Pytorch NCE
More readability
التقدير المتناقض للضوضاء (NCE) هو طريقة تقريب يتم استخدامها للعمل حول التكلفة الحسابية الضخمة لطبقة softmax الكبيرة. الفكرة الأساسية هي تحويل مشكلة التنبؤ إلى مشكلة في التصنيف في مرحلة التدريب. لقد ثبت أن هذين المعيرين يتقاربان إلى نفس النقطة الدنيا طالما أن توزيع الضوضاء قريب بما يكفي.
NCE يسد الفجوة بين النماذج التوليدية والنماذج التمييزية ، بدلاً من مجرد تسريع طبقة SoftMax. مع NCE ، يمكنك تحويل أي شيء تقريبًا إلى خلفي مع جهد أقل (على ما أظن).
الحكام:
NCE:
http://www.cs.helsinki.fi/u/ahyvarin/papers/gutmann10aistats.pdf
NCE على RNNLM:
https://pdfs.semanticscholar.org/144e/357b1339c27cce7a1e69f0899c21d8140c1f.pdf
مراجعة طرق تسريع SoftMax:
http://ruder.io/word-embeddings-softmax/
NCE VS. IS (أخذ عينات من الأهمية): NCE هو تصنيف ثنائي بينما هو نوع من مشكلة تصنيف الطبقة المتعددة.
