Pytorch NCE
More readability
L'estimation contrastive du bruit (NCE) est une méthode d'approximation qui est utilisée pour contourner l'énorme coût de calcul de la grande couche Softmax. L'idée de base est de convertir le problème de prédiction en problème de classification au stade de la formation. Il a été prouvé que ces deux critères convergent vers le même point minimal tant que la distribution du bruit est suffisamment proche d'une vraie.
NCE comble l'écart entre les modèles génératifs et les modèles discriminants, plutôt que de simplement accélérer la couche Softmax. Avec NCE, vous pouvez transformer presque n'importe quoi en postérieur avec moins d'effort (je pense).
Réfs:
NCE:
http://www.cs.helsinki.fi/u/ahyvarin/papers/gutmann10aistats.pdf
Nce sur rnnlm:
https://pdfs.semanticscholar.org/144e/357b1339c27cce7a1e69f0899c21d8140c1f.pdf
Un examen des méthodes d'accélération de Softmax:
http://ruder.io/word-embeddings-softmax/
NCE vs IS (échantillonnage d'importance): NCE est une classification binaire tandis que c'est une sorte de problème de classification multi-classes.
http://demo.clab.cs.cmu.edu/cdyer/nce_notes.pdf
NCE vs Gan (réseau adversaire génératif):
https://arxiv.org/abs/1412.6515
Dans NCE, la distribution de l'unigramme est généralement utilisée pour approximer la distribution du bruit car il est rapide de l'échantillonnage. L'échantillonnage à partir d'un unigramme est égal à l'échantillonnage multinomial, qui est de complexité
