hierarchical language modeling
1.0.0
Eine saubere Vorlage, um Ihr Deep Learning Project ⚡ zu starten ⚡
Klicken Sie auf diese Vorlage, um das neue Repository zu initialisieren.
Vorschläge sind immer willkommen!
Warum Sie es vielleicht verwenden möchten:
✅ Sparen Sie Kesselplatte
Fügen Sie einfach neue Modelle, Datensätze, Aufgaben, Experimente und Zug für verschiedene Beschleuniger wie Multi-GPU-, TPU- oder Slurm-Cluster hinzu.
✅ Bildung
Gründlich kommentiert. Sie können dieses Repo als Lernressource verwenden.
✅ Wiederverwendbarkeit
Sammlung nützlicher MLOPS -Tools, Konfigurationen und Codeausschnitte. Sie können dieses Repo als Referenz für verschiedene Dienstprogramme verwenden.
Warum Sie es vielleicht nicht verwenden möchten:
Die Dinge brechen von Zeit zu Zeit
Blitz und Hydra entwickeln sich immer noch und integrieren viele Bibliotheken, was bedeutet, dass die Dinge manchmal brechen. Die Liste der derzeit bekannten Probleme besuchen Sie diese Seite.
Nicht an Datentechnik angepasst
Die Vorlage wird nicht wirklich für das Erstellen von Datenpipelines angepasst, die voneinander abhängen. Es ist effizienter, es für das Modellprototyping für ready-use-Daten zu verwenden.
Übereingestaltet in einfache Anwendungsfälle übernommen
Das Konfigurationsaufbau ist mit dem einfachen Blitztraining erstellt. Möglicherweise müssen Sie einige Anstrengungen unternehmen, um es für verschiedene Anwendungsfälle anzupassen, z. B. ein Blitzgewebe.
Unterstützt Ihren Workflow möglicherweise nicht
Beispielsweise können Sie keine Hydra-basierte Multirun- oder Hyperparameter-Suche fortsetzen.
HINWEIS : Denken Sie daran, dass dies ein inoffizielles Community -Projekt ist.
Pytorch Lightning - Eine leichte Pytorch -Wrapper für Hochleistungs -AI -Forschung. Stellen Sie sich dies als Rahmen für die Organisation Ihres Pytorch -Codes vor.
Hydra - Ein Framework für die elegant konfigurierte Konfiguration komplexer Anwendungen. Die Schlüsselfunktion ist die Möglichkeit, eine hierarchische Konfiguration dynamisch nach Komposition zu erstellen und sie über Konfigurationsdateien und die Befehlszeile zu überschreiben.