http://demo.clab.cs.cmu.edu/cdyer/nce_notes.pdf
NCE مقابل GAN (شبكة الخصومة التوليدية):
https://arxiv.org/abs/1412.6515
في NCE ، عادةً ما يتم استخدام توزيع Unigram لتقريب توزيع الضوضاء لأنه سريع العينة من. إن أخذ العينات من unigram يساوي أخذ العينات متعددة الحدود ، وهو أمر تعقيد
نظرًا لأنه يمكن الحصول على توزيع Unigram قبل التدريب ولا يزال دون تغيير عبر التدريب ، يُقترح بعض الأعمال للاستفادة من هذه الخاصية لتسريع إجراء أخذ العينات. طريقة الاسم المستعار هي واحدة منهم.
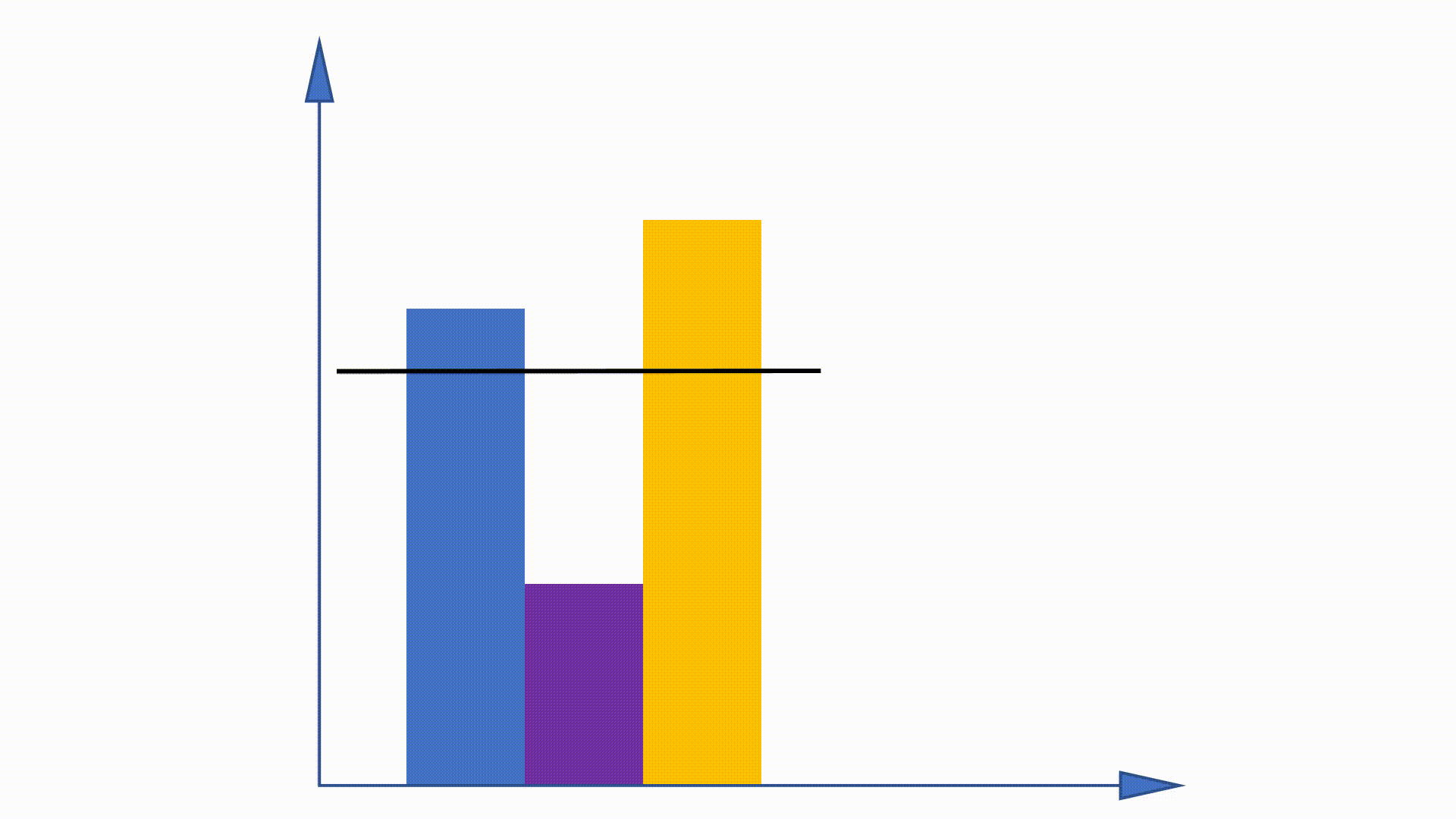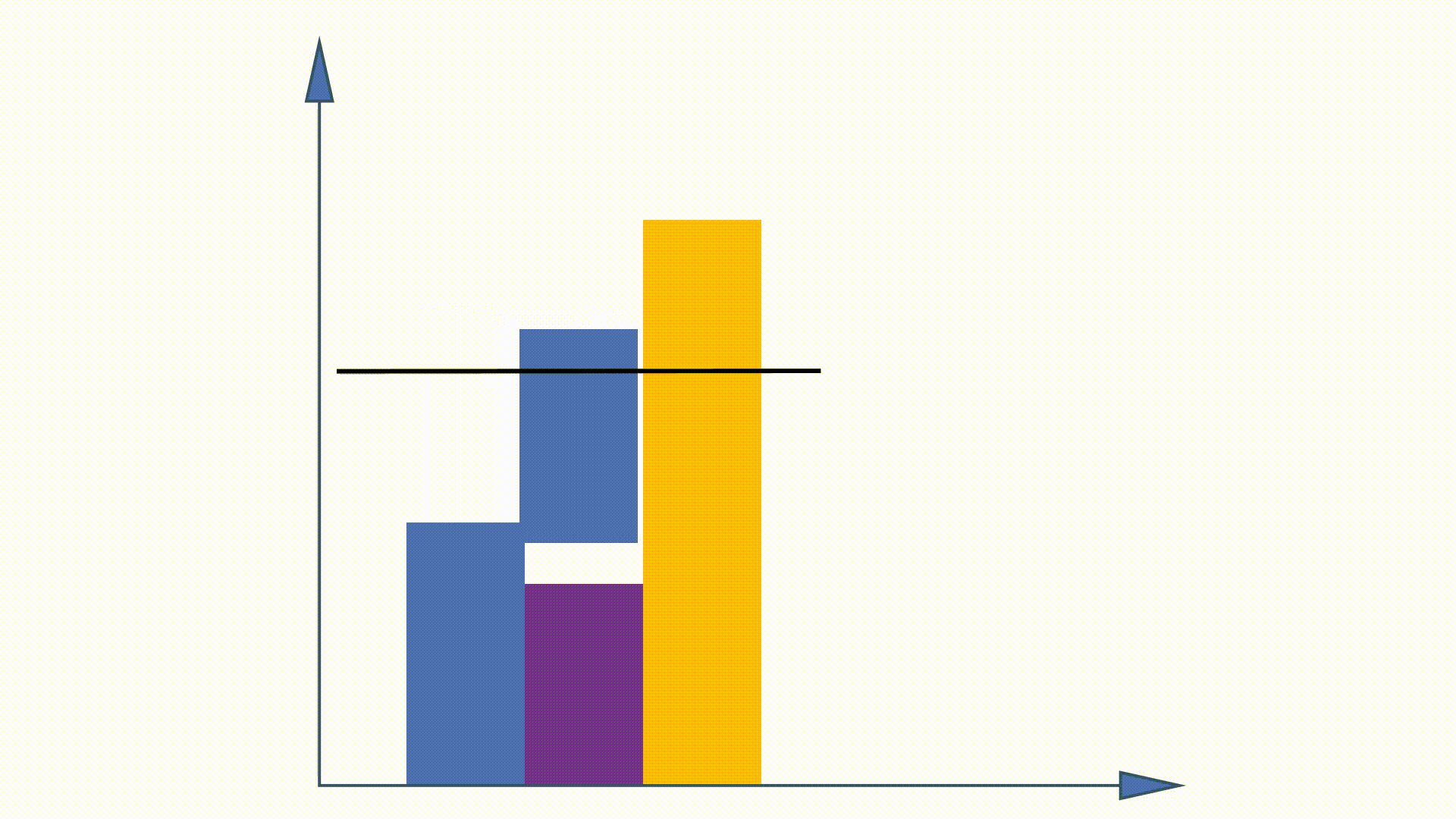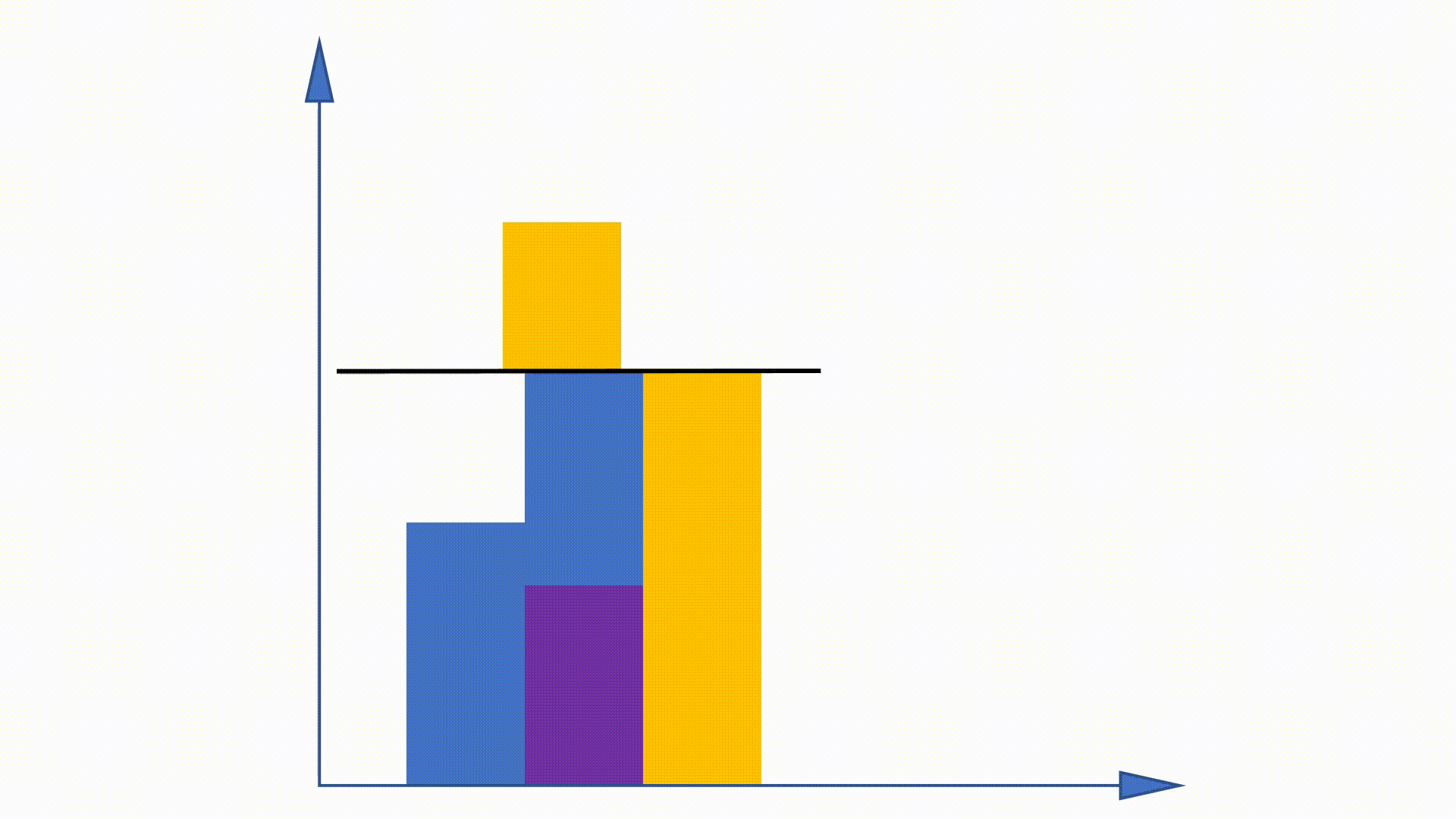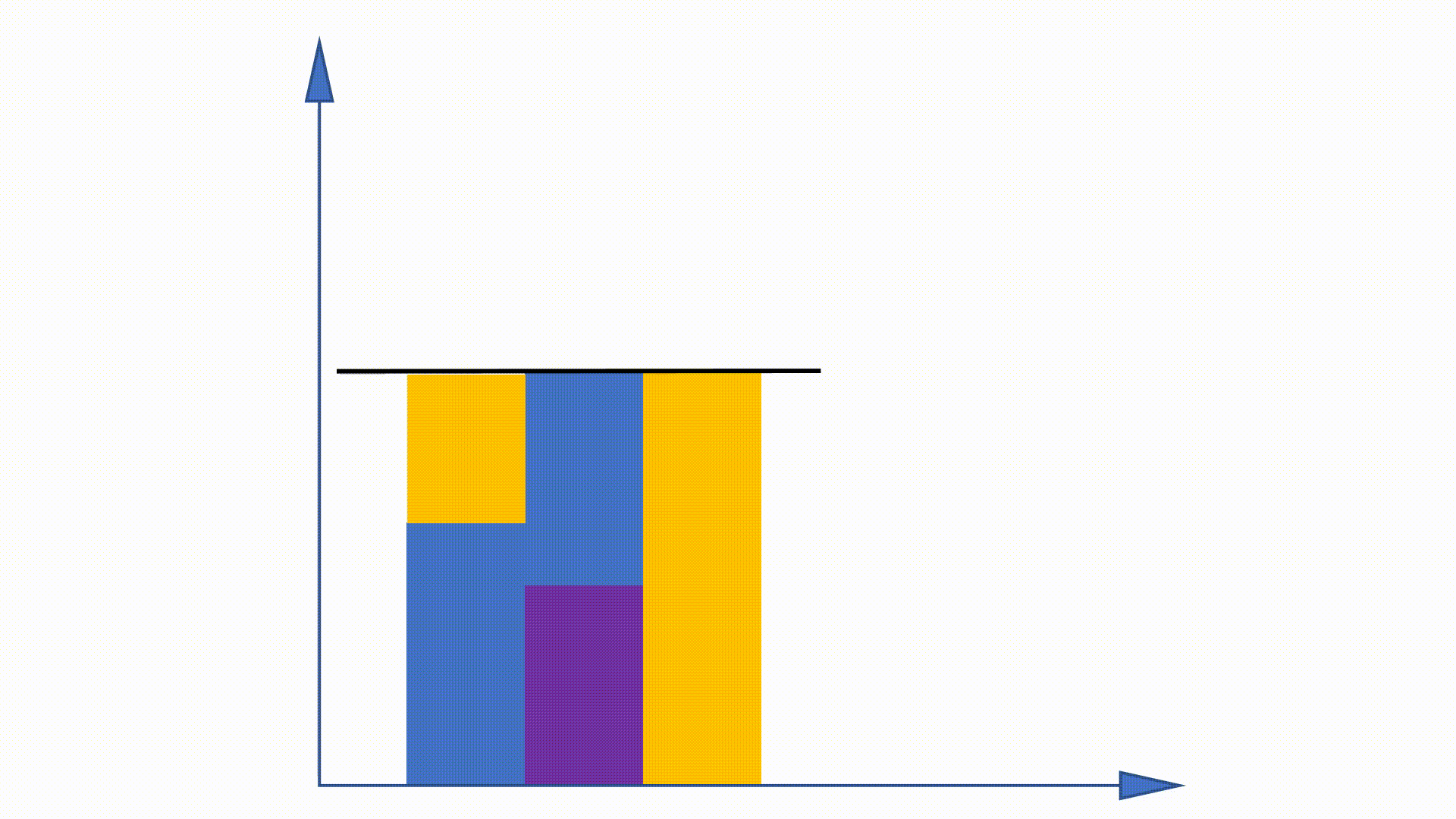
من خلال بناء هياكل البيانات ، يمكن أن تقلل طريقة الاسم المستعار من تعقيد أخذ العينات من
الحكام:
طريقة الاسم المستعار:
https://hips.seas.harvard.edu/blog/2013/03/03/The-Alias-Method-
NCE التقليدية فقط تؤدي التباين على طبقة خطية (softmax) ، أي ، بالنظر إلى إدخال طبقة خطية ، مخرجات النموذج هي
في قاعدة الرمز هذه ، أستخدم متغيرًا من NCE عام اسمه NCE (F-NCE) للتوضيح. على عكس NCE العادي ، فإن F-NCE عينات الضوضاء في تضمين المدخلات.
الحكام:
نموذج لغة الجملة بأكمله من قبل IBM (ICASSP2018)
نموذج لغة BI-LSTM بواسطة PleaseLab ، SJTU (ICSLP2016؟)
يتطلب NCE التقليدية عينات ضوضاء مختلفة لكل رمز بيانات. مثل هذا النمط الحسابي ليس فعالًا تمامًا في GPU لأنه يحتاج إلى مضاعفة مصفوفة مزجدة. تتمثل الحيلة في مشاركة عينات الضوضاء عبر الدفعة المصغرة بأكملها ، وبالتالي يتم تحويل تكاثر المصفوفة المفرطة المفرطة إلى مضاعفة مصفوفة كثيفة أكثر كفاءة. يتم دعم NCE المدمن بالفعل بواسطة TensorFlow.