Étant donné que la distribution de l'Unigramme peut être obtenue avant la formation et reste inchangée à travers la formation, certains travaux sont proposés pour utiliser cette propriété pour accélérer la procédure d'échantillonnage. La méthode d'alias en fait partie.
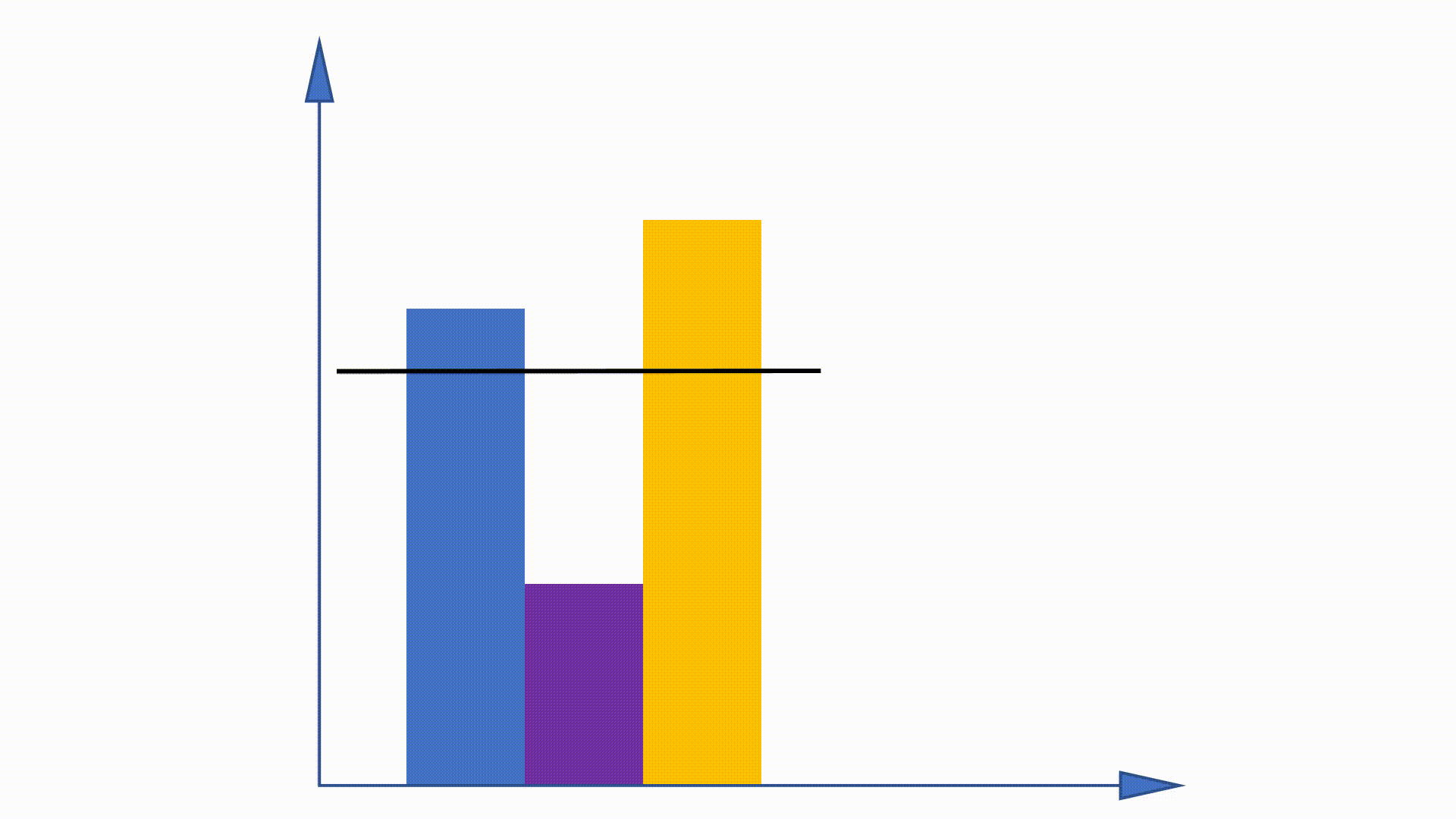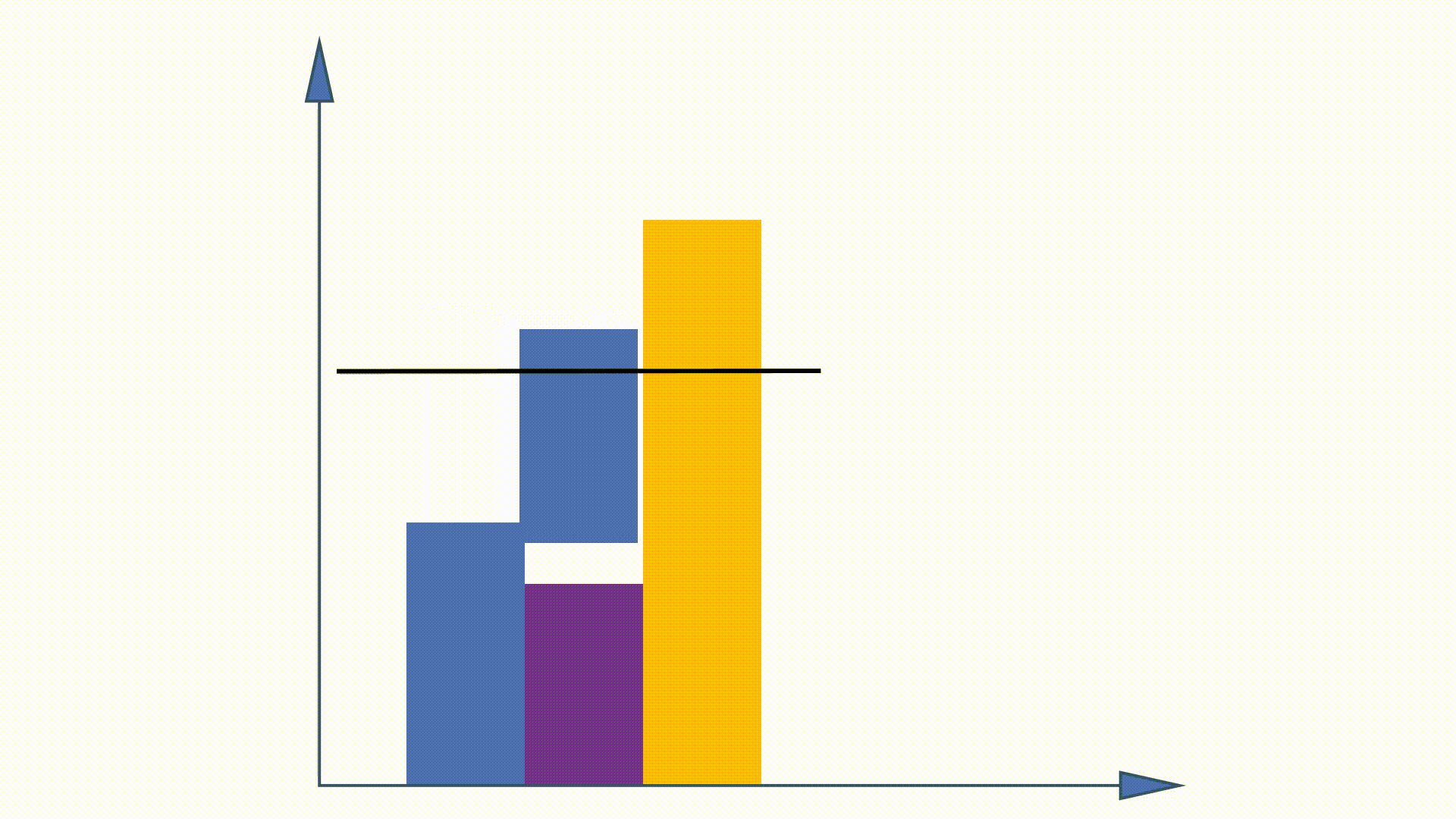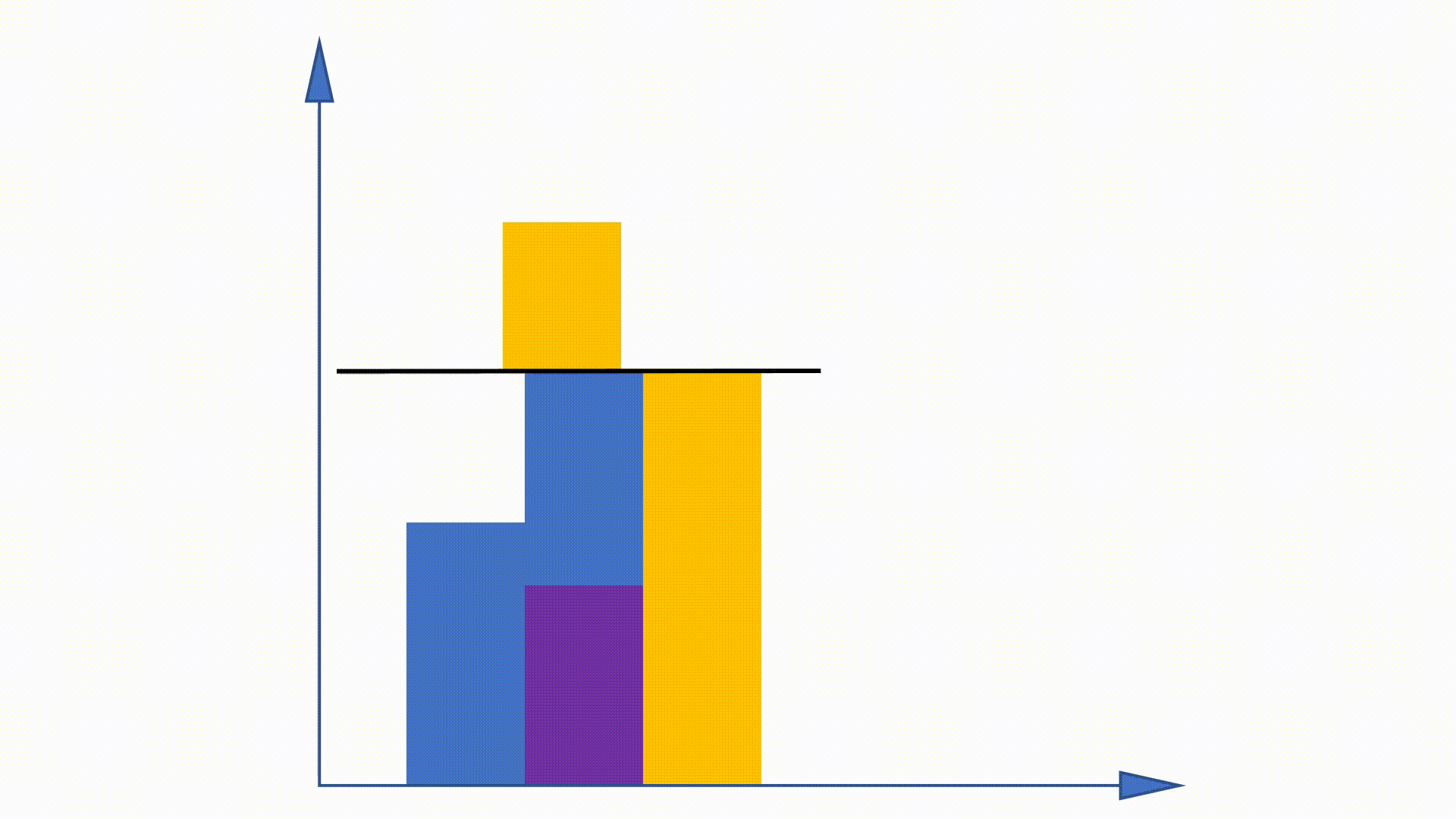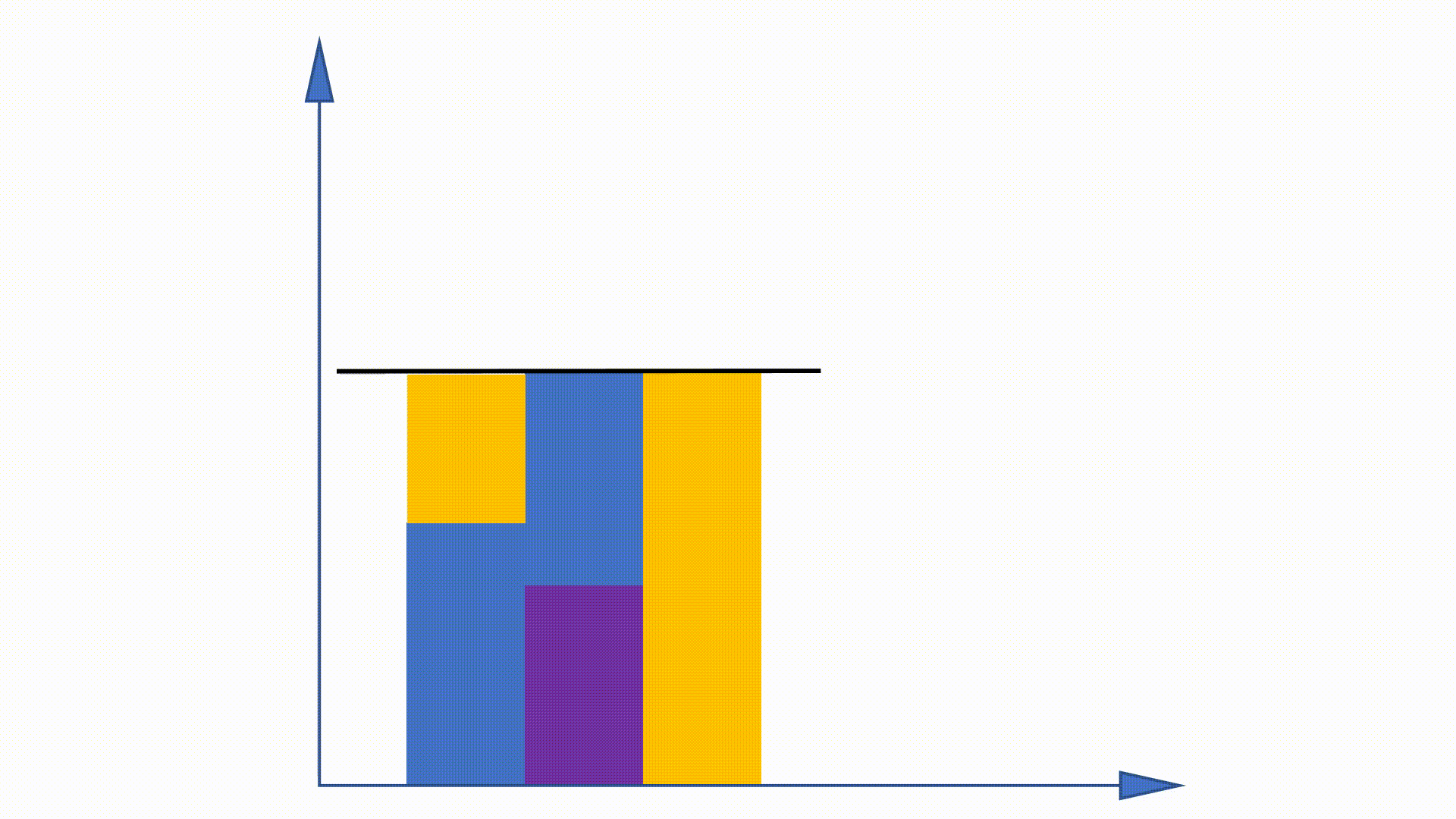
En construisant des structures de données, la méthode d'alias peut réduire la complexité d'échantillonnage de
Réfs:
Méthode d'alias:
https://hips.seas.harvard.edu/blog/2013/03/03/the-alias-method-efesivet-sampling-with-many-discrete-stcomes/
