Pytorch NCE
More readability
Rauschenkontrastive Schätzung (NCE) ist eine Annäherungsmethode, mit der die enormen Rechenkosten einer großen Softmax -Schicht umgeht. Die Grundidee besteht darin, das Vorhersageproblem in ein Klassifizierungsproblem in der Trainingsphase umzuwandeln. Es wurde nachgewiesen, dass diese beiden Kriterien zu dem gleichen minimalen Punkt konvergieren, solange die Rauschverteilung nahe genug ist.
NCE überbrückt die Lücke zwischen generativen Modellen und diskriminierenden Modellen, anstatt einfach die Softmax -Schicht zu beschleunigen. Mit NCE können Sie fast alles in hintere Anstrengungen verwandeln (denke ich).
Refs:
NCE:
http://www.cs.helsinki.fi/u/ahyvarin/papers/gutmann10aistats.pdf
NCE auf RNNLM:
https://pdfs.semanticscholar.org/144e/357b1339c27cCE7A1E69F0899c21d8140c1f.pdf
Eine Überprüfung von Softmax -Geschwindigkeitsmethoden:
http://ruder.io/word-embeding-softmax/
NCE vs. IS (Wichtigkeitstichprobe): NCE ist eine binäre Klassifizierung, während IS eine Art Multi-Klasse-Klassifizierungsproblem ist.
