Pytorch NCE
More readability
噪声对比估计(NCE)是一种近似方法,用于围绕大型软磁层的巨大计算成本工作。基本思想是在培训阶段将预测问题转换为分类问题。已经证明,只要噪声分布足够接近真实的标准,这两个标准就会收敛到相同的最小点。
NCE桥接生成模型和判别模型之间的差距,而不是简单地加速软磁层层。使用NCE,您可以减少努力将几乎所有东西变成后部。
参考:
NCE:
http://www.cs.helsinki.fi/u/ahyvarin/papers/gutmann10aistats.pdf
在rnnlm上:
https://pdfs.semanticscholar.org/144e/357B1339C27CCE7A1E69F0899C21D8140C1F.pdf.pdf
SoftMax加速方法的评论:
http://ruder.io/word-embeddings-softmax/
NCE与IS(重要性采样):NCE是二进制分类,而是多类分类问题。
http://demo.clab.cs.cmu.edu/cdyer/nce_notes.pdf
NCE与Gan(生成对抗网络):
https://arxiv.org/abs/1412.6515
在NCE中,通常使用umigram分布来近似噪声分布,因为它很快从中采样。来自umram的采样等于多项式抽样,这很复杂
由于可以在培训之前获得umram分布,并且在培训中保持不变,因此建议一些工作以利用此属性来加速采样程序。别名方法是其中之一。
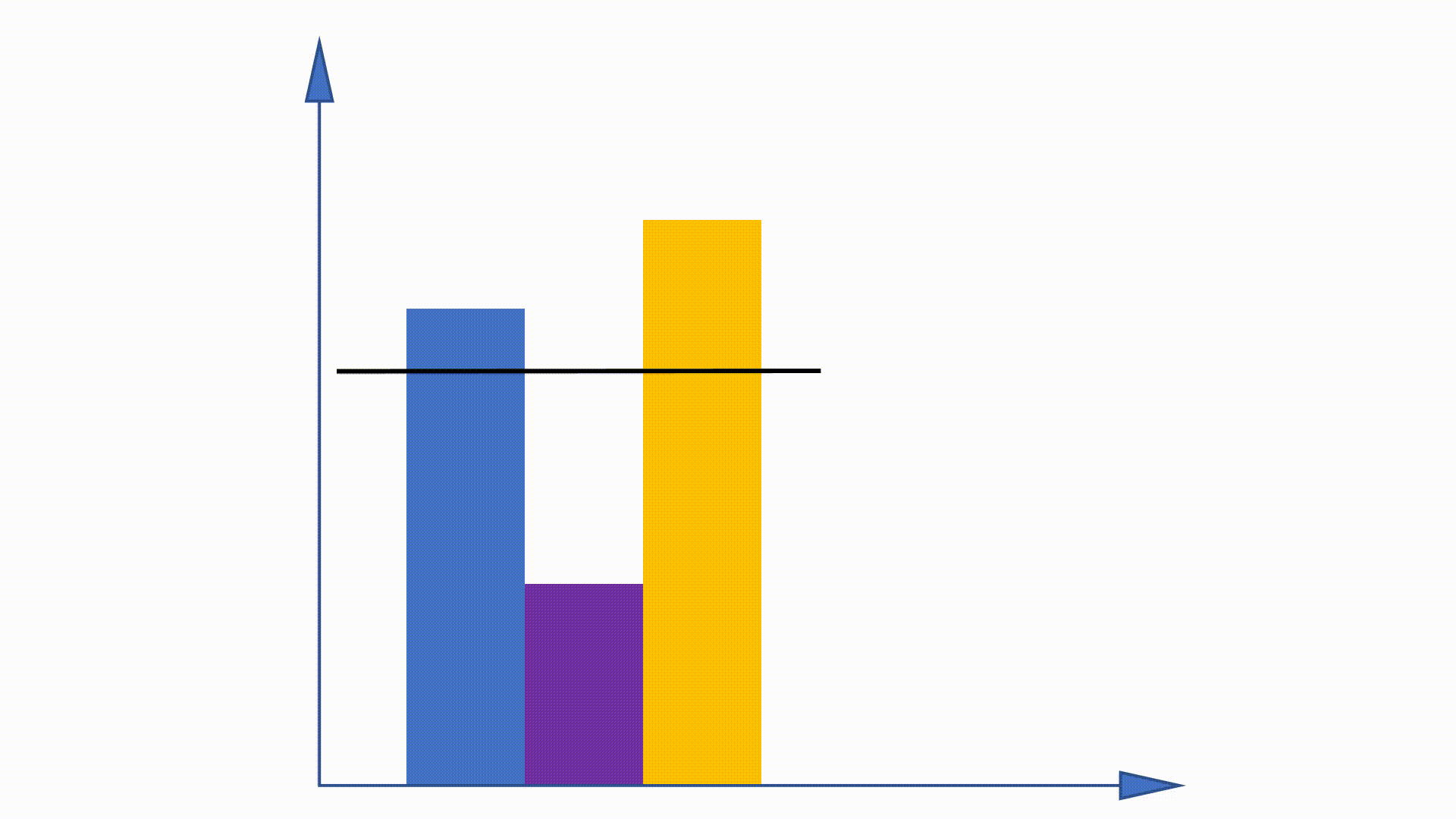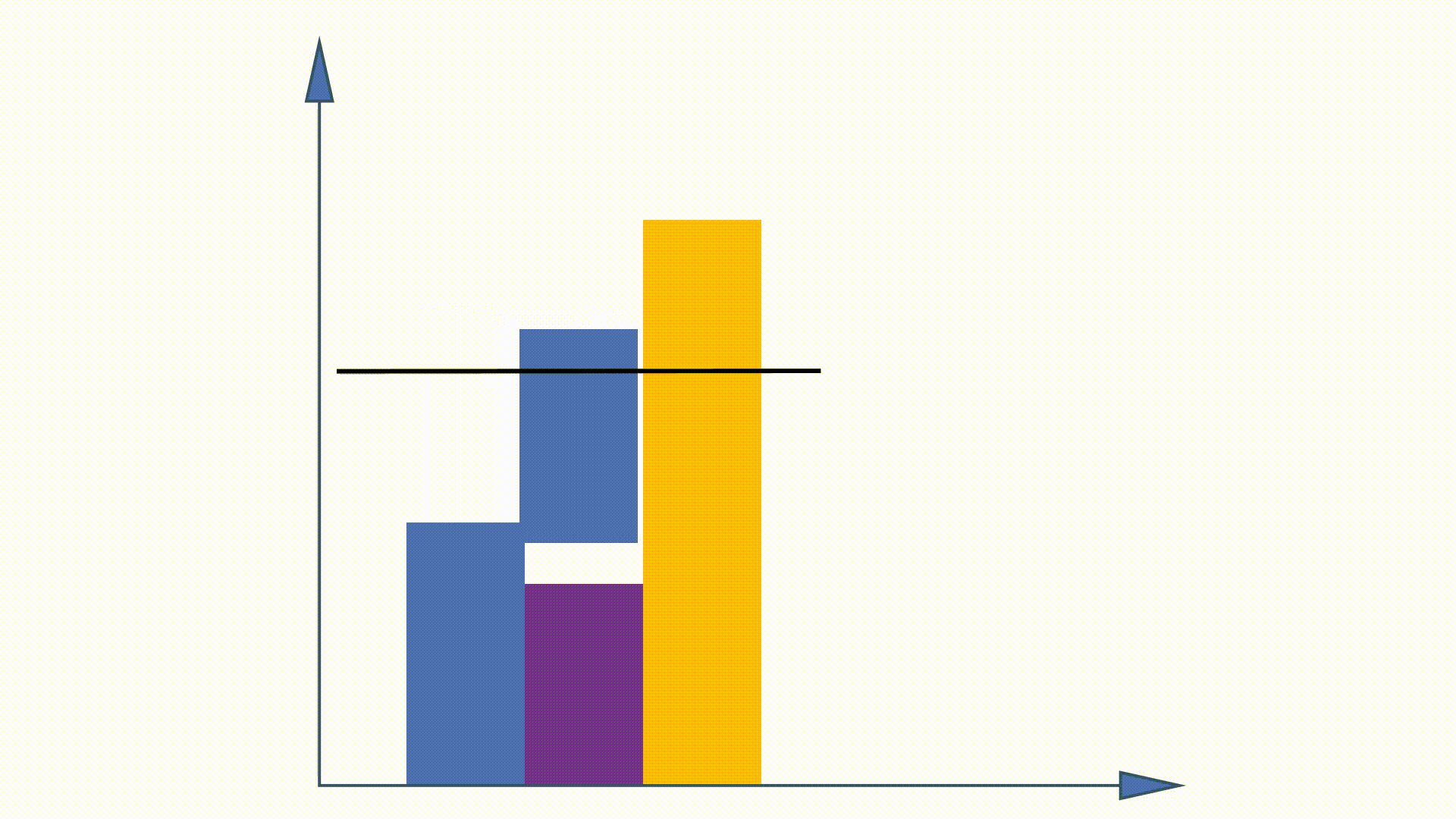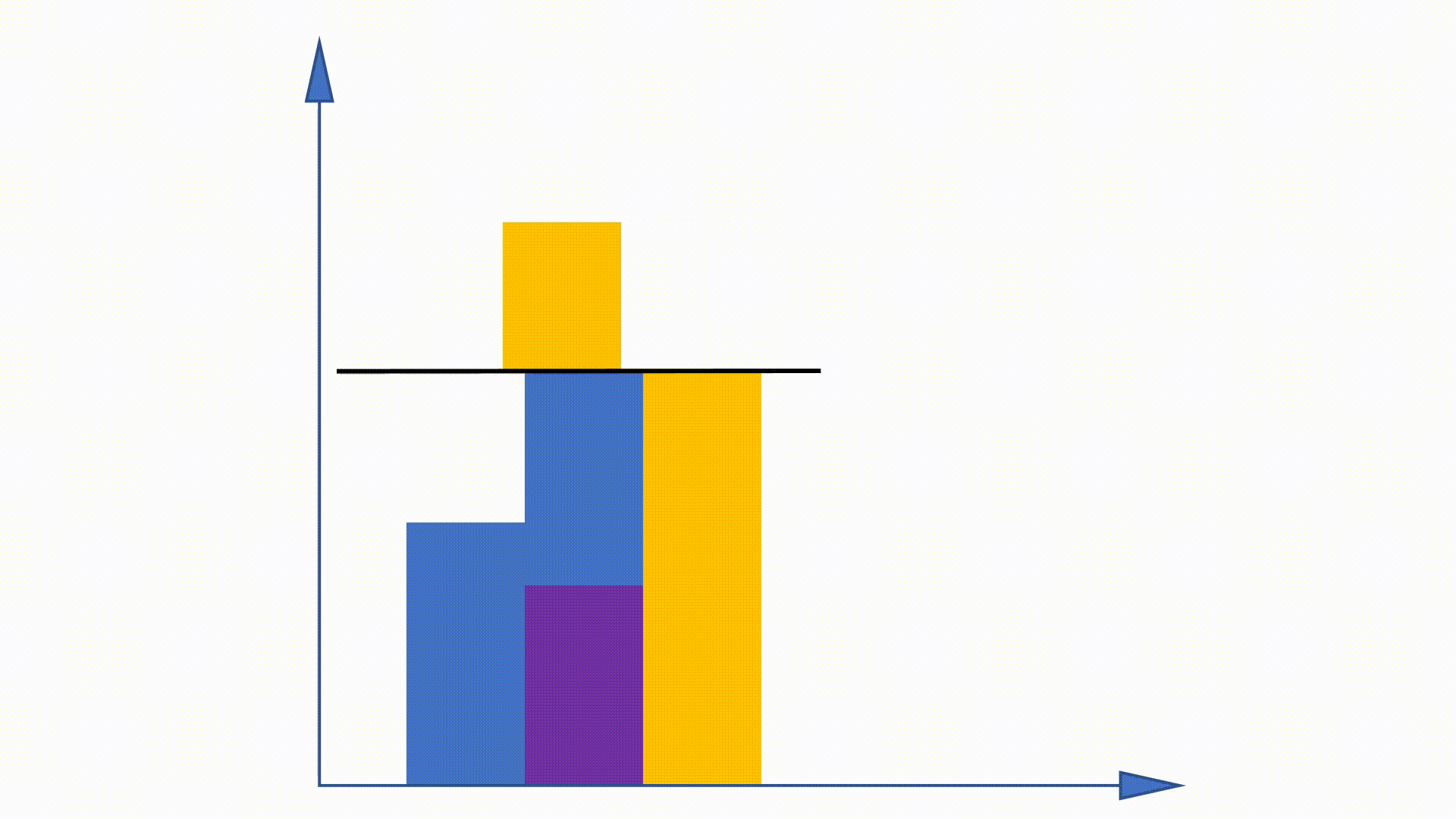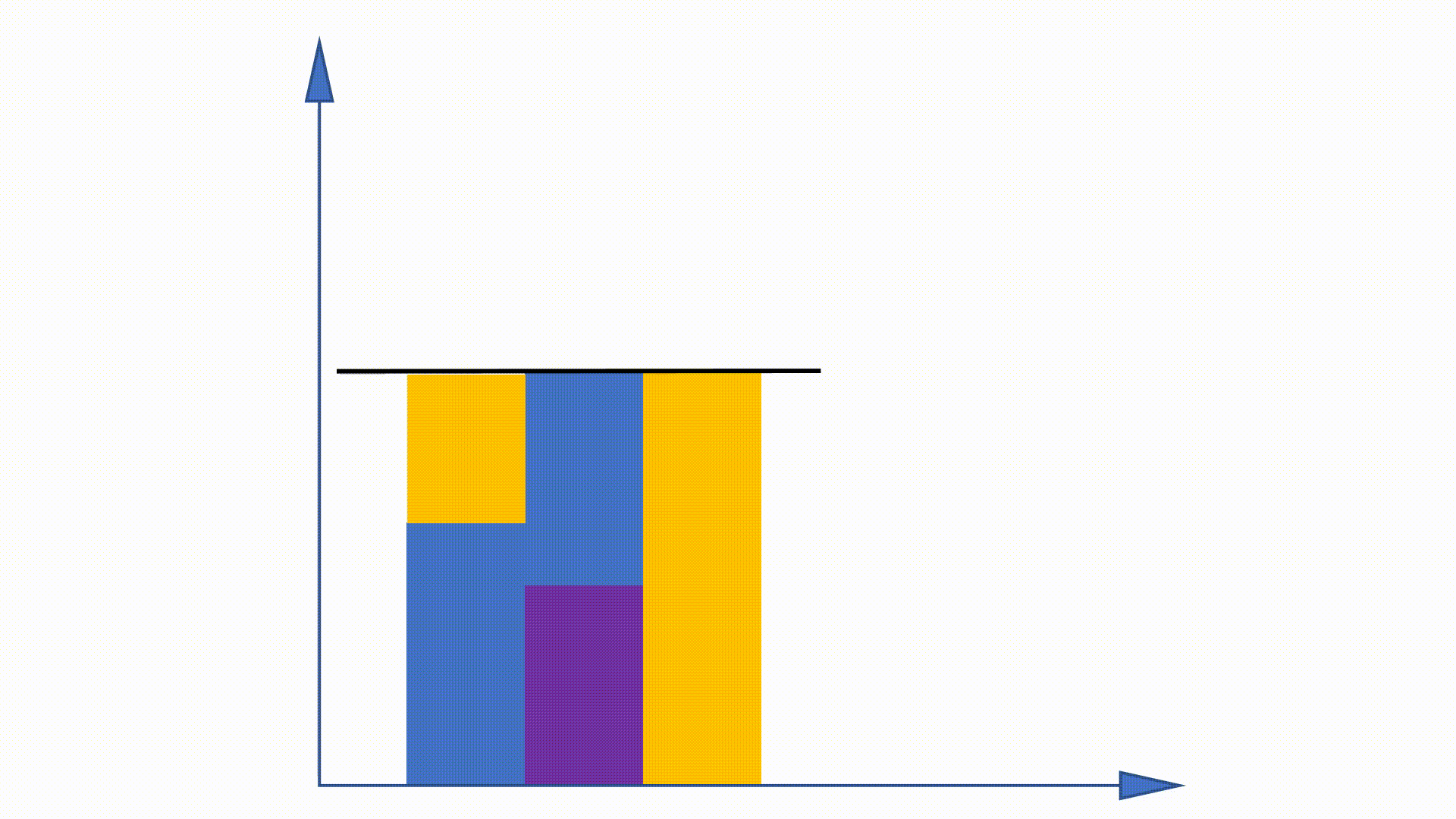
通过构建数据结构,别名方法可以降低来自
参考:
别名方法:
https://hips.seas.harvard.edu/blog/2013/03/03/the-alias-method-efficited-smpling-with-many-discrete-utcomes/
传统的NCE仅在线性(软马克斯)层上执行对比度,也就是说,给出了线性层的输入
在此代码库中,我使用名为Full-NCE(F-NCE)的仿制品变体来澄清。与正常的NCE不同,F-NCE样品在输入嵌入时的噪音。
参考:
IBM的整个句子语言模型(ICASSP2018)
bi-lstm语言模型,segresslab,sjtu(ICSLP2016?)
