Pytorch NCE
More readability
A estimativa contrastante de ruído (NCE) é um método de aproximação usado para contornar o enorme custo computacional de grande camada de max softmax. A idéia básica é converter o problema de previsão em problema de classificação em estágio de treinamento. Foi provado que esses dois critérios converge para o mesmo ponto mínimo, desde que a distribuição de ruído esteja próxima o suficiente para o real.
A NCE preenche a lacuna entre modelos generativos e modelos discriminativos, em vez de simplesmente acelerar a camada Softmax. Com a NCE, você pode transformar quase tudo em posterior com menos esforço (eu acho).
Refs:
NCE:
http://www.cs.helsinki.fi/u/ahyvarin/papers/gutmann10aistats.pdf
NCE no rnnlm:
https://pdfs.semanticscholar.org/144e/357b1339c27cce7a1e69f0899c21d8140c1f.pdf
Uma revisão dos métodos de aceleração do softmax:
http://ruder.io/word-embeddings-softmax/
NCE vs. é (amostragem de importância): a NCE é uma classificação binária, enquanto o IS é uma espécie de problema de classificação de várias classes.
http://demo.clab.cs.cmu.edu/cdyer/nce_notes.pdf
NCE vs. GAN (rede adversária generativa):
https://arxiv.org/abs/1412.6515
Na NCE, a distribuição dos unigrama geralmente é usada para aproximar a distribuição de ruído, porque é rápido de amostrar. A amostragem de um unigrama é igual à amostragem multinomial, o que é de complexidade