http://demo.clab.cs.cmu.edu/cdyer/nce_notes.pdf
NCE vs. Gan (generatives kontroverses Netzwerk):
https://arxiv.org/abs/1412.6515
In der NCE wird die Unigram -Verteilung normalerweise verwendet, um die Rauschverteilung zu approximieren, da es schnell probiert. Die Probenahme aus einem Unigramm entspricht einer multinomialen Stichprobe, was von Komplexität ist
Da die Unigram -Verteilung vor dem Training erhalten werden kann und im gesamten Training unverändert bleibt, werden einige Arbeiten vorgeschlagen, um diese Eigenschaft zu nutzen, um das Stichprobenverfahren zu beschleunigen. Alias -Methode ist eine von ihnen.
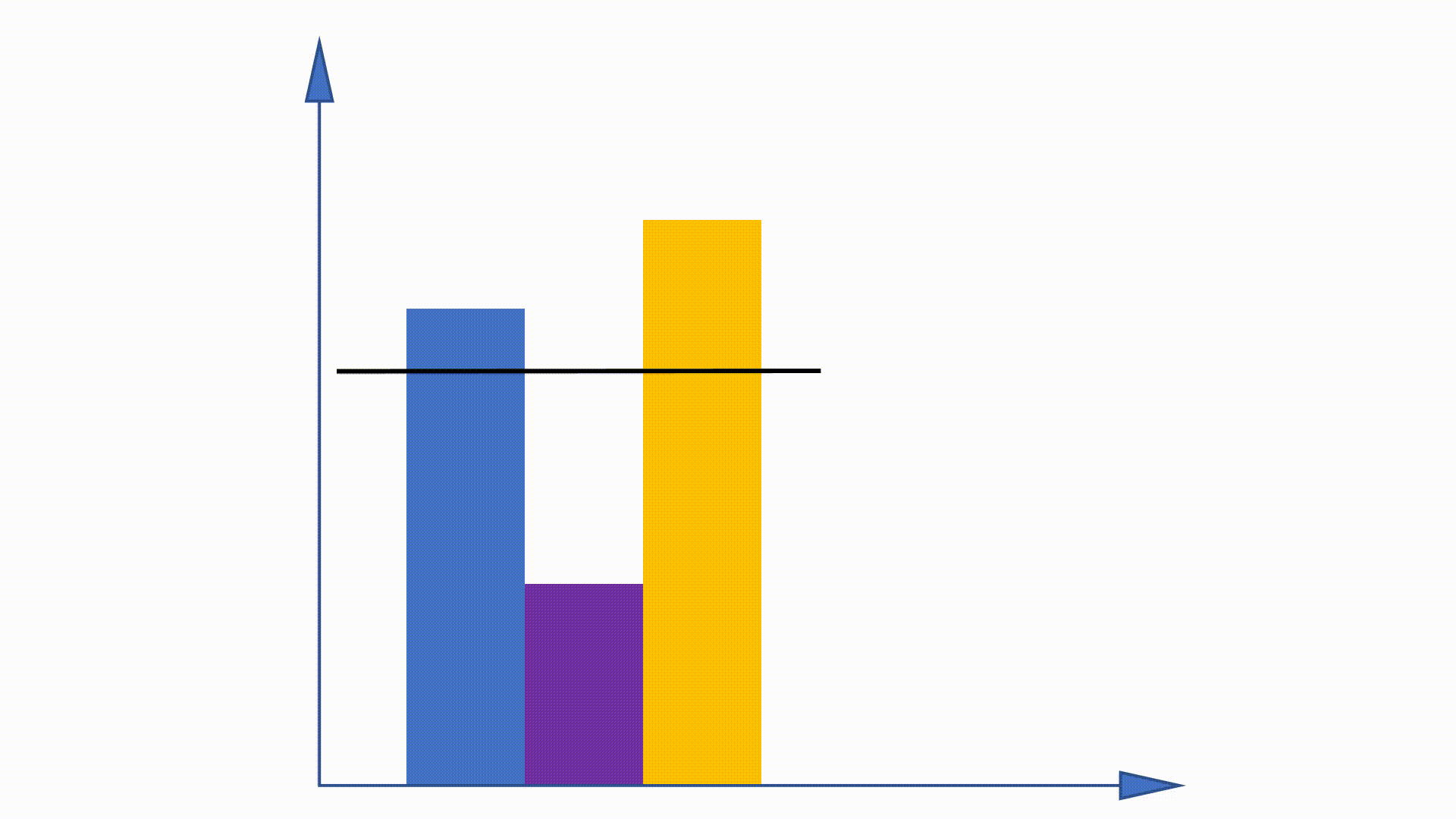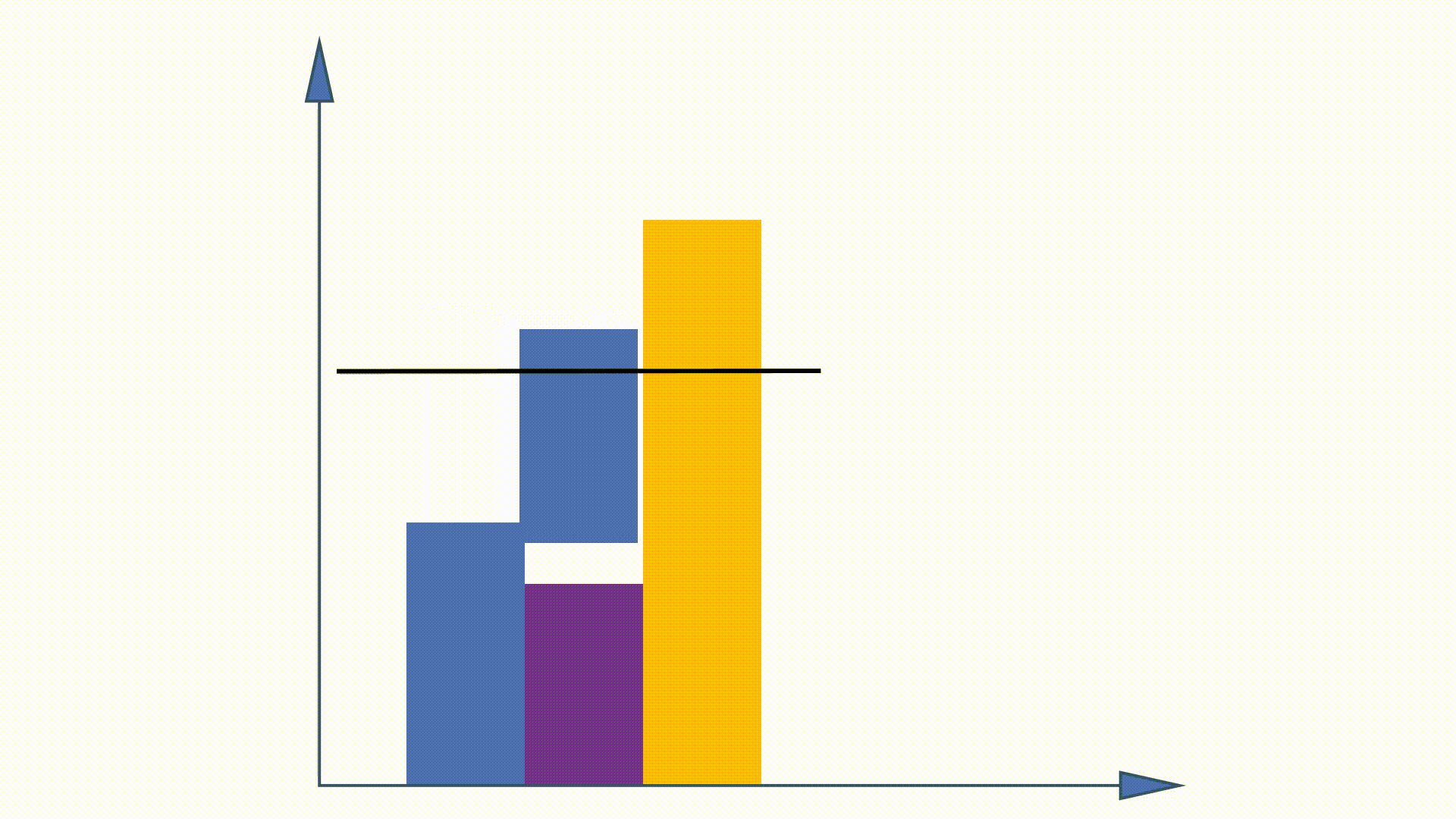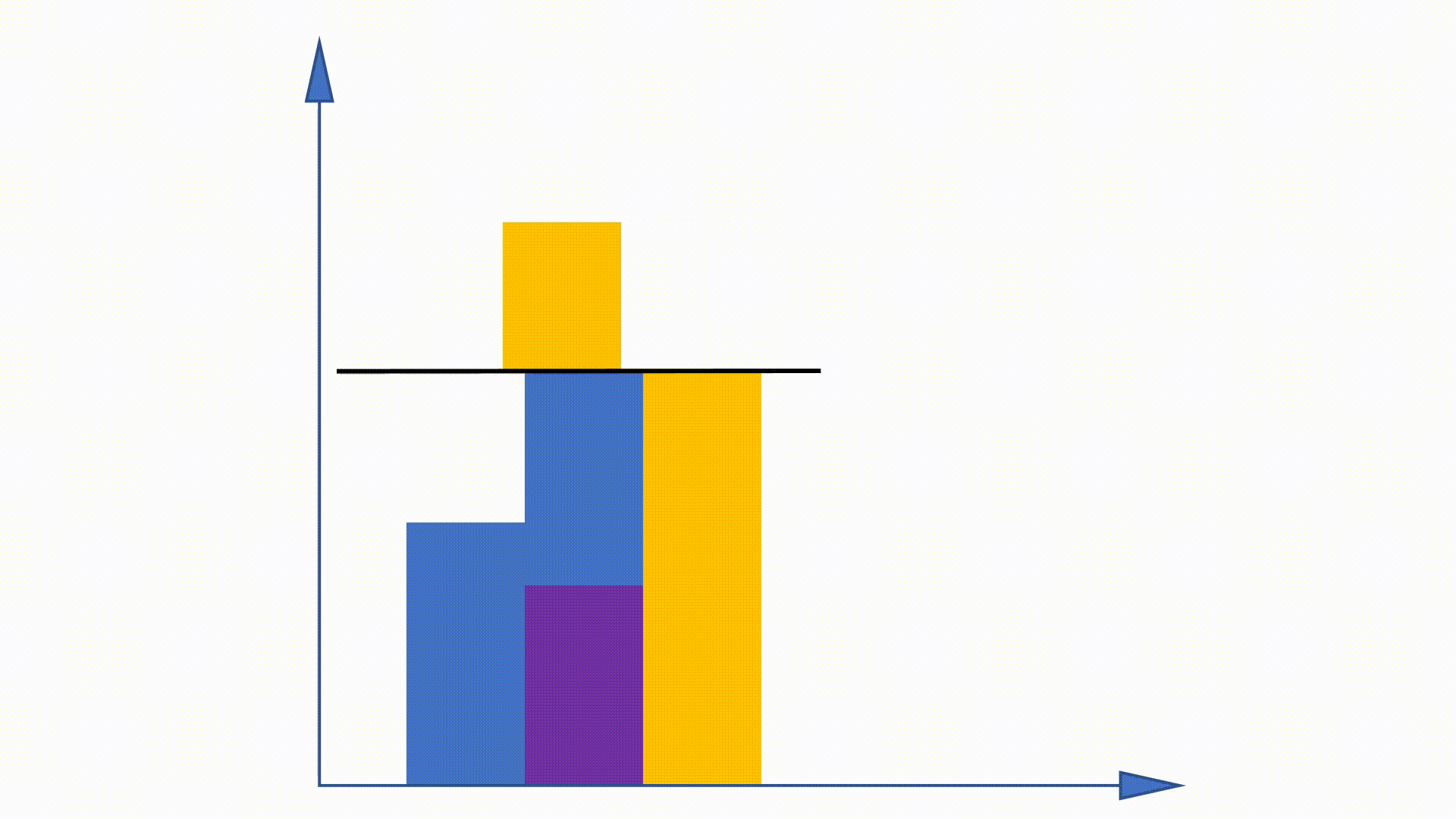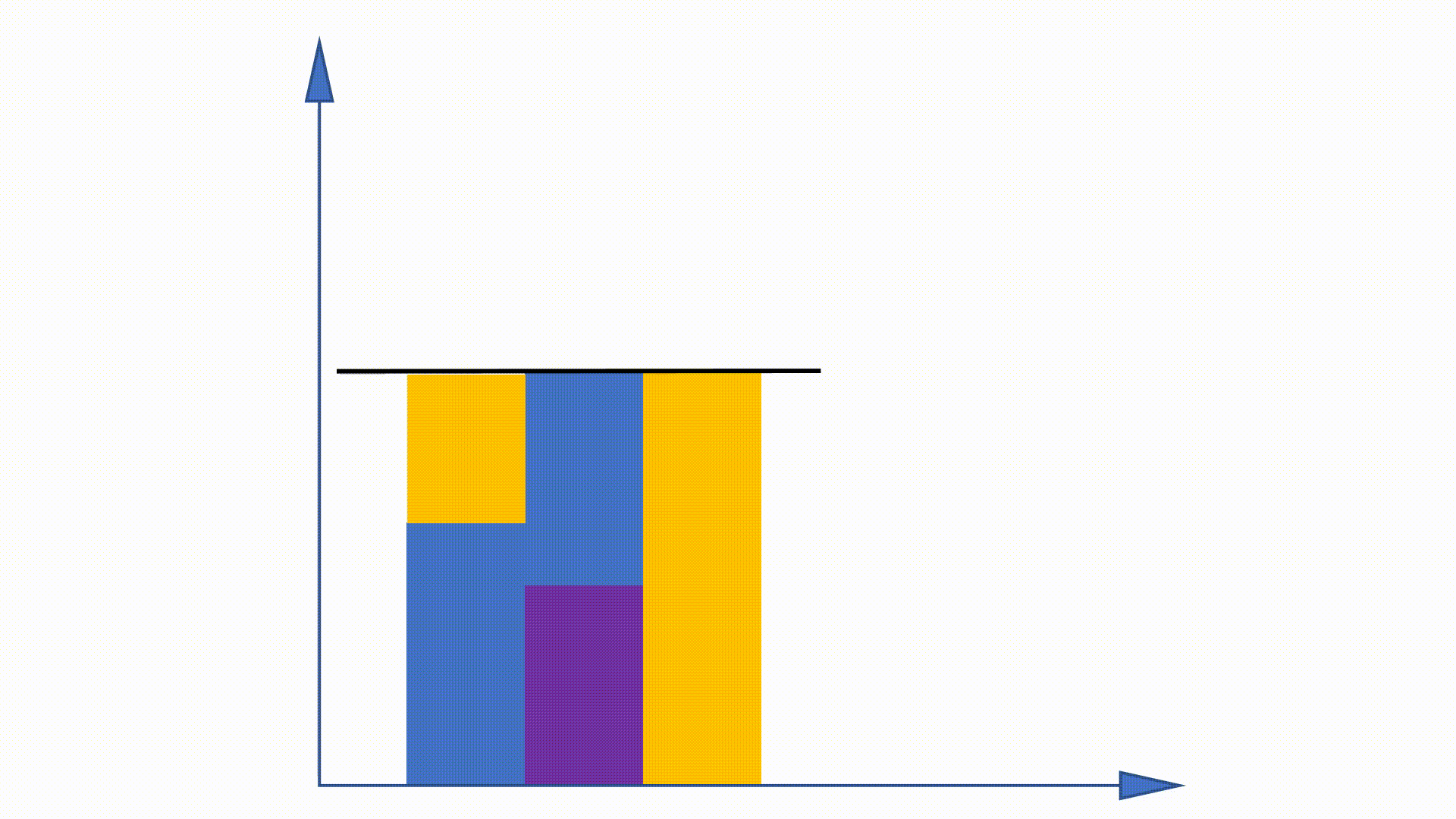
Durch die Erstellung von Datenstrukturen kann die Alias -Methode die Probenahmekomplexität aus verringern
Refs:
Alias -Methode:
https://hips.seas.harvard.edu/blog/2013/03/03/the-alias-method-effiction-sampling-with-many-discrete-outcomes/