NCE conventionnel effectuer uniquement la couche contrastée sur la couche linéaire (softmax), c'est-à-dire, étant donné une entrée d'une couche linéaire, les sorties du modèle sont
Dans cette base de code, j'utilise une variante de générique nommée Full-NCE (F-NCE) pour clarifier. Contrairement à la NCE normale, F-NCE échantillonne les bruits à l'intégration d'entrée.
Réfs:
Modèle de langage de phrase entier par IBM (ICASSP2018)
Modèle de langue bi-lstm par SpeechLab, SJTU (ICSLP2016?)
Le NCE conventionnel nécessite différents échantillons de bruit par jeton de données. Un tel modèle de calcul n'est pas entièrement économe en GPU car il a besoin d'une multiplication par lots de matrice. Une astuce consiste à partager les échantillons de bruit sur l'ensemble du mini-lots, donc la multiplication par lots clairsemée est convertie en multiplication de matrice dense plus efficace. Le NCE par lots est déjà pris en charge par TensorFlow.
Une approche plus agressive consiste à s'auto-contraster (nommé par moi-même). Au lieu de l'échantillonnage de la distribution du bruit, les bruits sont simplement les autres jetons de formation dans le même mini-lot.
Réf:
NCE par lots
https://arxiv.org/pdf/1708.05997.pdf
Auto-contrastant:
https://www.isi.edu/natural-language/mt/simple-fast-noise.pdf
Il existe un exemple illustrant comment utiliser le module NCE dans example de dossier. Cet exemple est fourchu à partir du repo pytorch / exemples.
Veuillez d'abord exécuter pip install -r requirements pour voir si vous avez la lib Python requis.