Como a distribuição da Unigram pode ser obtida antes do treinamento e permanece inalterada ao longo do treinamento, alguns trabalhos são propostos para usar essa propriedade para acelerar o procedimento de amostragem. O método de alias é um deles.
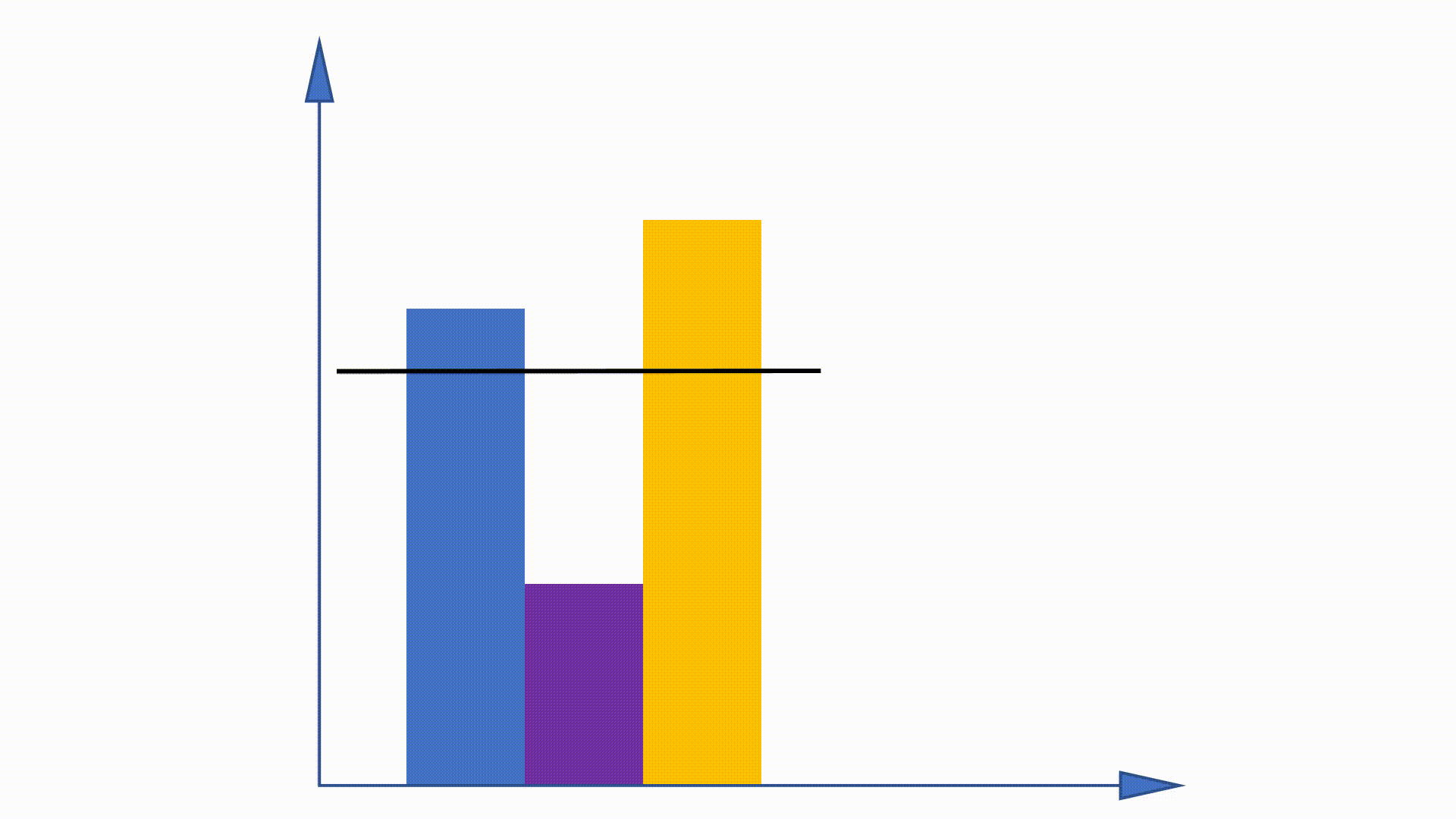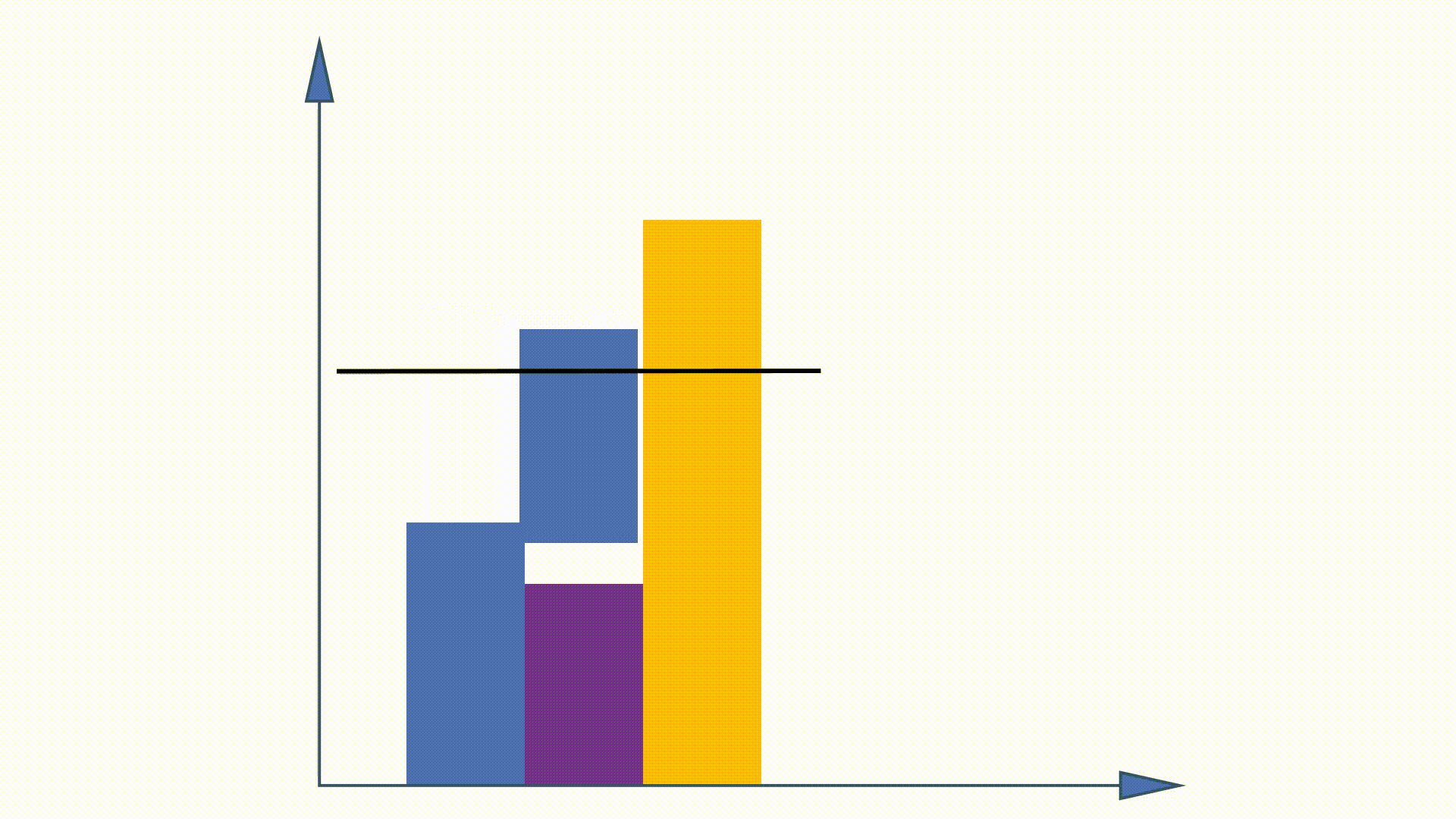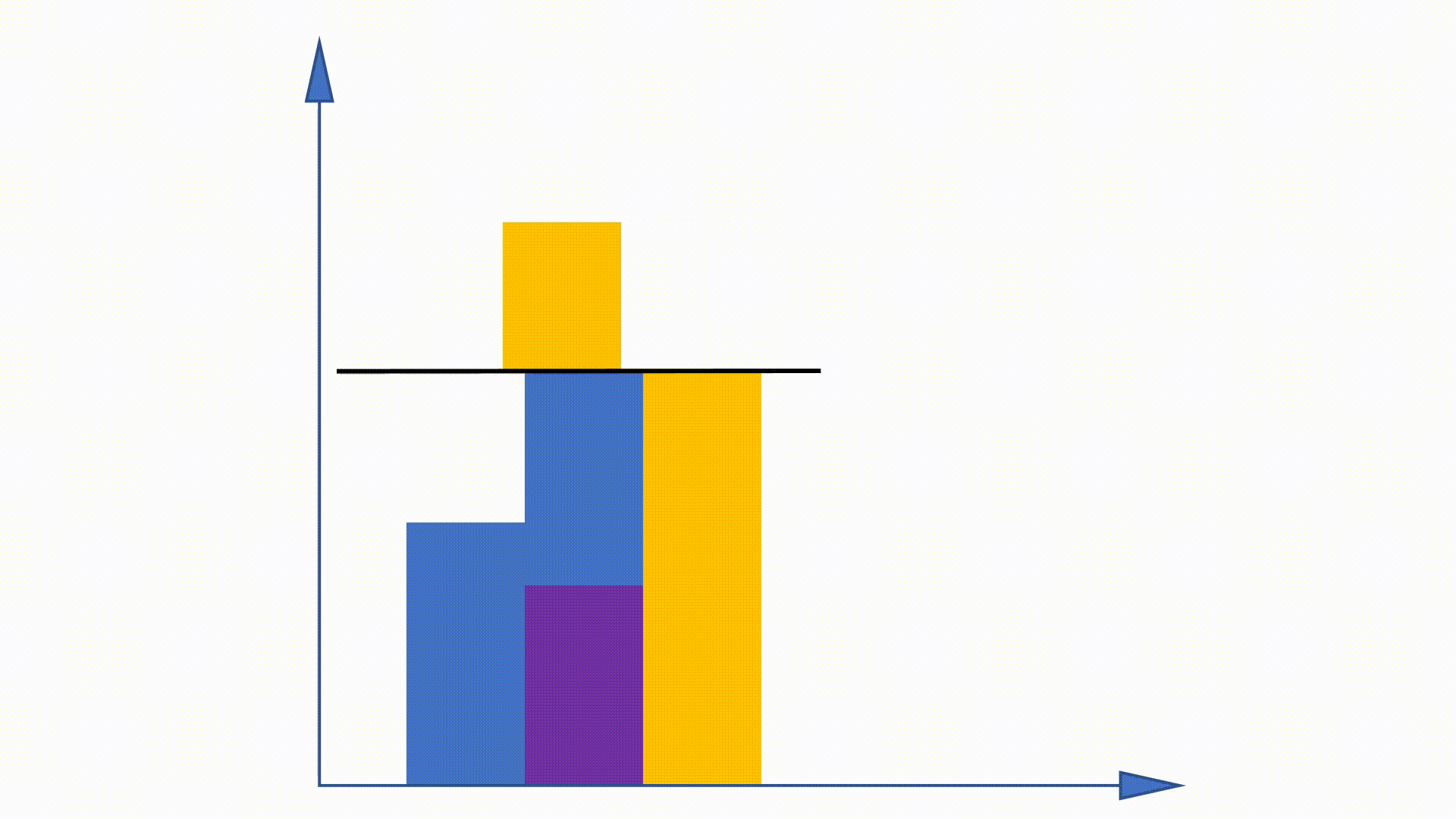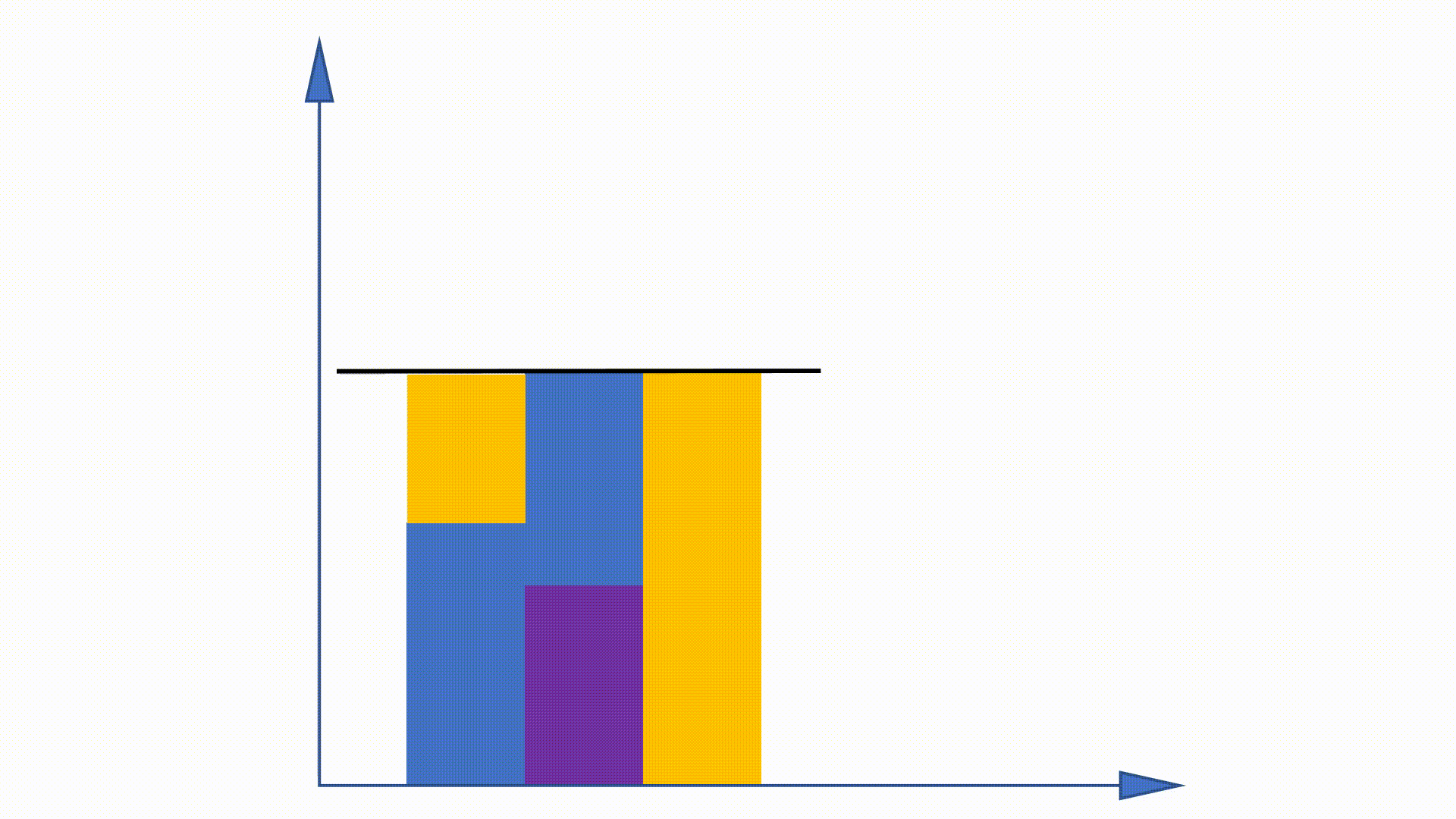
Ao construir estruturas de dados, o método de alias pode reduzir a complexidade de amostragem de
Refs:
Alias Método:
https://hips.seas.harvard.edu/blog/2013/03/03/the-alias-method-e comenda eficientes-