النهج الأكثر عدوانية هو أن يسمى التباين الذاتي (سميت بنفسي). بدلاً من أخذ العينات من توزيع الضوضاء ، فإن الضوضاء هي ببساطة الرموز الأخرى للتدريب في نفس الدفعة الصغيرة.
المرجع:
NCE المزجج
https://arxiv.org/pdf/1708.05997.pdf
التباين الذاتي:
https://www.isi.edu/natural-language/mt/simple-fast-noise.pdf
هناك مثال يوضح كيفية استخدام وحدة NCE في مجلد example . هذا المثال متشوق من pytorch/أمثلة repo.
يرجى تشغيل pip install -r requirements أولاً لمعرفة ما إذا كان لديك Python Lib المطلوب.
tqdm في شريط العملية أثناء التدريبdill هو بديل أكثر مرونة للمخلل--nce : ما إذا كنت لاستخدام NCE كتقريب--noise-ratio <50> : أعداد من عينات الضوضاء لكل دفعة ، يتم مشاركة الضوضاء بين الرموز في دفعة واحدة ، لسرعة التدريب.--norm-term <9> : مصطلح التطبيع الثابت Ln(z)--index-module <linear> : وحدة الفهرس لاستخدامها في وحدة NCE (حاليًا ومتاحة ، لا تدعم حساب PPL)--train : تدريب أو مجرد تقييم النموذج الحالي--vocab <None> : استخدم ملف المفردات إذا تم تحديده ، وإلا استخدم الكلمات في Train.txt--loss [full, nce, sampled, mix] : اختر واحدة من نوع الخسارة للتدريب ، يتم تحويل الخسارة إلى full لتقييم PPL تلقائيًا.قم بتشغيل معيار NCE مع الوحدة الخطية:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --trainتشغيل معيار NCE مع وحدة GRU:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --train --index-module gruتشغيل معيار CE التقليدي:
python main.py --cuda --train إنه عرض أداء. لم يتم تجميع مجموعة البيانات في هذا الريبو. يتم تدريب النموذج على جمل متسلسلة ، ولكن لا يتم تمرير الحالات المخفية عبر دفعات. يتم إدخال <s> بين الجمل. يتم تقييم النموذج على جمل <s> بشكل منفصل.