Die herkömmliche NCE führt nur den Kontrast auf der linearen Schicht (Softmax) durch, dh bei einem Eingang einer linearen Schicht sind die Modellausgänge
In dieser Codebasis verwende ich eine Variante von generischen NCE namens Full-NCE (F-NCE), um zu klären. Im Gegensatz zu normalem NCE probiert F-NCE die Geräusche bei der Einbettung der Eingabe ab.
Refs:
Ganzes Satzsprachmodell von IBM (ICASSP2018)
BI-LSTM-Sprachmodell von Speechlab, SJtu (ICLP2016?)
Das herkömmliche NCE erfordert unterschiedliche Rauschproben pro Daten -Token. Ein solches Rechenmuster ist nicht vollständig gpueffizient, da es eine matrix-matrix-multiplikation benötigt. Ein Trick besteht darin, die Rauschproben über den gesamten Mini-Batch zu teilen, wodurch eine sparsame matrix-Multiplikation in eine effizientere denne Matrixmultiplikation umgewandelt wird. Der Charge NCE wird bereits von TensorFlow unterstützt.
Ein aggressiverer Ansatz ist, sich selbst kontrastierend zu bezeichnen (von mir genannt). Anstatt von der Rauschverteilung zu proben, sind die Geräusche einfach die anderen Trainingstoken innerhalb derselben Mini-Batch.
Ref:
Batched NCE
https://arxiv.org/pdf/1708.05997.pdf
Selbstkontrastierend:
https://www.isi.edu/natural-language/mt/simple-fast-noise.pdf
Es gibt ein Beispiel, das zeigt, wie das NCE -Modul im example verwendet wird. Dieses Beispiel wird aus dem Pytorch/Beispiele -Repo gegabelt.
Bitte führen Sie pip install -r requirements zuerst aus, um festzustellen, ob Sie die erforderliche Python Lib haben.
tqdm wird während des Trainings für die Prozessleiste verwendetdill ist ein flexiblerer Ersatz für die Gurke--nce : Ob NCE als Annäherung verwendet werden soll--noise-ratio <50> : Anzahl der Geräuschproben pro Charge, das Rauschen wird für die Trainingsgeschwindigkeit unter den Token in einer einzigen Stapel geteilt.--norm-term <9> : Der Konstante Normalisierungsbegriff Ln(z)--index-module <linear> : Indexmodul für das NCE-Modul (derzeit verfügbar, unterstützt nicht die PPL-Berechnung)--train : trainieren oder nur bewerten das bestehende Modell--vocab <None> : Verwenden Sie die Wortschatzdatei, falls angegeben, andernfalls verwenden Sie die Wörter in Train.txt--loss [full, nce, sampled, mix] : Wählen Sie einen der Verlusttypen für das Training. Der Verlust wird für die PPL-Bewertung automatisch in die full PPL-Bewertung umgewandelt.Führen Sie das NCE -Kriterium mit linearem Modul aus:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --trainFühren Sie das NCE -Kriterium mit GRU -Modul aus:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --train --index-module gruFühren Sie das konventionelle CE -Kriterium aus:
python main.py --cuda --train Es ist ein Performance -Showcase. Der Datensatz ist in diesem Repo jedoch nicht gebündelt. Das Modell wird auf verketteten Sätzen geschult, aber die versteckten Zustände werden nicht über Chargen weitergegeben. Ein <s> wird zwischen Sätzen eingefügt. Das Modell wird separat auf <s> gepolsterten Sätzen bewertet.