O NCE convencional executa apenas o contraste na camada linear (softmax), ou seja, dada a entrada de uma camada linear, as saídas do modelo são
Nesta base de código, uso uma variante de NCE genérico denominada NCE Full (F-NCE) para esclarecer. Diferentemente da NCE normal, a F-NCE amostra os ruídos na incorporação de entrada.
Refs:
Modelo de linguagem de frase inteira por IBM (ICASSP2018)
Modelo de linguagem BI-LSTM por discurso, SJTU (ICSLP2016?)
A NCE convencional requer diferentes amostras de ruído por token de dados. Esse padrão computacional não é totalmente eficiente em termos de GPU porque precisa de multiplicação de matriz em lote. Um truque é compartilhar as amostras de ruído em todo o mini-lote, assim a multiplicação de matriz em lotes escassa é convertida em multiplicação de matriz densa mais eficiente. O NCE em lote já é suportado pelo TensorFlow.
Uma abordagem mais agressiva é chamado de auto -contraste (nomeado por mim). Em vez de amostrar da distribuição de ruído, os ruídos são simplesmente os outros tokens de treinamento no mesmo mini-lote.
Ref:
NCE em lote
https://arxiv.org/pdf/1708.05997.pdf
auto -contrastante:
https://www.isi.edu/natural-language/mt/simple-fast-noise.pdf
Há um exemplo ilustrando como usar o módulo NCE na pasta example . Este exemplo é bifurcado no repo Pytorch/Exemplos.
