen Sie:
$ docker run -it -p 5000:5000 max-image-resolution-enhancer
Der API -Server generiert automatisch eine interaktive Swagger -Dokumentationsseite. Gehen Sie zu http://localhost:5000 um es zu laden. Von dort aus können Sie die API untersuchen und auch Testanforderungen erstellen.
Verwenden Sie das model/predict des Endpunkts, um ein Testbild zu laden (Sie können eines der Testbilder aus dem Ordner der samples/test_examples/low_resolution verwenden), um ein hochauflösendes Ausgangsbild zurückzugewinnen.
Das ideale Eingabebild ist eine PNG-Datei mit einer Auflösung zwischen 100x100 und 500 x 500, vorzugsweise ohne Verarbeitung nach der Aufnahme und auffällige Farben. Das Modell ist in der Lage, Details aus einem pixeligen Bild (niedriger DPI) zu generieren, kann jedoch kein "verschwommenes" Bild korrigieren.
 Links: Eingabebild (128 × 80). Rechts: Ausgangsbild (512 × 320)
Links: Eingabebild (128 × 80). Rechts: Ausgangsbild (512 × 320)
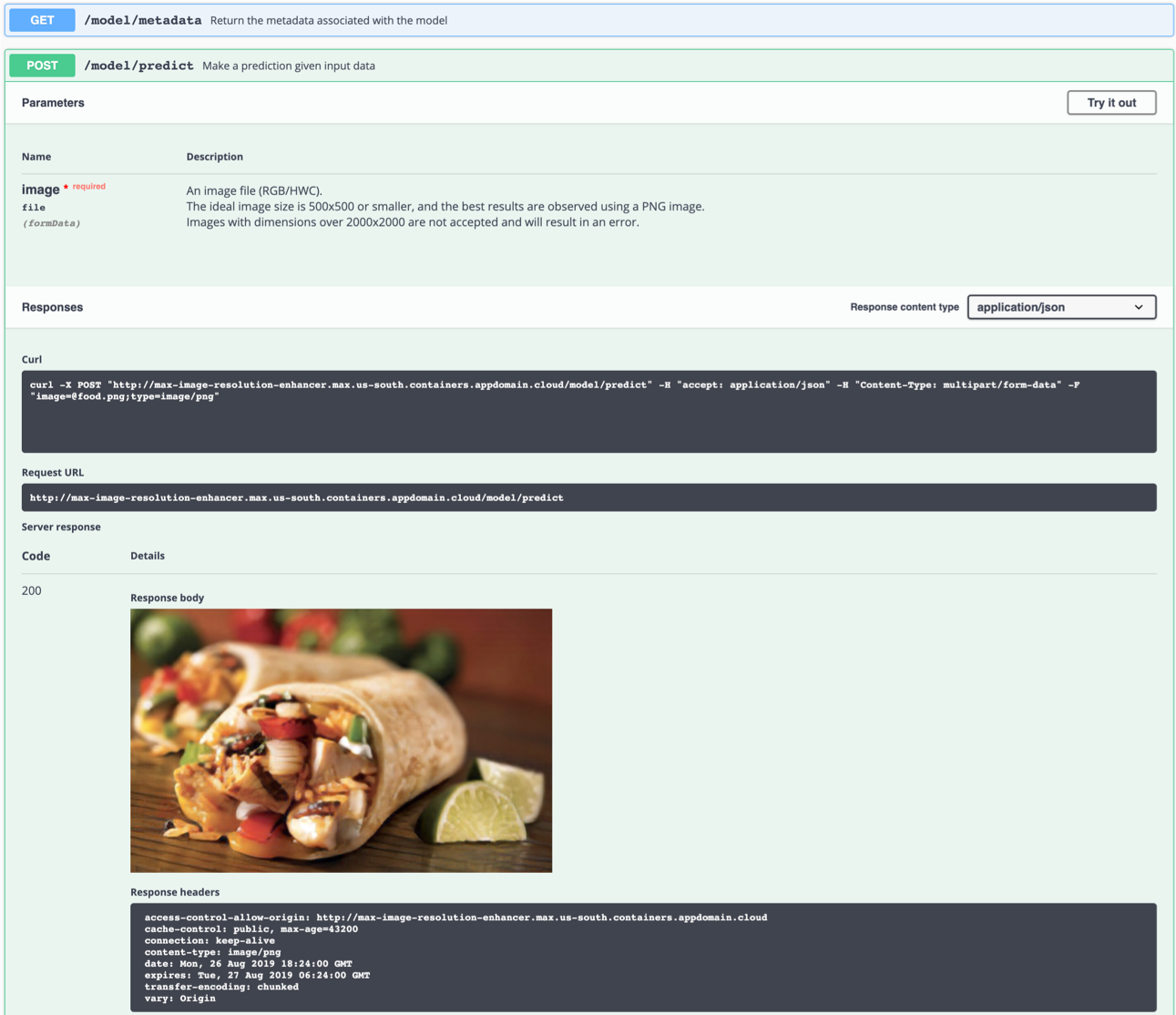
Sie können es auch in der Befehlszeile testen, zum Beispiel:
$ curl -F "image=@samples/test_examples/low_resolution/food.png" -XPOST http://localhost:5000/model/predict > food_high_res.png
In dem obigen Befehl sendet die Datei mit niedriger Auflösung food.png an das Modell und speichert das hochauflösende Ausgabebild in der Datei food_high_res.png im Stammverzeichnis.