Die Verzeichnisstruktur des neuen Projekts sieht so aus:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt Vorlage enthält ein Beispiel mit der MNIST -Klassifizierung.
Wenn Sie python src/train.py laufen lassen, sollten Sie so etwas sehen:
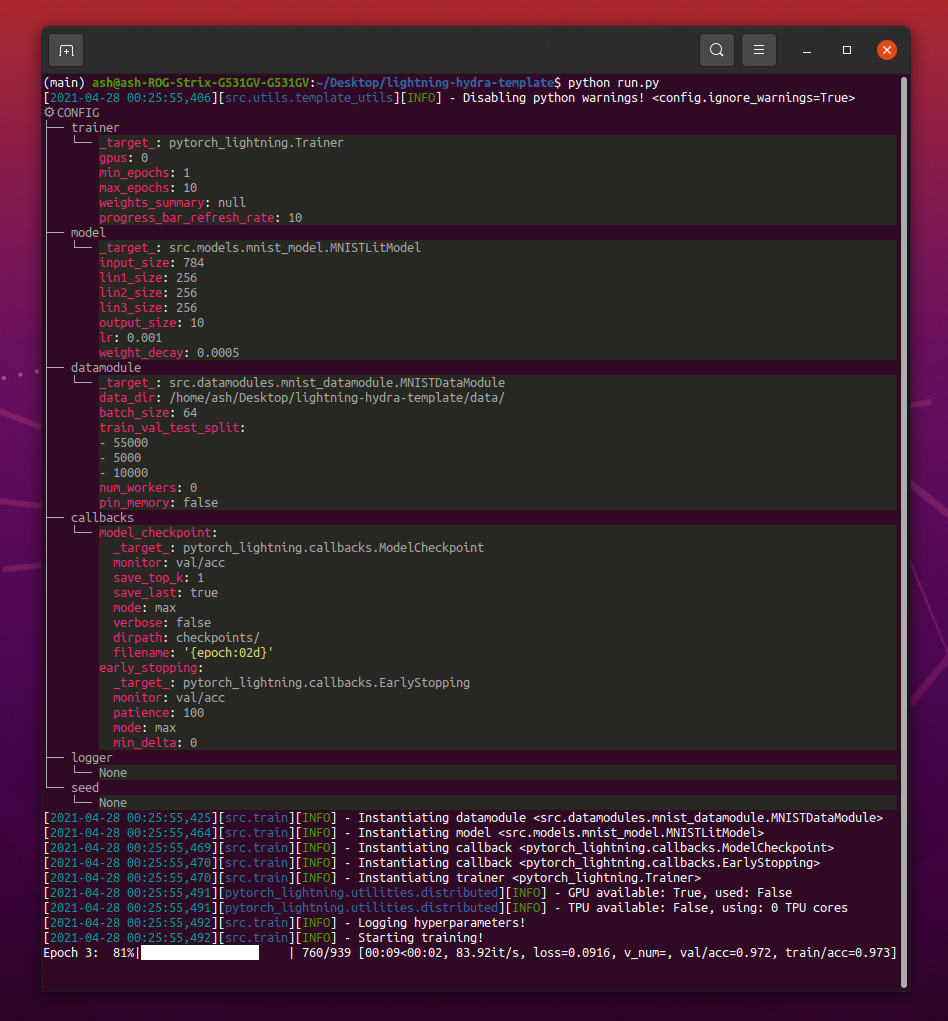
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4Hinweis : Sie können auch neue Parameter mit
+Zeichen hinzufügen.
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsWarnung : Derzeit gibt es Probleme mit dem DDP -Modus. Lesen Sie dieses Problem, um mehr zu erfahren.
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbHinweis : Lightning bietet bequeme Integrationen mit den beliebtesten Protokollierungsrahmen. Erfahren Sie hier mehr.
HINWEIS : Verwenden von WANDB müssen Sie zuerst das Konto einrichten. Führen Sie danach einfach die Konfiguration wie unten aus.
HINWEIS : Klicken Sie hier, um Beispiele anzuzeigen, das mit dieser Vorlage generiert wurde.
python train.py experiment=exampleHinweis : Experimentkonfigurationen werden in Konfigurationen/Experiment/gegeben.
python train.py callbacks=defaultHINWEIS : Rückrufe können für Dinge wie Modellprüfungen, frühes Stoppen und vieles mehr verwendet werden.
HINWEIS : Callbacks -Konfigurationen werden in Konfigurationen/Rückrufe platziert/.
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"Hinweis : Pytorch Lightning bietet etwa 40 nützliche Trainerflaggen.
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2HINWEIS : Besuchen Sie Konfigurationen/ Debuggen/ Für verschiedene Debugging -Konfigurationen.
python train.py ckpt_path="/path/to/ckpt/name.ckpt"Hinweis : Der Checkpoint kann entweder Pfad oder URL sein.
Hinweis : Das Laden von CKPT wird derzeit kein Logger -Experiment fortgesetzt, wird jedoch in zukünftigen Blitzfreigabe unterstützt.
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"Hinweis : Der Checkpoint kann entweder Pfad oder URL sein.
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005HINWEIS : Hydra komponiert Konfigurationen in der Jobstartzeit faul. Wenn Sie nach dem Start eines Jobs/Sweeps den Code oder die Konfiguration ändern, werden die endgültigen komponierten Konfigurationen möglicherweise beeinflusst.