Execute pip install -r requirements primeiro para ver se você possui o Python Lib necessário.
tqdm é usado para a barra de processo durante o treinamentodill é uma substituição mais flexível para o picles--nce : se deve usar o NCE como aproximação--noise-ratio <50> : Números de amostras de ruído por lote, o ruído é compartilhado entre os tokens em um único lote, para velocidade de treinamento.--norm-term <9> : o termo de normalização constante Ln(z)--index-module <linear> : módulo de índice a ser usado para o módulo NCE (atualmente e disponível, não suporta o cálculo de ppl)--train : treinar ou apenas avaliar o modelo existente--vocab <None>--loss [full, nce, sampled, mix] : Escolha um dos tipos de perda para treinamento, a perda é convertida para a avaliação full para PPL automaticamente.Execute o critério NCE com módulo linear:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --trainExecute o critério NCE com o módulo GRU:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --train --index-module gruExecute critério de CE convencional:
python main.py --cuda --train É uma vitrine de desempenho. O conjunto de dados não é incluído neste repositório. O modelo é treinado em frases concatenadas, mas os estados ocultos não são passados pelos lotes. Um <s> é inserido entre as frases. O modelo é avaliado em frases <s> separadamente.
Geralmente, um modelo treinado em frases concatenadas tem um desempenho um pouco pior do que o treinado em frases separadas. Mas economizamos 50% do tempo de treinamento, reduzindo a operação de preenchimento de frases.
python main.py --train --batch-size 96 --cuda --loss nce --noise-ratio 500 --nhid 300
--emsize 300 --log-interval 1000 --nlayers 1 --dropout 0 --weight-decay 1e-8
--data data/swb --min-freq 3 --lr 2 --save nce-500-swb --concatO resgate é realizado no SWBD 50 Best, graças a Hexlee.
| Tipo de perda de treinamento | Tipo de avaliação | Ppl | Wer |
|---|---|---|---|
| 3Gram | Normado | ? | 19.4 |
| CE (sem concat) | Normado (completo) | 53 | 13.1 |
| CE | Normado (completo) | 55 | 13.3 |
| NCE | não formado (NCE) | inválido | 13.4 |
| NCE | Normado (completo) | 55 | 13.4 |
| amostra de importância | Normado (completo) | 55 | 13.4 |
| amostra de importância | amostrado (500) | inválido | 19.0 (pior do que sem resgate) |
example/log/ : alguns arquivos de log desses scriptsnce/ : The NCE Module Wrappernce/nce_loss.py : A perda da NCEnce/alias_multinomial.py : Amostragem de método de aliasnce/index_linear.py : um módulo de índice usado pelo NCE, como substituto para o módulo linear normalnce/index_gru.py : um módulo de índice usado pelo NCE, como substituto para todo o módulo de modelo de idiomasample.py : Um script simples para NCE Linear.example : uma amostra de modelo de Word Langauge para usar o NCE como perda.example/vocab.py : um invólucro para objeto de vocabulárioexample/model.py : o invólucro de todos nn.Module s.example/generic_model.py : o wrapper modelo para módulo Index_GRU NCEexample/main.py : ponto de entradaexample/utils.py : algumas funções utilizadas para melhor estrutura de códigoEste exemplo treina um LSTM de várias camadas em uma tarefa de modelagem de idiomas. Por padrão, o script de treinamento usa o conjunto de dados PTB, fornecido.
python main.py --train --cuda --epochs 6 # Train a LSTM on PTB with CUDAO modelo usará automaticamente o back -end do CUDNN se executado no CUDA com o CUDNN instalado.
Durante o treinamento, se uma interrupção do teclado (CTRL-C) for recebida, o treinamento será interrompido e o modelo atual será avaliado no conjunto de dados de teste.
O script main.py aceita os seguintes argumentos:
optional arguments:
-h, --help show this help message and exit
--data DATA location of the data corpus
--emsize EMSIZE size of word embeddings
--nhid NHID humber of hidden units per layer
--nlayers NLAYERS number of layers
--lr LR initial learning rate
--lr-decay learning rate decay when no progress is observed on validation set
--weight-decay weight decay(L2 normalization)
--clip CLIP gradient clipping
--epochs EPOCHS upper epoch limit
--batch-size N batch size
--dropout DROPOUT dropout applied to layers (0 = no dropout)
--seed SEED random seed
--cuda use CUDA
--log-interval N report interval
--save SAVE path to save the final model
--bptt max length of truncated bptt
--concat use concatenated sentence instead of individual sentence