常规的NCE需要每个数据令牌不同的噪声样本。这种计算模式并不完全GPU有效,因为它需要批处理的矩阵乘法。一个诀窍是在整个迷你批次上共享噪声样本,从而将稀疏的批处理矩阵乘法转换为更有效的密集矩阵乘法。 TensorFlow已经支持批处理的NCE。
一种更具侵略性的方法是称为自我对比(由我自己命名)。噪音不是从噪声分布中取样,而只是其他训练令牌,而在同一迷你批处理中。
参考:
批处理
https://arxiv.org/pdf/1708.05997.pdf
自我对比:
https://www.isi.edu/natural-language/mt/simple-fast-noise.pdf
有一个示例说明了如何在example文件夹中使用NCE模块。此示例是从Pytorch/示例存储库分配的。
请首先运行pip install -r requirements以查看您是否具有所需的Python lib。
tqdm在培训期间用于过程栏dill是泡菜更灵活的替代品--nce :是否将NCE用作近似--noise-ratio <50> :每批噪声样本数量,单批令牌之间的噪声在训练速度中共享。--norm-term <9> :恒定归一化项Ln(z)--index-module <linear> :用于NCE模块的索引模块(当前和可用,不支持PPL计算)--train :火车或仅评估现有模型--vocab <None> :如果指定了词汇文件,请使用train.txt中的单词--loss [full, nce, sampled, mix] :选择训练的损失类型之一,将损失转换为full PPL评估。使用线性模块运行NCE标准:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --train使用GRU模块运行NCE标准:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --train --index-module gru运行常规CE标准:
python main.py --cuda --train这是一个表演展示柜。但是,该数据集并未捆绑在此存储库中。该模型接受了串联句子的训练,但是隐藏的状态并未通过批处理传递。 <s>在句子之间插入。该模型分别在<s>填充句子上评估。
通常,接受串联句子训练的模型的性能比在单独句子中训练的模型稍差。但是我们通过减少句子填充操作来节省50%的培训时间。
python main.py --train --batch-size 96 --cuda --loss nce --noise-ratio 500 --nhid 300
--emsize 300 --log-interval 1000 --nlayers 1 --dropout 0 --weight-decay 1e-8
--data data/swb --min-freq 3 --lr 2 --save nce-500-swb --concat得益于Hexlee,Rescore是在SWBD 50张中进行的。
| 培训损失类型 | 评估类型 | ppl | wer |
|---|---|---|---|
| 3Gram | 规范 | ? | 19.4 |
| CE(无concat) | 规范(完整) | 53 | 13.1 |
| CE | 规范(完整) | 55 | 13.3 |
| NCE | 未估计(NCE) | 无效的 | 13.4 |
| NCE | 规范(完整) | 55 | 13.4 |
| 重要性样本 | 规范(完整) | 55 | 13.4 |
| 重要性样本 | 采样(500) | 无效的 | 19.0(比Rescore差得多) |
example/log/ :此脚本的一些日志文件nce/ :NCE模块包装器nce/nce_loss.py :NCE损失nce/alias_multinomial.py :别名方法采样nce/index_linear.py :NCE使用的索引模块,作为正常线性模块的替代品nce/index_gru.py :NCE使用的索引模块,作为整个语言模型模块的替代sample.py线性的简单脚本。example :使用NCE用作损失的单词langauge模型样本。example/vocab.py :词汇对象的包装器example/model.py :所有nn.Module的包装器。example/generic_model.py nce模块的模型包装器example/main.py :入口点example/utils.py :一些用于更好代码结构的UTIT功能此示例在语言建模任务上训练多层LSTM。默认情况下,培训脚本使用提供的PTB数据集。
python main.py --train --cuda --epochs 6 # Train a LSTM on PTB with CUDA如果安装Cudnn在CUDA上运行,该模型将自动使用Cudnn后端。
在训练过程中,如果收到了键盘中断(CTRL-C),则停止训练,并针对测试数据集评估当前模型。
main.py脚本接受以下参数:
optional arguments:
-h, --help show this help message and exit
--data DATA location of the data corpus
--emsize EMSIZE size of word embeddings
--nhid NHID humber of hidden units per layer
--nlayers NLAYERS number of layers
--lr LR initial learning rate
--lr-decay learning rate decay when no progress is observed on validation set
--weight-decay weight decay(L2 normalization)
--clip CLIP gradient clipping
--epochs EPOCHS upper epoch limit
--batch-size N batch size
--dropout DROPOUT dropout applied to layers (0 = no dropout)
--seed SEED random seed
--cuda use CUDA
--log-interval N report interval
--save SAVE path to save the final model
--bptt max length of truncated bptt
--concat use concatenated sentence instead of individual sentence