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleHINWEIS : Mithilfe der Optuna -Kehrmaschine müssen Sie Ihrem Code keine Boilerplate hinzufügen. In einer einzelnen Konfigurationsdatei wird alles definiert.
WARNUNG : Optuna Sweeps sind nicht fehlerresistent (wenn ein Job abstürzt, stürzt der gesamte Sweep ab).
python train.py -m ' experiment=glob(*) 'HINWEIS : Hydra bietet eine spezielle Syntax für die Kontrolle des Verhaltens von Multiruns. Erfahren Sie hier mehr. Der obige Befehl führt alle Experimente aus Konfigurationen/Experiment/aus.
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]Hinweis :
trainer.deterministic=Truemacht Pytorch deterministischer, wirkt sich jedoch auf die Leistung aus.
Hinweis : Dies sollte mit einer einfachen Konfiguration mit Ray AWS -Launcher für Hydra erreichbar sein. Beispiel wird in dieser Vorlage nicht implementiert.
HINWEIS : Mit Hydra können Sie die Überschreibung von Konfigurationsargumenten in Shell automatisch abschließen, indem Sie sie schreiben, indem Sie die
tabTaste drücken. Lesen Sie die Dokumente.
pre-commit run -aHINWEIS : Wenden Sie Pre-Commit-Hooks an, um Dinge wie automatisch formatierende Code und Konfigurationen durchzuführen, die Codeanalyse durchzuführen oder die Ausgabe von Jupyter-Notizbüchern zu entfernen. Siehe # Best Practices für mehr.
Aktualisieren Sie Pre-Commit-Hakenversionen in .pre-commit-config.yaml mit:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Jedes Experiment sollte markiert werden, um sie einfach über Dateien oder in der Logger -Benutzeroberfläche hinweg zu filtern:
python train.py tags=[ " mnist " , " experiment_X " ]HINWEIS : Möglicherweise müssen Sie den Klammerzeichen in Ihrer Schale mit
python train.py tags=["mnist","experiment_X"]entkommen.
Wenn keine Tags bereitgestellt werden, werden Sie aufgefordert, sie aus der Befehlszeile einzugeben:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):Wenn für Multirun keine Tags bereitgestellt werden, wird ein Fehler erhöht:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !Hinweis : Anhanglisten aus der Befehlszeile werden derzeit in Hydra nicht unterstützt :(
Dieses Projekt besteht dank aller Menschen, die einen Beitrag leisten.
Haben Sie eine Frage? Einen Fehler gefunden? Fehlen einer bestimmten Funktion? Fühlen Sie sich frei, ein neues Problem, eine neue Diskussion oder ein PR mit dem jeweiligen Titel und der jeweiligen Beschreibung einzureichen.
Bevor Sie ein Problem machen, überprüfen Sie dies bitte:
main .Verbesserungsvorschläge sind immer willkommen!
Alle Pytorch -Blitzmodule werden dynamisch von den in der Konfiguration angegebenen Modulpfaden instanziiert. Beispielmodellkonfiguration:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10Mit dieser Konfiguration können wir das Objekt mit der folgenden Zeile instanziieren:
model = hydra . utils . instantiate ( config . model ) Auf diese Weise können Sie leicht über neue Modelle wiederholen! Jedes Mal, wenn Sie eine neue erstellen, geben Sie einfach den Modulpfad und die Parameter in der entsprechenden Konfigurationsdatei an.
Wechseln Sie zwischen Modellen und Datamodulen mit Befehlszeilenargumenten:
python train.py model=mnistBeispiel Pipeline Verwaltung der Instanziellogik: SRC/Train.py.
Ort: configs/train.yaml
Hauptprojektkonfiguration enthält eine Standard -Trainingskonfiguration.
Es bestimmt, wie die Konfiguration komponiert wird, wenn der Befehl python train.py einfach ausführt.