tqdm est utilisé pour la barre de processus pendant la formationdill est un remplacement plus flexible pour le cornichon--nce : s'il faut utiliser NCE comme approximation--noise-ratio <50> : nombres d'échantillons de bruit par lot, le bruit est partagé entre les jetons en un seul lot, pour une vitesse d'entraînement.--norm-term <9> : Le terme de normalisation constante Ln(z)--index-module <linear> : module d'index à utiliser pour le module NCE (actuellement et disponible, ne prend pas en charge le calcul de PPL)--train : entraîner ou simplement évaluer le modèle existant--vocab <None> : utilisez le fichier de vocabulaire si spécifié, autrement utilisez les mots dans Train.txt--loss [full, nce, sampled, mix] : Choisissez l'un des types de perte pour la formation, la perte est convertie en full évaluation PPL automatiquement.Exécuter le critère NCE avec module linéaire:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --trainExécuter le critère NCE avec le module GRU:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --train --index-module gruExécuter le critère CE conventionnel:
python main.py --cuda --train C'est une vitrine de performance. L'ensemble de données n'est cependant pas regroupé dans ce repo. Le modèle est formé sur des phrases concaténées, mais les états cachés ne sont pas transmis à travers les lots. Un <s> est inséré entre les phrases. Le modèle est évalué séparément les phrases <s> rembourrées.
Généralement, un modèle formé sur des phrases concaténées fonctionne un peu pire que celle formée sur des phrases séparées. Mais nous économisons 50% du temps de formation en réduisant l'opération de rembourrage de la phrase.
python main.py --train --batch-size 96 --cuda --loss nce --noise-ratio 500 --nhid 300
--emsize 300 --log-interval 1000 --nlayers 1 --dropout 0 --weight-decay 1e-8
--data data/swb --min-freq 3 --lr 2 --save nce-500-swb --concatLe RESCORE est joué sur SWBD 50-Best, grâce à Hexlee.
| Type de perte de formation | Type d'évaluation | Ppl | Nous sommes |
|---|---|---|---|
| 3gram | noré | ?? | 19.4 |
| CE (pas de concat) | Normé (plein) | 53 | 13.1 |
| CE | Normé (plein) | 55 | 13.3 |
| Nce | innové (NCE) | invalide | 13.4 |
| Nce | Normé (plein) | 55 | 13.4 |
| Échantillon d'importance | Normé (plein) | 55 | 13.4 |
| Échantillon d'importance | échantillonné (500) | invalide | 19.0 (pire que W / S RESCORE) |
example/log/ : quelques fichiers journaux de ces scriptsnce/ : l'emballage du module NCEnce/nce_loss.py : la perte de NCEnce/alias_multinomial.py : échantillonnage de méthode d'aliasnce/index_linear.py : un module d'index utilisé par NCE, en remplacement du module linéaire normalnce/index_gru.py : un module d'index utilisé par NCE, en remplacement du module de modèle de langue entiersample.py : un script simple pour NCE Linear.example : un échantillon de modèle de Langauge Word pour utiliser NCE comme perte.example/vocab.py : un wrapper pour un objet de vocabulaireexample/model.py : l'emballage de tous nn.Module s.example/generic_model.py : le modèle de modèle pour le module index_gru nceexample/main.py : point d'entréeexample/utils.py : quelques fonctions utiles pour une meilleure structure de codeCet exemple forme un LSTM multicouche sur une tâche de modélisation de la langue. Par défaut, le script d'entraînement utilise l'ensemble de données PTB, fourni.
python main.py --train --cuda --epochs 6 # Train a LSTM on PTB with CUDALe modèle utilisera automatiquement le backend CUDNN s'il est exécuté sur CUDA avec CUDNN installé.
Pendant la formation, si une interruption de clavier (CTRL-C) est reçue, la formation est arrêtée et le modèle actuel est évalué par rapport à l'ensemble de données de test.
Le script main.py accepte les arguments suivants:
optional arguments:
-h, --help show this help message and exit
--data DATA location of the data corpus
--emsize EMSIZE size of word embeddings
--nhid NHID humber of hidden units per layer
--nlayers NLAYERS number of layers
--lr LR initial learning rate
--lr-decay learning rate decay when no progress is observed on validation set
--weight-decay weight decay(L2 normalization)
--clip CLIP gradient clipping
--epochs EPOCHS upper epoch limit
--batch-size N batch size
--dropout DROPOUT dropout applied to layers (0 = no dropout)
--seed SEED random seed
--cuda use CUDA
--log-interval N report interval
--save SAVE path to save the final model
--bptt max length of truncated bptt
--concat use concatenated sentence instead of individual sentence

