hierarchical language modeling
1.0.0
一个干净的模板来启动您的深度学习项目⚡
单击使用此模板来初始化新存储库。
总是欢迎建议!
为什么您可能要使用它:
✅保存在样板上
轻松地添加新的型号,数据集,任务,实验和训练不同的加速器,例如Multi-GPU,TPU或Slurm簇。
✅教育
彻底评论。您可以将此存储库用作学习资源。
✅可重复使用
收集有用的MLOPS工具,配置和代码段。您可以将此存储库用作各种公用事业的参考。
为什么您可能不想使用它:
事情不时破裂
闪电和九头蛇仍在不断发展并整合了许多库,这意味着有时事情会破裂。有关当前已知问题的列表,请访问此页面。
未针对数据工程进行调整
对于构建彼此依赖的数据管道,并未真正调整模板。在现成数据上将其用于模型原型化更为有效。
过于简单用例
构建配置设置是在简单的闪电训练中构建的。您可能需要付出一些努力来针对不同的用例(例如闪电面料)进行调整。
可能不支持您的工作流程
例如,您无法恢复基于Hydra的Multirun或Hypergarameter搜索。
注意:请记住,这是非正式的社区项目。
Pytorch Lightning-一款用于高性能AI研究的轻质Pytorch包装纸。将其视为组织您的Pytorch代码的框架。
Hydra-用于优雅配置复杂应用程序的框架。关键功能是能够通过构图动态创建层次结构配置,并通过配置文件和命令行覆盖它。
新项目的目录结构看起来像这样:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt模板包含具有MNIST分类的示例。
运行python src/train.py时,您应该看到这样的东西:
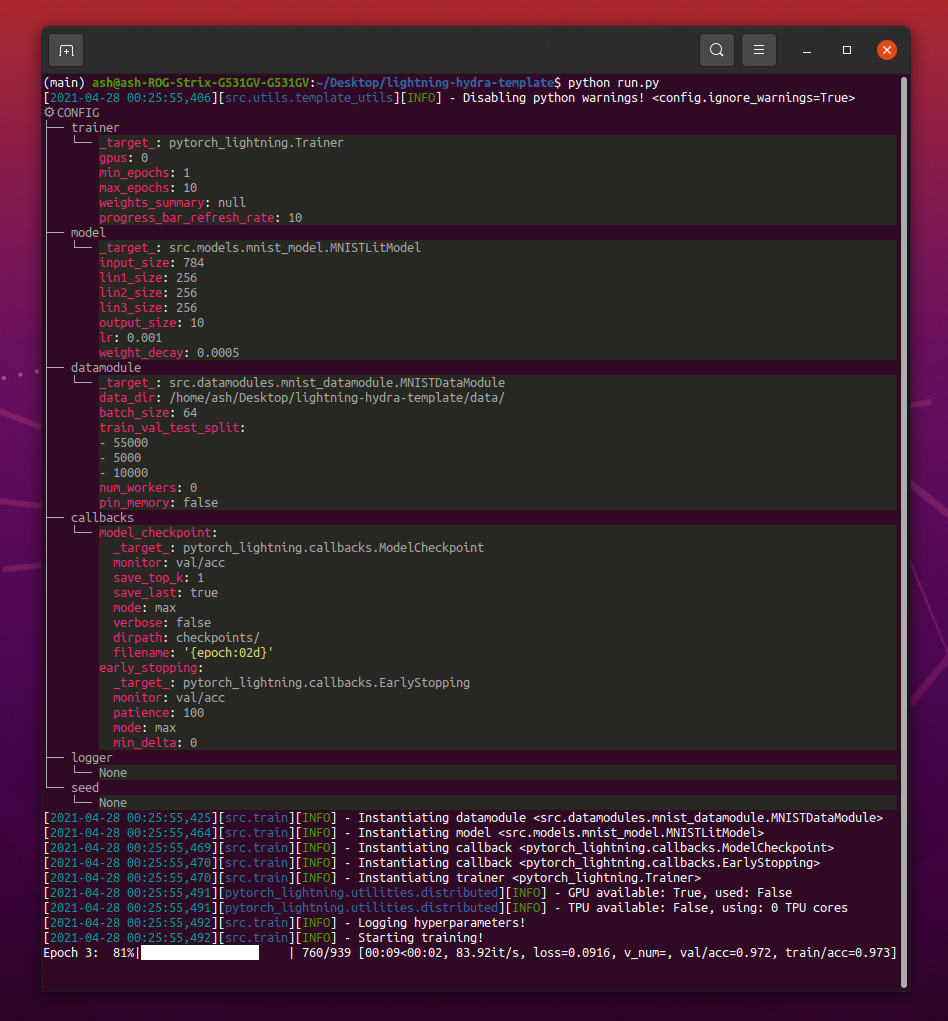
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4注意:您还可以添加带有
+标志的新参数。
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mps警告:目前DDP模式存在问题,请阅读此问题以了解更多信息。
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandb注意:Lightning提供了最流行的记录框架的方便集成。在这里了解更多。
注意:使用wandb要求您首先设置帐户。之后,只需完成如下的配置即可。
注意:单击此处查看使用此模板生成的示例Wandb仪表板。
python train.py experiment=example注意:实验配置放置在配置/实验/中。
python train.py callbacks=default注意:可以将回调用于诸如模型检查点,早期停止等的事物。
注意:回调配置放置在配置/回调/中。
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"注意:Pytorch Lightning提供约40多个有用的教练标志。
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2注意:有关不同的调试配置,请访问configs/ debug/。