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null Ort: Konfigurationen/Experiment
Mit Experimentkonfigurationen können Sie die Parameter von der Hauptkonfiguration überschreiben.
Sie können sie beispielsweise verwenden, um die besten Hyperparameter für die Versionskontrolle für jede Kombination aus Modell und Datensatz zu steuern.
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " Grundlegender Workflow
python src/train.py experiment=experiment_name.yamlExperimententwurf
Angenommen, Sie möchten viele Läufe ausführen, um zu zeichnen, wie sich die Genauigkeit in Bezug auf die Stapelgröße ändert.
Führen Sie die Runs mit einem Konfigurationsparameter aus, mit dem Sie sie einfach identifizieren können, z. B. Tags:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] Schreiben Sie ein Skript oder Notizbuch, das über die logs/ den Ordner sucht und CSV -Protokolle aus Läufen, die angegebene Tags in der Konfiguration enthalten, abgerufen. Zeichnen Sie die Ergebnisse.
Hydra erstellt für jeden ausgeführten Lauf ein neues Ausgabeverzeichnis.
Standardprotokollierungsstruktur:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
Sie können diese Struktur ändern, indem Sie Pfade in der Hydra -Konfiguration ändern.
Pytorch Lightning unterstützt viele beliebte Protokollierungsrahmen: Gewichte & Vorurteile, Neptun, Komet, MLFlow, Tensorboard.
Diese Tools helfen Ihnen dabei, Hyperparameter und Ausgangsmetriken zu verfolgen und die Ergebnisse zu vergleichen und zu visualisieren. Um eine von ihnen zu verwenden, vervollständigen Sie einfach seine Konfiguration in Konfigurationen/Logger und führen Sie aus:
python train.py logger=logger_nameSie können viele von ihnen gleichzeitig verwenden (siehe Konfigurationen/Logger/Many_Loggers.Yaml).
Sie können auch Ihren eigenen Logger schreiben.
Lightning bietet eine bequeme Methode für die Protokollierung benutzerdefinierter Metriken von Innenleichtermodule. Lesen Sie die Dokumente oder schauen Sie sich das MNIST -Beispiel an.
Die Vorlage wird mit generischen Tests geliefert, die mit pytest implementiert sind.
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Die meisten der implementierten Tests prüfen nicht auf eine bestimmte Ausgabe - sie bestehen einfach, um einfach zu überprüfen, ob die Ausführung einiger Befehle keine Ausnahmen ausführt. Sie können sie hin und wieder ausführen, um die Entwicklung zu beschleunigen.
Derzeit decken die Tests Fälle wie:
Und viele andere. Sie sollten in der Lage sein, sie für Ihren Anwendungsfall leicht zu ändern.
Es gibt auch @RunIf Decorator implementiert, mit dem Sie Tests nur dann ausführen können, wenn bestimmte Bedingungen erfüllt sind, z. B. GPU verfügbar oder ein System nicht Windows. Siehe die Beispiele.
Sie können die Hyperparameter -Suche definieren, indem Sie eine neue Konfigurationsdatei zu configs/hparams_search hinzufügen.
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) python train.py -m hparams_search=mnist_optuna
Wenn Sie diesen Ansatz verwenden, müssen Sie kein Boilerplate zum Code hinzufügen, alles ist in einer einzelnen Konfigurationsdatei definiert. Das einzig notwendige ist, den optimierten Metrikwert aus der Startdatei zurückzugeben.
Sie können unterschiedliche Optimierungsrahmen verwenden, die in Hydra integriert sind, wie Optuna, AX oder Nevergrad.
Die optimization_results.yaml ist unter logs/task_name/multirun -Ordner verfügbar.
Dieser Ansatz unterstützt nicht die Wiederaufnahme unterbrochener Such- und erweiterte Techniken wie Prunning - Für ausgefeiltere Such- und Workflows sollten Sie wahrscheinlich eine dedizierte Optimierungsaufgabe schreiben (ohne Multirun -Funktion).
