Pytorch NCE
More readability
La estimación de contraste de ruido (NCE) es un método de aproximación que se utiliza para trabajar en torno al enorme costo computacional de la capa de Softmax grande. La idea básica es convertir el problema de predicción en el problema de clasificación en la etapa de entrenamiento. Se ha demostrado que estos dos criterios convergen al mismo punto mínimo siempre que la distribución de ruido sea lo suficientemente cercana a uno real.
NCE une la brecha entre los modelos generativos y los modelos discriminativos, en lugar de simplemente acelerar la capa Softmax. Con NCE, puede convertir casi cualquier cosa en posterior con menos esfuerzo (creo).
Refs:
NCE:
http://www.cs.helsinki.fi/u/ahyvarin/papers/gutmann10aistats.pdf
Nce en rnnlm:
https://pdfs.semanticscholar.org/144e/357b1339c27cce7a1e69f0899c21d8140c1f.pdff
Una revisión de los métodos de aceleración de Softmax:
http://ruder.io/word-embeddings-softmax/
NCE vs. IS (muestreo de importancia): NCE es una clasificación binaria, mientras que IS es una especie de problema de clasificación de clase múltiple.
http://demo.clab.cs.cmu.edu/cdyer/nce_notes.pdf
NCE vs. GaN (red adversaria generativa):
https://arxiv.org/abs/1412.6515
En NCE, la distribución unigram generalmente se usa para aproximar la distribución de ruido porque es rápido probar. El muestreo de un unigram es igual al muestreo multinomial, que es de complejidad
Dado que la distribución unigram se puede obtener antes de la capacitación y permanece sin cambios en la capacitación, se proponen algunos trabajos para utilizar esta propiedad para acelerar el procedimiento de muestreo. El método de alias es uno de ellos.
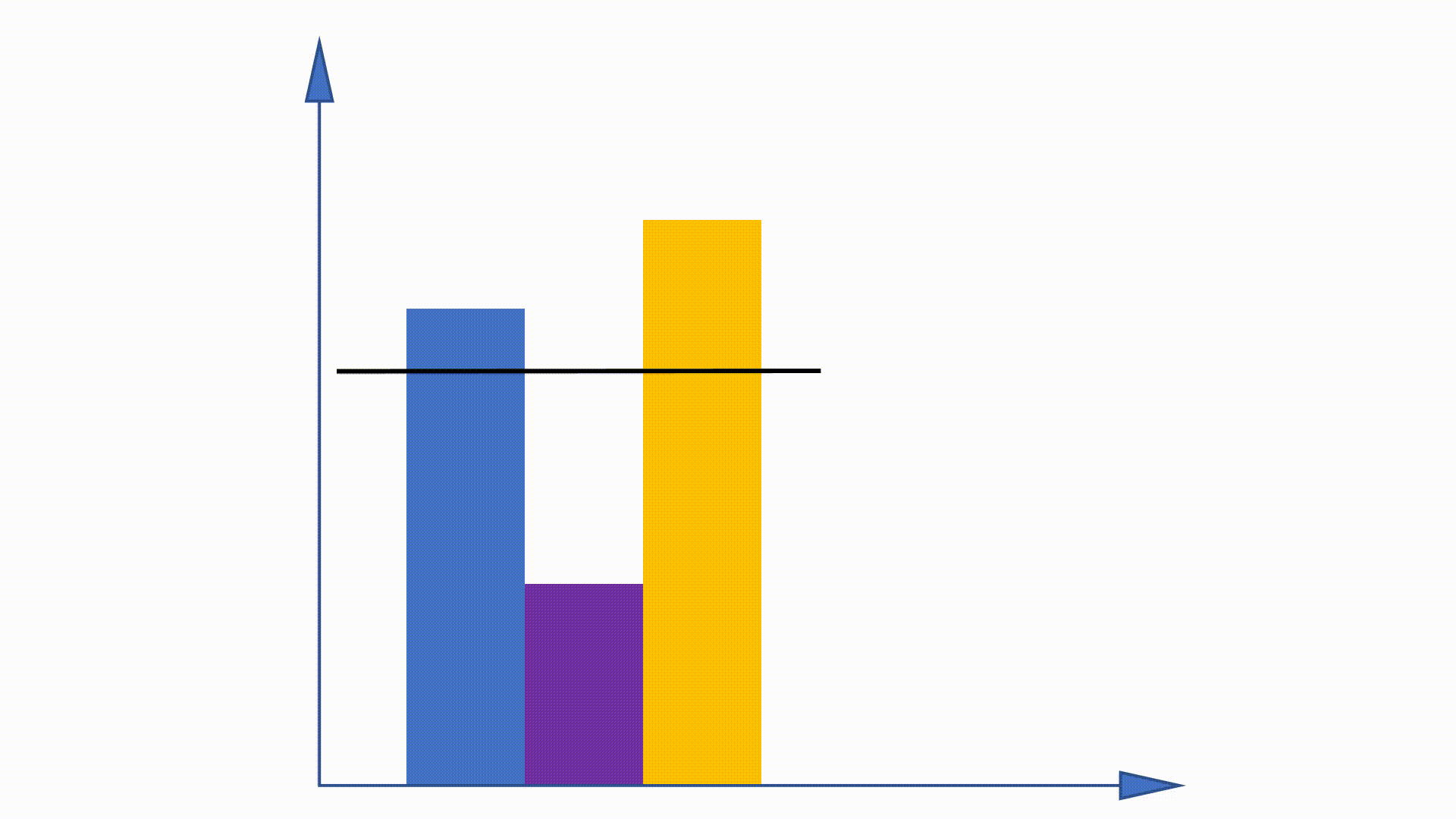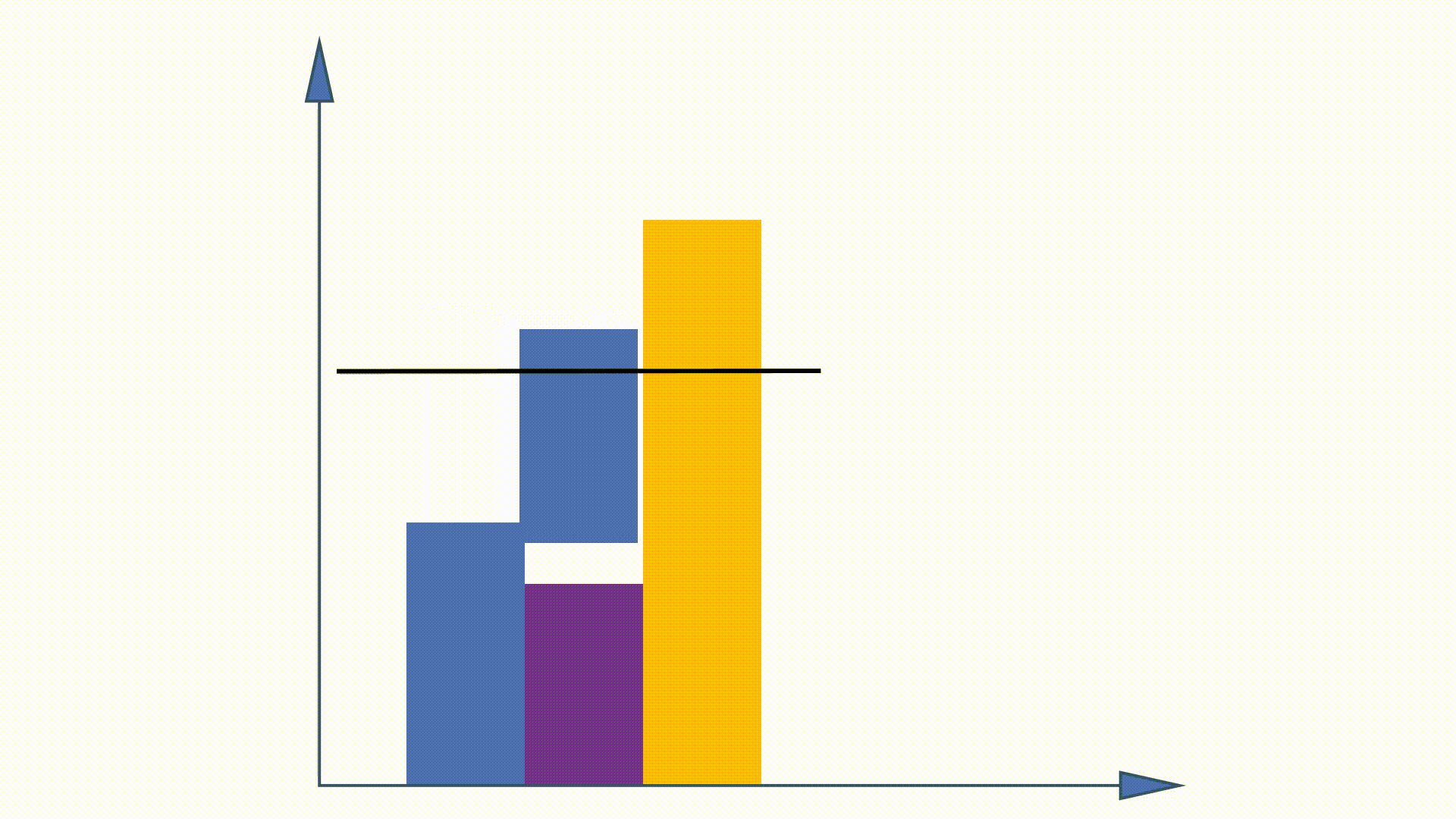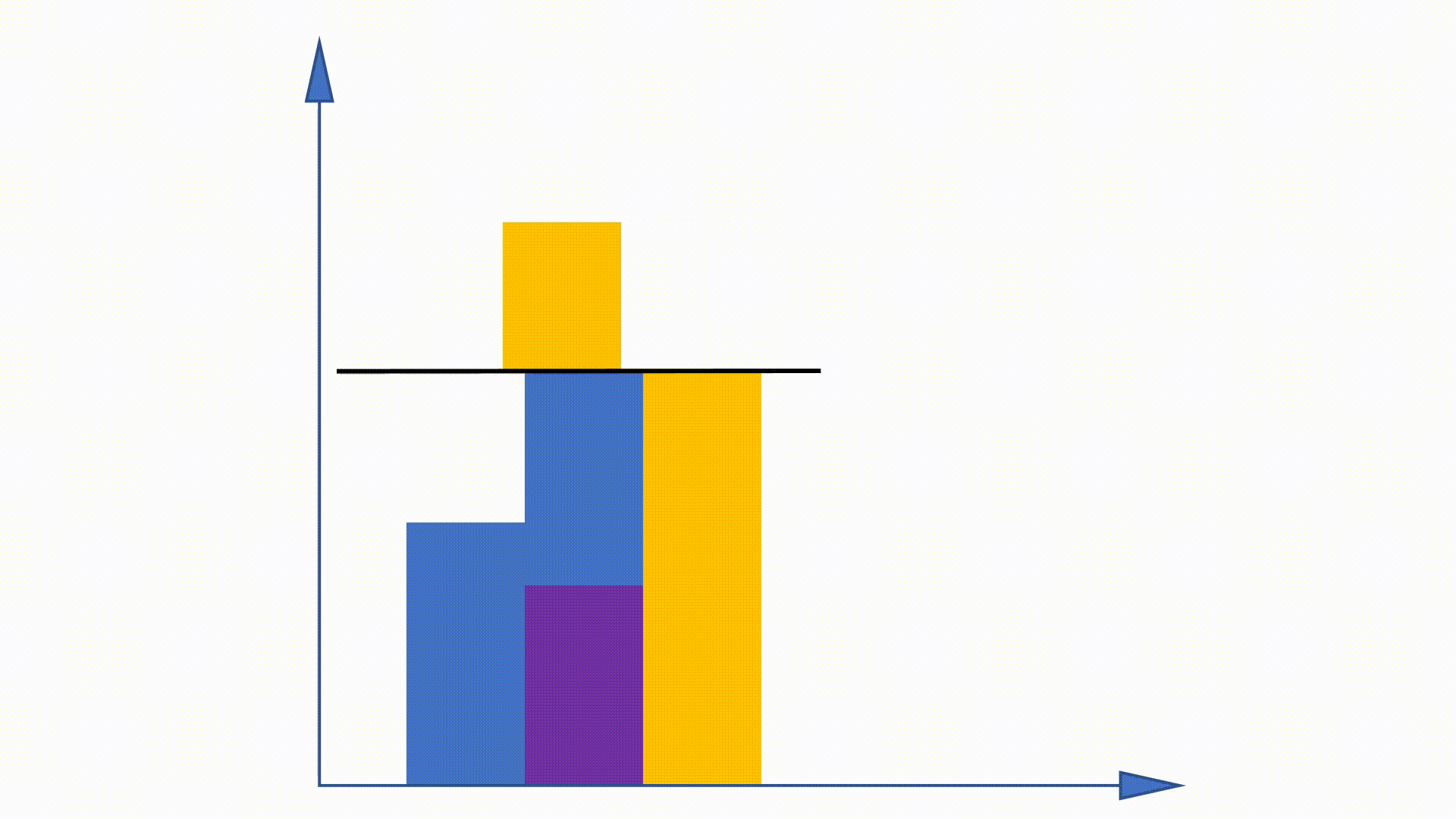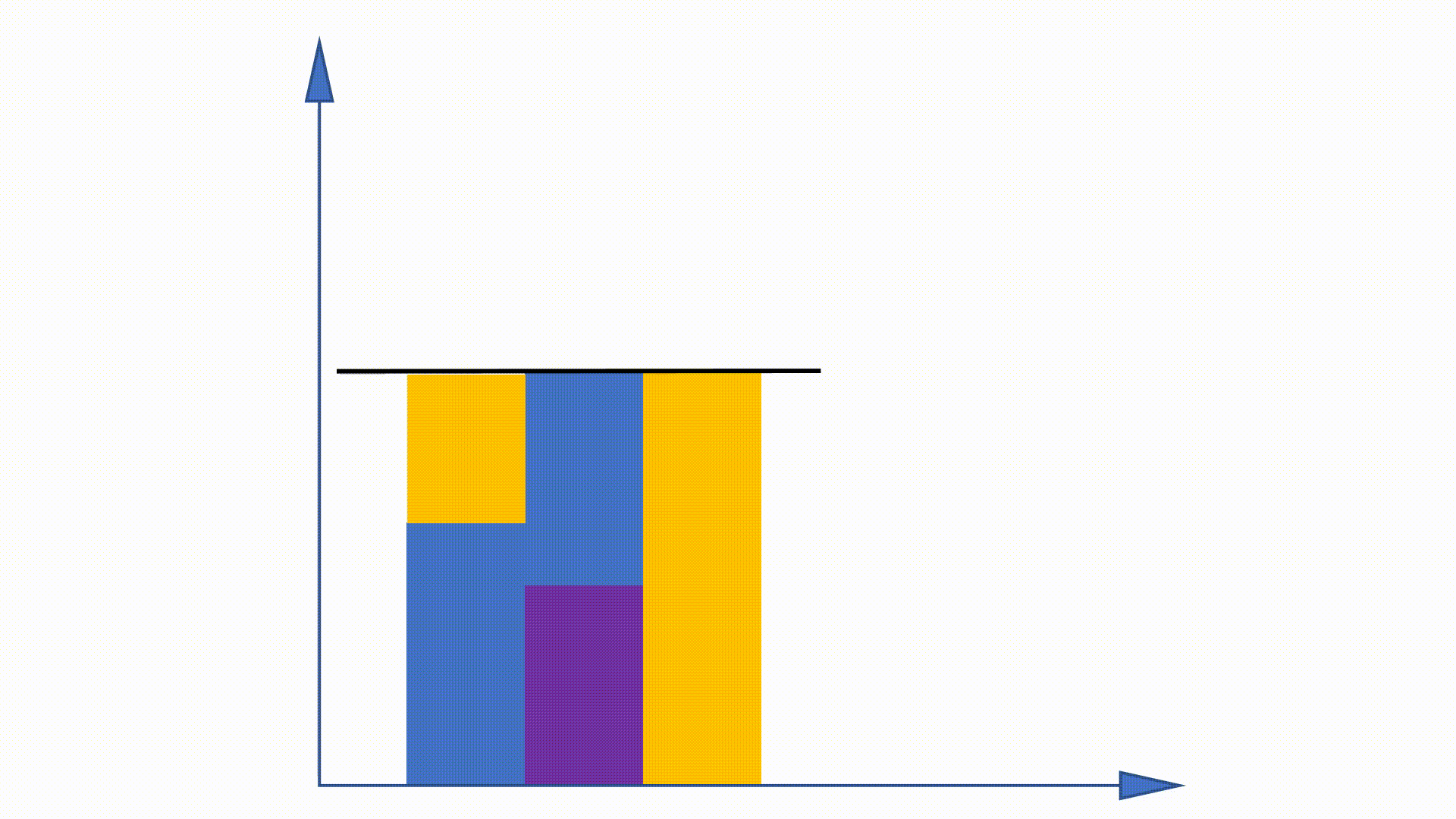
Al construir estructuras de datos, el método de alias puede reducir la complejidad de muestreo de
Refs:
Método de alias:
https://hips.seas.harvard.edu/blog/2013/03/03/the-alias-method-eficiente-sampling-with-many-discrete-outcomes/
NCE convencional solo realiza el contraste en la capa lineal (softmax), es decir, dada una entrada de una capa lineal, las salidas del modelo son
En esta base de código, uso una variante de NCE genérico llamado Full-NCE (F-NCE) para aclarar. A diferencia del NCE normal, F-NCE muestra los ruidos en la incrustación de entrada.
Refs:
Modelo de lenguaje de oración completa por IBM (ICASSP2018)
Modelo de lenguaje BI-LSTM por SpeechLab, SJTU (ICSLP2016?)
El NCE convencional requiere diferentes muestras de ruido por token de datos. Tal patrón computacional no es totalmente eficiente en GPU porque necesita una multiplicación de matriz por parte. Un truco es compartir las muestras de ruido en todo el mini lote, por lo tanto, la multiplicación de matriz de lotes escasas se convierte en una multiplicación de matriz densa más eficiente. El NCE por lotes ya es compatible con TensorFlow.
Un enfoque más agresivo es llamado auto contrastante (nombrado por mí mismo). En lugar de un muestreo de la distribución de ruido, los ruidos son simplemente las otras fichas de entrenamiento dentro del mismo mini lote.
Árbitro:
NCE por lotes
https://arxiv.org/pdf/1708.05997.pdf
Auto contrastante:
https://www.isi.edu/natural-language/mt/simple-stast-noise.pdf
Hay un ejemplo que ilustra cómo usar el módulo NCE en la carpeta de example . Este ejemplo se bifurca del repositorio de Pytorch/Ejemplos.
Ejecute pip install -r requirements primero para ver si tiene el Python Lib requerido.
tqdm se utiliza para la barra de proceso durante la capacitacióndill es un reemplazo más flexible para Pickle--nce : si usar NCE como aproximación--noise-ratio <50> : Número de muestras de ruido por lote, el ruido se comparte entre los tokens en un solo lote, para la velocidad de entrenamiento.--norm-term <9> : el término de normalización constante Ln(z)--index-module <linear> : el módulo de índice para usar para el módulo NCE (actualmente y disponible, no admite el calculación de las personas)--train : trenes o simplemente evaluación modelo existente--vocab <None> : use el archivo de vocabulario si se especifica, de lo contrario use las palabras en trenes.txt--loss [full, nce, sampled, mix] : elija uno de los tipos de pérdida para el entrenamiento, la pérdida se convierte en la evaluación full de PPL automáticamente.Ejecute NCE Criterion con módulo lineal:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --trainEjecute el criterio NCE con el módulo Gru:
python main.py --cuda --noise-ratio 10 --norm-term 9 --nce --train --index-module gruEjecutar Criterio CE convencional:
python main.py --cuda --train Es un escaparate de rendimiento. Sin embargo, el conjunto de datos no está incluido en este repositorio. El modelo está entrenado en oraciones concatenadas, pero los estados ocultos no se pasan a través de lotes. Se inserta un <s> entre oraciones. El modelo se evalúa en oraciones <s> acolchadas por separado.