python train.py ckpt_path="/path/to/ckpt/name.ckpt"注意:检查点可以是路径或URL。
注意:当前加载CKPT并未恢复Logger实验,但将在将来的闪电发布中支持。
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"注意:检查点可以是路径或URL。
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005注意:Hydra在启动时懒洋洋地撰写配置。如果您在启动作业/扫描后更改代码或配置,则最终组合的配置可能会受到影响。
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=example注意:使用Optuna扫地机不需要您将任何样板添加到代码中,而是在单个配置文件中定义的所有内容。
警告:Optuna扫除不是抗故障的(如果一个工作崩溃,那么整个扫荡崩溃)。
python train.py -m ' experiment=glob(*) '注意:Hydra提供了用于控制多次行为的特殊语法。在这里了解更多。上面的命令执行来自configs/实验/的所有实验。
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]注意:
trainer.deterministic=True使Pytorch更加确定性,但会影响性能。
注意:使用Ray AWS启动器用于Hydra,应该可以通过简单的配置来实现这一点。示例未在此模板中实现。
注意:Hydra允许您通过按
tab键在编写壳牌时自动完成配置参数覆盖。阅读文档。
pre-commit run -a注意:应用预加压挂钩来执行诸如自动形成代码和配置,执行代码分析或从Jupyter笔记本电脑中删除输出的事情。有关更多信息,请参见#最佳实践。
在.pre-commit-config.yaml中更新前签名版本:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "每个实验都应被标记,以便在文件或Logger UI中轻松过滤它们:
python train.py tags=[ " mnist " , " experiment_X " ]注意:您可能需要使用
python train.py tags=["mnist","experiment_X"]逃脱外壳中的括号字符。
如果没有提供标签,将要求您从命令行输入它们:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):如果没有为多室提供标签,将会引起错误:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !注意:Hydra目前不支持命令行的附加列表:(
由于所有贡献的人,该项目的存在。
有问题吗?找到一个错误?缺少特定功能?随意提交新的问题,讨论或公关,以各自的标题和描述。
在提出问题之前,请验证:
main分支。总是欢迎提出改进的建议!