Die Vorlage wird mit CI -Workflows geliefert, die in GitHub -Aktionen implementiert sind:
.github/workflows/test.yaml : Führen Sie alle Tests mit PyTest aus.github/workflows/code-quality-main.yaml : Ausführen von Vorverbänden in der Hauptzweigung für alle Dateien.github/workflows/code-quality-pr.yaml : Ausführen von Pre-Commits auf Pull-Anforderungen nur für geänderte Dateien Lightning unterstützt mehrere Möglichkeiten, verteilte Schulungen durchzuführen. Am häufigsten ist DDP, das für jede GPU einen getrennten Prozess erzeugt und zwischen ihnen durchschnittlich Gradienten beträgt. Um über andere Ansätze zu erfahren, lesen Sie die Blitzdokumente.
Sie können DDP auf MNIST -Beispiel mit 4 GPUs wie folgt ausführen:
python train.py trainer=ddpHinweis : Wenn Sie DDP verwenden, müssen Sie vorsichtig sein, wie Sie Ihre Modelle schreiben - lesen Sie die Dokumente.
Der einfachste Weg ist, das Datamodule -Attribut direkt an das Modell zur Initialisierung zu übergeben:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )HINWEIS : Keine sehr robuste Lösung, da alle Ihre Datamodulen ein
some_param-Attribut verfügbar sind.
In ähnlicher Weise können Sie eine ganze DataModule -Konfiguration als Init -Parameter übergeben:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )Sie können auch einen DataModule -Konfigurationsparameter über variable Interpolation an Ihr Modell übergeben:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}Ein weiterer Ansatz besteht darin, über Trainer direkt über Datamodule in LightningModule zuzugreifen:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramHinweis : Dies funktioniert erst nach Beginn des Trainings, da der Trainer sonst noch nicht in LightningModule verfügbar ist.
Es ist normalerweise unnötig, die vollständige Anaconda -Umgebung zu installieren, Miniconda sollte ausreichen (Gewichte um 80 MB).
Ein großer Vorteil von Conda besteht darin, dass die Installation von Paketen ermöglicht, ohne dass bestimmte Compiler oder Bibliotheken im System verfügbar sind (da es vorkompilierte Binärdateien installiert). Daher erleichtert es häufig die Installation einiger Abhängigkeiten, z. B. Cudatoolkit für die GPU -Unterstützung.
Außerdem können Sie weltweit auf Ihre Umgebungen zugreifen, was möglicherweise bequemer ist, als für jedes Projekt eine neue lokale Umgebung zu schaffen.
Beispiel Installation:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shUpdate Conda:
conda update -n base -c defaults condaSchaffen Sie eine neue Conda -Umgebung:
conda create -n myenv python=3.10
conda activate myenv Verwenden Sie Pre-Commit-Hooks, um die Codeformatierung Ihres Projekts zu standardisieren und geistige Energie zu sparen.
Installieren Sie einfach das Paket vor dem Kommission mit:
pip install pre-commitInstallieren Sie als nächstes Hooks von .Pre-commit-config.yaml:
pre-commit installDanach wird Ihr Code automatisch in jedem neuen Commit neu formatiert.
So formatieren Sie alle Dateien im Projekt verwenden Sie den Befehl verwenden:
pre-commit run -aSo aktualisieren Sie Hook-Versionen in .pre-commit-config.yaml Verwendung:
pre-commit autoupdate Systemspezifische Variablen (z. B. absolute Pfade zu Datensätzen) sollten nicht unter der Versionskontrolle stehen, oder es führt zu Konflikten zwischen verschiedenen Benutzern. Ihre privaten Schlüssel sollten auch nicht versioniert werden, da Sie nicht möchten, dass sie durchgesickert werden.
Die Vorlage enthält .env.example -Datei, die als Beispiel dient. Erstellen Sie eine neue Datei namens .env (dieser Name wird von der Versionskontrolle in .GIitignore ausgeschlossen). Sie sollten es verwenden, um Umgebungsvariablen wie folgt zu speichern:
MY_VAR=/home/user/my_system_path
Alle Variablen von .env sind automatisch in train.py geladen.