Generalmente, un modelo entrenado en oraciones concatenadas funciona un poco peor que la que se entrenó en oraciones separadas. Pero ahorra el 50% del tiempo de entrenamiento al reducir la operación de relleno de oraciones.
python main.py --train --batch-size 96 --cuda --loss nce --noise-ratio 500 --nhid 300
--emsize 300 --log-interval 1000 --nlayers 1 --dropout 0 --weight-decay 1e-8
--data data/swb --min-freq 3 --lr 2 --save nce-500-swb --concatEl rescore se realiza en el mejor swbd 50, gracias a Hexlee.
| Tipo de pérdida de entrenamiento | tipo de evaluación | Ppl | Feroz |
|---|---|---|---|
| 3gram | normado | ? | 19.4 |
| CE (sin concat) | Normado (completo) | 53 | 13.1 |
| Ceñudo | Normado (completo) | 55 | 13.3 |
| NCE | no anormado (NCE) | inválido | 13.4 |
| NCE | Normado (completo) | 55 | 13.4 |
| muestra de importancia | Normado (completo) | 55 | 13.4 |
| muestra de importancia | Muestrado (500) | inválido | 19.0 (peor que sin rescore) |
example/log/ : algunos archivos de registro de estos scriptsnce/ : el envoltorio del módulo NCEnce/nce_loss.py : la pérdida de NCEnce/alias_multinomial.py : muestreo de métodos de aliasnce/index_linear.py : un módulo de índice utilizado por NCE, como un reemplazo para el módulo lineal normalnce/index_gru.py : un módulo de índice utilizado por NCE, como un reemplazo para todo el módulo de modelo de idiomasample.py : un script simple para NCE Lineal.example : una muestra de modelo de Word Langauge para usar NCE como pérdida.example/vocab.py : un contenedor para el objeto de vocabularioexample/model.py : el envoltorio de todos nn.Module s.example/generic_model.py : el envoltorio de modelo para el módulo index_gru nceexample/main.py : punto de entradaexample/utils.py : algunas funciones Util para una mejor estructura de códigoEste ejemplo entrena un LSTM de múltiples capas en una tarea de modelado de idiomas. Por defecto, el script de capacitación utiliza el conjunto de datos PTB, proporcionado.
python main.py --train --cuda --epochs 6 # Train a LSTM on PTB with CUDAEl modelo usará automáticamente el backend de CUDNN si se ejecuta en CUDA con CUDNN instalado.
Durante el entrenamiento, si se recibe una interrupción del teclado (CTRL-C), se detiene la capacitación y el modelo actual se evalúa con el conjunto de datos de prueba.
El script main.py acepta los siguientes argumentos:
optional arguments:
-h, --help show this help message and exit
--data DATA location of the data corpus
--emsize EMSIZE size of word embeddings
--nhid NHID humber of hidden units per layer
--nlayers NLAYERS number of layers
--lr LR initial learning rate
--lr-decay learning rate decay when no progress is observed on validation set
--weight-decay weight decay(L2 normalization)
--clip CLIP gradient clipping
--epochs EPOCHS upper epoch limit
--batch-size N batch size
--dropout DROPOUT dropout applied to layers (0 = no dropout)
--seed SEED random seed
--cuda use CUDA
--log-interval N report interval
--save SAVE path to save the final model
--bptt max length of truncated bptt
--concat use concatenated sentence instead of individual sentence