Um die Flask -API -App im Debug -Modus auszuführen, bearbeiten Sie config.py , um DEBUG = True unter den Anwendungseinstellungen festzulegen. Sie müssen dann das Docker -Bild wieder aufbauen (siehe Schritt 1).
Bitte denken Sie daran, DEBUG = False festzulegen, wenn das Modell in der Produktion ausgeführt wird.
Um den Docker -Container zu stoppen, geben Sie CTRL + C in Ihrem Terminal ein.
model/predict Endpunkt tötet den Docker -Container mit der Killed Nachricht abDies ist wahrscheinlich durch die Standardbeschränkung der Speicherzuweisung von Docker auf 2 GB verursacht. Navigieren Sie unter der Docker -Desktop -Anwendung zum Menü
Preferences. Verwenden Sie den Schieberegler, um den verfügbaren Speicher auf 8 GB zu erhöhen und Docker Desktop neu zu starten.
Dieses Modell erzeugt Details im Grunde genommen "aus der Luft". Es ist nicht möglich, etwas aus dem Nichts zu schaffen, ohne Annahmen zu treffen. Das Netzwerk versucht, Elemente im Bild mit niedriger Auflösung zu erkennen, aus dem es schließen kann, wie die Realität (menschliches Auge | Superauflösung) aussehen können. Wenn eine Gruppe von Pixeln stark einer Beobachtung ähnelt, die nicht mit dem Bildinhalt zusammenhängt, kann dies dazu führen, dass Ergebnisse beobachtet werden, die nicht „physisch möglich“ sind.
Zum Beispiel: Ein weißes Pixel in einem Bild mit niedriger Auflösung könnte in eine Schneeflocke umgewandelt worden sein, obwohl das ursprüngliche Bild in der Wüste aufgenommen worden sein könnte. Dieses Beispiel ist imaginär und wurde eigentlich nicht beobachtet.
Die Beobachtung von Artefakten in einigen Bildern ist leider unvermeidlich, da jedes neuronale Netzwerk technischen Einschränkungen und Merkmalen der Trainingsdaten unterliegt.
Denken Sie daran, dass die besten Ergebnisse mit Folgendem erzielt werden:
- Ein PNG -Bild
- Ein Bild, das ausreichend eingefleischt ist. Während des Prozesses gruppiert sich die Netzwerkblocke zusammen. Wenn der Block mehr Details enthält als das Netzwerk produziert, ist das Ergebnis falsch.
- Ein Bild unter natürliches Licht, ohne Filter und mit wenigen hellen oder auffälligen Farben. Das neuronale Netzwerk wurde nicht auf stark bearbeiteten Bildern geschult.
- Ein Bild, das eine ausreichend hohe Auflösung hat, um das Netzwerk nicht mit mehreren Möglichkeiten zu verwechseln (z. B. ein einziges Pixel in einem Bild mit sehr geringer Auflösung könnte ein ganzes Auto, eine Person, ein Sandwich, ..) darstellen.)
- Das Modell ist in der Lage, Details aus einem pixeligen Bild (niedriger DPI) zu generieren, kann jedoch kein "verschwommenes" Bild korrigieren.
Wenn Sie daran interessiert sind, zum Model Asset Exchange -Projekt beizutragen oder Fragen zu haben, befolgen Sie die Anweisungen hier.