所有Pytorch Lightning模块均通过Config中指定的模块路径动态实例化。示例模型配置:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10使用此配置,我们可以使用以下行实例化对象:
model = hydra . utils . instantiate ( config . model )这使您可以轻松迭代新型号!每次创建新的时,只需在适当的配置文件中指定其模块路径和参数即可。
使用命令行参数之间的模型和数据模块切换:
python train.py model=mnist示例管道管理实例逻辑:src/train.py。
位置:configs/train.yaml
主项目配置包含默认培训配置。
它确定在简单地执行命令python train.py时如何组成配置。
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null 位置:配置/实验
实验配置允许您从主配置覆盖参数。
例如,您可以使用它们来控制模型和数据集的每种组合的最佳超参数。
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " 基本工作流程
python src/train.py experiment=experiment_name.yaml实验设计
假设您想执行许多跑步,以绘制批量大小的准确性变化。
使用一些配置参数执行运行,该参数允许您轻松识别它们,例如标签:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ]编写一个脚本或笔记本,该脚本或笔记本在logs/文件夹上搜索,并从配置中包含给定标签的运行中检索CSV日志。绘制结果。
Hydra为每个执行的运行创建新的输出目录。
默认记录结构:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
您可以通过修改Hydra配置中的路径来更改此结构。
Pytorch Lightning支持许多流行的伐木框架:重量和偏见,海王星,彗星,MLFLOW,张量。
这些工具可帮助您跟踪超参数和输出指标,并允许您比较和可视化结果。要使用其中之一,只需在Configs/Logger中完成其配置,然后运行:
python train.py logger=logger_name您可以一次使用许多(例如,请参见Configs/Logger/Many_loggers.yaml)。
您也可以编写自己的记录仪。
Lightning提供了方便的方法,用于从内部闪电模块来记录自定义指标。阅读文档或以MNIST示例为例。
模板带有使用pytest实施的通用测试。
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "大多数实施的测试都没有检查任何特定的输出 - 它们的存在只是为了简单地验证执行某些命令并不最终会引发异常。您可以偶尔执行它们以加快开发的速度。
目前,测试涵盖了:
还有许多其他。您应该能够轻松地修改它们的用例。
还实施了@RunIf装饰器,只有在满足某些条件时,可以运行测试,例如GPU可用或系统不是Windows。请参阅示例。
您可以通过将新的配置文件添加到Configs/HParams_search来定义超参数搜索。
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256)接下来,执行以下操作: python train.py -m hparams_search=mnist_optuna
使用此方法不需要将任何样板添加到代码中,所有内容都是在单个配置文件中定义的。唯一必要的事情是从启动文件返回优化的度量值。
您可以使用与Hydra集成的不同优化框架,例如Optuna,Ax或Nevergrad。
optimization_results.yaml _Results.yaml将在logs/task_name/multirun文件夹下可用。
这种方法不支持恢复中断的搜索和高级技术(如Prunning) - 对于更复杂的搜索和工作流程,您可能应该编写专用的优化任务(没有多室内功能)。
模板带有GitHub操作中实现的CI工作流程:
.github/workflows/test.yaml :用pytest运行所有测试.github/workflows/code-quality-main.yaml.github/workflows/code-quality-pr.yaml 闪电支持多种进行分布式培训的方法。最常见的是DDP,它为每个GPU提供了单独的过程,并在它们之间平均梯度。要了解其他方法,请阅读闪电文档。
您可以在MNIST示例上运行DDP,并以4个GPU这样的方式运行DDP:
python train.py trainer=ddp注意:使用DDP时,您必须小心编写模型的方式 - 阅读文档。
最简单的方法是将Datamodule属性直接传递到初始化的模型:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )注意:这不是一个非常健壮的解决方案,因为它假设您的所有数据模块都有
some_param属性可用。
同样,您可以将整个Datamodule配置作为init参数传递:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )您还可以通过可变插值传递数据函数配置参数:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}另一种方法是直接通过教练访问LightningModule中的DataModule:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_param注意:这仅在训练开始后起作用,因为否则培训师在LightningModule中尚未可用。