بشكل عام ، يؤدي النموذج المدرب على الجمل المتسلسلة أسوأ قليلاً من النموذج الذي تم تدريبه على جمل منفصلة. لكننا نوفر 50 ٪ من وقت التدريب عن طريق تقليل عملية حشوة الجملة.
python main.py --train --batch-size 96 --cuda --loss nce --noise-ratio 500 --nhid 300
--emsize 300 --log-interval 1000 --nlayers 1 --dropout 0 --weight-decay 1e-8
--data data/swb --min-freq 3 --lr 2 --save nce-500-swb --concatيتم تنفيذ عملية الإنقاذ على SWBD 50 ، وذلك بفضل Hexlee.
| نوع فقدان التدريب | نوع التقييم | PPL | وير |
|---|---|---|---|
| 3gram | معتاد | ؟ | 19.4 |
| CE (بدون مسلسل) | Normed (كامل) | 53 | 13.1 |
| م | Normed (كامل) | 55 | 13.3 |
| NCE | غير مثبت (NCE) | غير صالح | 13.4 |
| NCE | Normed (كامل) | 55 | 13.4 |
| عينة أهمية | Normed (كامل) | 55 | 13.4 |
| عينة أهمية | عينة (500) | غير صالح | 19.0 (أسوأ من W/O Rescore) |
example/log/ : بعض ملفات السجل من هذه البرامج النصيةnce/ : غلاف وحدة NCEnce/nce_loss.py : خسارة NCEnce/alias_multinomial.py : أخذ عينات من طريقة الاسم المستعارnce/index_linear.py : وحدة فهرس تستخدمها NCE ، كبديل للوحدة الخطية العاديةnce/index_gru.py : وحدة فهرس تستخدم بواسطة NCE ، كبديل لوحدة نموذج اللغة بأكملهاsample.py : برنامج نصي بسيط لـ NCE Linear.example : عينة نموذج Langauge للكلمة لاستخدام NCE كخسارة.example/vocab.py : غلاف لكائن المفرداتexample/model.py : غلاف جميع nn.Module s.example/generic_model.py : غلاف النموذج لوحدة index_gru nceexample/main.py : نقطة الدخولexample/utils.py : بعض وظائف UTIL للحصول على بنية رمز أفضليدرب هذا المثال LSTM متعدد الطبقات على مهمة نمذجة اللغة. بشكل افتراضي ، يستخدم البرنامج النصي التدريبي مجموعة بيانات PTB ، المقدمة.
python main.py --train --cuda --epochs 6 # Train a LSTM on PTB with CUDAسيستخدم النموذج تلقائيًا الواجهة الخلفية Cudnn إذا تم تشغيله على CUDA مع تثبيت CUDNN.
أثناء التدريب ، إذا تم استلام مقاطعة لوحة المفاتيح (CTRL-C) ، يتم إيقاف التدريب ويتم تقييم النموذج الحالي مقابل مجموعة بيانات الاختبار.
يقبل البرنامج النصي main.py الوسائط التالية:
optional arguments:
-h, --help show this help message and exit
--data DATA location of the data corpus
--emsize EMSIZE size of word embeddings
--nhid NHID humber of hidden units per layer
--nlayers NLAYERS number of layers
--lr LR initial learning rate
--lr-decay learning rate decay when no progress is observed on validation set
--weight-decay weight decay(L2 normalization)
--clip CLIP gradient clipping
--epochs EPOCHS upper epoch limit
--batch-size N batch size
--dropout DROPOUT dropout applied to layers (0 = no dropout)
--seed SEED random seed
--cuda use CUDA
--log-interval N report interval
--save SAVE path to save the final model
--bptt max length of truncated bptt
--concat use concatenated sentence instead of individual sentence