Mithydra ermöglicht es Ihnen, auf jede Env -Variable in .yaml -Konfigurationen wie folgt zu verweisen:
path_to_data : ${oc.env:MY_VAR} Je nachdem, welchen Logger Sie verwenden, ist es oft nützlich, den metrischen Namen mit / Zeichen zu definieren:
self . log ( "train/loss" , loss )Auf diese Weise behandeln Holzfäller Ihre Metriken als zu verschiedenen Abschnitten, wodurch sie in der Benutzeroberfläche organisiert werden.
Verwenden Sie die offizielle TorchMetrics Library, um eine ordnungsgemäße Berechnung der Metriken sicherzustellen. Dies ist besonders wichtig für das Multi-GPU-Training!
Anstatt die Genauigkeit selbst zu berechnen, sollten Sie beispielsweise die angegebene Accuracy wie folgt verwenden:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...Verwenden Sie für jeden Schritt eine unterschiedliche Metrikinstanz, um die ordnungsgemäße Wertreduzierung bei allen GPU -Prozessen sicherzustellen.
TorchMetrics bietet Metriken für die meisten Anwendungsfälle wie F1 -Score oder Verwirrungsmatrix. Lesen Sie die Dokumentation für mehr.
Der Style Guide ist hier erhältlich.
Seien Sie explizit in Ihrem Init. Versuchen Sie, alle relevanten Standardeinstellungen zu definieren, damit der Benutzer nicht erraten muss. Geben Sie Type Tipps an. Auf diese Weise ist Ihr Modul für Projekte wiederverwendbar!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):Bewahren Sie die empfohlene Methodenreihenfolge auf.
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... Verwenden Sie DVC, um große Dateien wie Ihre Daten oder trainierten ML -Modelle zu steuern.
So initialisieren Sie das DVC -Repository:
dvc init Verwenden Sie, um eine Datei oder ein Verzeichnis zu verfolgen, um dvc add :
dvc add data/MNISTDVC speichert Informationen über die hinzugefügte Datei (oder ein Verzeichnis) in einer speziellen .dvc-Datei mit dem Namen Data/MNIST.dvc, einer kleinen Textdatei mit einem menschlich lesbaren Format. Diese Datei kann leicht wie Quellcode mit Git als Platzhalter für die ursprünglichen Daten versioniert werden:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " Es ermöglicht anderen Personen, Ihre Module einfach in ihren eigenen Projekten zu verwenden. Ändern Sie den Namen des src -Ordners in Ihren Projektnamen und vervollständigen Sie die Datei setup.py .
Jetzt kann Ihr Projekt aus lokalen Dateien installiert werden:
pip install -e .Oder direkt von Git Repository:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradeSo kann jede Datei problemlos in eine andere Datei wie SO importiert werden:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleEinige Konfigurationen sind Benutzer/Maschine/Installationspezifisch (z. B. Konfiguration des lokalen Clusters oder Harddrive -Pfade auf einer bestimmten Maschine). Für solche Szenarien kann eine Dateikonfiguration/local/Standard.yaml erstellt werden, die automatisch geladen, aber nicht von Git verfolgt wird.
Sie können es beispielsweise für eine Slurm -Cluster -Konfiguration verwenden:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd Diese Vorlage wurde inspiriert von:
Andere nützliche Repositories:
Lightning-Hydra-Template ist unter der MIT-Lizenz lizenziert.
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Löschen Sie alles oben für Ihr Projekt
Was es tut
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvZugmodell mit Standardkonfiguration
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuZugmodell mit ausgewählter Experimentkonfiguration aus Konfigurationen/Experiment/
python src/train.py experiment=experiment_name.yamlSie können jeden Parameter aus der Befehlszeile wie dieser überschreiben
python src/train.py trainer.max_epochs=20 data.batch_size=64