通常不需要安装完整的Anaconda环境,Minconda应该足够(约80MB)。
CONDA的最大优势是,它允许安装软件包,而无需系统中的某些编译器或库(因为它安装了预编译的二进制文件),因此通常会使安装某些依赖关系更容易,例如cudatoolkit来获得GPU支持。
它还使您可以在全球范围内访问环境,这可能比为每个项目创建新的本地环境更方便。
示例安装:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh更新conda:
conda update -n base -c defaults conda创建新的Conda环境:
conda create -n myenv python=3.10
conda activate myenv使用预先承诺的钩子标准化项目的代码格式并节省精神能量。
只需使用:
pip install pre-commit接下来,从.pre-commit-config.yaml安装钩子:
pre-commit install之后,您的代码将在每个新提交中自动重新格式化。
重新格式化项目使用命令中的所有文件:
pre-commit run -a在.pre-commit-config.yaml中更新挂钩版本:
pre-commit autoupdate系统特定变量(例如,数据集的绝对路径)不应在版本控制下,否则将导致不同用户之间的冲突。您的私钥也不应该版本,因为您不希望它们被泄漏。
模板包含.env.example文件,作为示例。创建一个名为.env的新文件(此名称不包括在.gitignore中的版本控件中)。您应该将其用于存储这样的环境变量:
MY_VAR=/home/user/my_system_path
来自.env的所有变量都会自动加载在train.py中。
hydra允许您在类似的.yaml配置中引用任何ENV变量:
path_to_data : ${oc.env:MY_VAR}根据您使用的记录器的不同,通常可以使用/字符定义公制名称:
self . log ( "train/loss" , loss )这样,伐木者将把您的指标视为属于不同部分的指标,这有助于使它们在UI中组织起来。
使用官方的Torchmetrics库来确保对指标的正确计算。这对于多GPU培训尤其重要!
例如,您应该使用这样的提供的Accuracy类,而不是自己计算准确性:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...确保为每个步骤使用不同的度量实例,以确保对所有GPU过程的适当降低。
Torchmetrics为大多数用例提供指标,例如F1分数或混淆矩阵。阅读文档以获取更多信息。
样式指南可在此处找到。
在您的初始化中明确。尝试定义所有相关默认值,以便用户不必猜测。提供类型提示。这样,您的模块可以在各个项目中重复使用!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):保留推荐的方法订单。
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
...使用DVC来控制大文件,例如您的数据或训练有素的ML型号。
初始化DVC存储库:
dvc init要开始跟踪文件或目录,请使用dvc add :
dvc add data/MNISTDVC将有关添加文件(或目录)的信息存储在名为data/mnist.dvc的特殊.DVC文件中,这是一个带有人类可读格式的小文本文件。该文件可以像git一样轻松地将其像源代码一样,作为原始数据的占位符:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data "它允许其他人轻松地在自己的项目中使用您的模块。将src文件夹的名称更改为您的项目名称,然后完成setup.py文件。
现在,您的项目可以从本地文件安装:
pip install -e .或直接来自GIT存储库:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgrade因此,任何文件都可以轻松导入到任何其他文件中:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModule某些配置是特定于用户/计算机/安装的(例如,本地群集的配置或特定机器上的硬盘路径)。对于这样的情况,可以创建文件configs/local/default.yaml,该文件会自动加载但不通过git跟踪。
例如,您可以将其用于slurm cluster config:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd 该模板的灵感来自:
其他有用的存储库:
Lightning-Hydra-Template已获得MIT许可证的许可。
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
删除您项目上面的所有内容
它做什么
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenv带有默认配置的火车模型
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpu带有配置/实验/实验选择的训练模型/
python src/train.py experiment=experiment_name.yaml您可以从命令行覆盖任何参数
python src/train.py trainer.max_epochs=20 data.batch_size=64