Im Allgemeinen ist ein Modell, das auf verketteten Sätzen trainiert wurde, etwas schlechter als das, das auf getrennten Sätzen trainiert wurde. Wir sparen jedoch 50% der Schulungszeit, indem wir den Satzpolsterbetrieb verkürzt.
python main.py --train --batch-size 96 --cuda --loss nce --noise-ratio 500 --nhid 300
--emsize 300 --log-interval 1000 --nlayers 1 --dropout 0 --weight-decay 1e-8
--data data/swb --min-freq 3 --lr 2 --save nce-500-swb --concatDie Rescore wird dank Hexlee auf SWBD 50-Beste durchgeführt.
| Trainingsverlusttyp | Bewertungstyp | Ppl | Wer |
|---|---|---|---|
| 3gramm | normiert | ? | 19.4 |
| CE (keine concat) | normiert (voll) | 53 | 13.1 |
| Ce | normiert (voll) | 55 | 13.3 |
| Nce | ungebildet (NCE) | ungültig | 13.4 |
| Nce | normiert (voll) | 55 | 13.4 |
| Wichtiges Beispiel | normiert (voll) | 55 | 13.4 |
| Wichtiges Beispiel | abgetastet (500) | ungültig | 19.0 (schlechter als ohne Errde) |
example/log/ : Einige Protokolldateien dieser Skriptsnce/ : Die NCE -Modulverpackungnce/nce_loss.py : Der NCE -Verlustnce/alias_multinomial.py : Alias -Methode -Abtastungnce/index_linear.py : Ein von NCE verwendetes Indexmodul als Ersatz für das normale lineare Modulnce/index_gru.py : Ein von NCE verwendetes Indexmodul als Ersatz für das gesamte Sprachmodellmodulsample.py : Ein einfaches Skript für NCE -Linear.example : Ein Wort Langauge Model -Beispiel, um NCE als Verlust zu verwenden.example/vocab.py : Ein Wrapper für das Vokabularobjektexample/model.py : Der Wrapper aller nn.Module s.example/generic_model.py : Der Modellverpackung für das Index_Gru -NCE -Modulexample/main.py : Einstiegspunktexample/utils.py : Einige Util -Funktionen für eine bessere CodestrukturIn diesem Beispiel schult ein mehrschichtiger LSTM in einer Sprachmodellierungsaufgabe. Standardmäßig verwendet das Trainingsskript den bereitgestellten PTB -Datensatz.
python main.py --train --cuda --epochs 6 # Train a LSTM on PTB with CUDADas Modell verwendet automatisch das Cudnn -Backend, wenn sie auf CUDA mit installiertem Cudnn ausgeführt werden.
Während des Trainings wird ein Tastaturinterrupt (STRG-C) eingehalten, das Training gestoppt und das aktuelle Modell anhand des Testdatensatzes bewertet.
Das Skript main.py akzeptiert die folgenden Argumente:
optional arguments:
-h, --help show this help message and exit
--data DATA location of the data corpus
--emsize EMSIZE size of word embeddings
--nhid NHID humber of hidden units per layer
--nlayers NLAYERS number of layers
--lr LR initial learning rate
--lr-decay learning rate decay when no progress is observed on validation set
--weight-decay weight decay(L2 normalization)
--clip CLIP gradient clipping
--epochs EPOCHS upper epoch limit
--batch-size N batch size
--dropout DROPOUT dropout applied to layers (0 = no dropout)
--seed SEED random seed
--cuda use CUDA
--log-interval N report interval
--save SAVE path to save the final model
--bptt max length of truncated bptt
--concat use concatenated sentence instead of individual sentence

