hierarchical language modeling
1.0.0
เทมเพลตที่สะอาดเพื่อเริ่มต้นโครงการการเรียนรู้ลึกของคุณ⚡
คลิกที่ ใช้เทมเพลตนี้ เพื่อเริ่มต้นที่เก็บข้อมูลใหม่
คำแนะนำยินดีต้อนรับเสมอ!
ทำไมคุณถึงต้องการใช้:
✅บันทึกบนแผ่นหม้อไอน้ำ
เพิ่มรุ่นใหม่ชุดข้อมูลงานการทดลองและฝึกอบรมบนตัวเร่งความเร็วที่แตกต่างกันเช่นคลัสเตอร์ Multi-GPU, TPU หรือ Slurm
✅การศึกษา
แสดงความคิดเห็นอย่างละเอียด คุณสามารถใช้ repo นี้เป็นทรัพยากรการเรียนรู้
✅การใช้ซ้ำ
การรวบรวมเครื่องมือ MLOPS ที่มีประโยชน์การกำหนดค่าและตัวอย่างโค้ด คุณสามารถใช้ repo นี้เป็นข้อมูลอ้างอิงสำหรับสาธารณูปโภคต่างๆ
ทำไมคุณถึงไม่ต้องการใช้:
สิ่งต่างๆหยุดพักเป็นครั้งคราว
สายฟ้าและไฮดรายังคงพัฒนาและรวมห้องสมุดหลายแห่งซึ่งหมายความว่าบางครั้งสิ่งต่าง ๆ สำหรับรายการปัญหาที่รู้จักในปัจจุบันเยี่ยมชมหน้านี้
ไม่ได้ปรับสำหรับวิศวกรรมข้อมูล
เทมเพลตไม่ได้ถูกปรับสำหรับการสร้างท่อข้อมูลที่ขึ้นอยู่กับกันและกัน มันมีประสิทธิภาพมากขึ้นในการใช้สำหรับการสร้างต้นแบบแบบจำลองบนข้อมูลพร้อมใช้งาน
ใช้งานมากเกินไปกับกรณีการใช้งานง่าย ๆ
การตั้งค่าการกำหนดค่าถูกสร้างขึ้นด้วยการฝึกสายฟ้าอย่างง่าย คุณอาจต้องใช้ความพยายามในการปรับสำหรับกรณีการใช้งานที่แตกต่างกันเช่นผ้าฟ้าผ่า
อาจไม่สนับสนุนเวิร์กโฟลว์ของคุณ
ตัวอย่างเช่นคุณไม่สามารถดำเนินการค้นหา Multirun หรือ Hyperparameter ที่ใช้ไฮดราได้
หมายเหตุ : โปรดทราบว่านี่เป็นโครงการชุมชนที่ไม่เป็นทางการ
Pytorch Lightning - เสื้อคลุม Pytorch ที่มีน้ำหนักเบาสำหรับการวิจัย AI ประสิทธิภาพสูง คิดว่ามันเป็นกรอบสำหรับการจัดระเบียบรหัส pytorch ของคุณ
ไฮดรา - กรอบสำหรับการกำหนดค่าแอปพลิเคชันที่ซับซ้อนอย่างหรูหรา คุณลักษณะที่สำคัญคือความสามารถในการสร้างการกำหนดค่าแบบลำดับชั้นแบบไดนามิกโดยองค์ประกอบและแทนที่ผ่านไฟล์ config และบรรทัดคำสั่ง
โครงสร้างไดเรกทอรีของโครงการใหม่มีลักษณะเช่นนี้:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
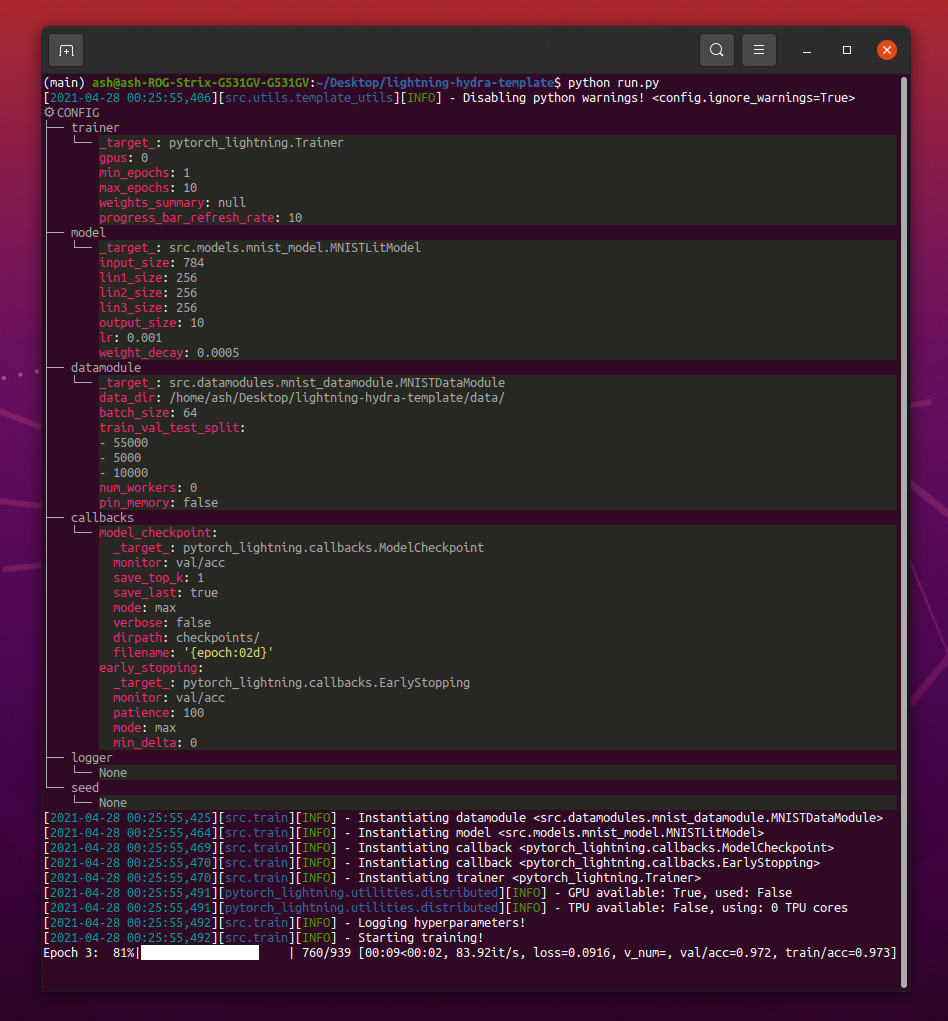
pip install -r requirements.txt เทมเพลตมีตัวอย่างที่มีการจำแนกประเภท MNIST
เมื่อใช้ python src/train.py คุณควรเห็นอะไรแบบนี้:
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4หมายเหตุ : คุณสามารถเพิ่มพารามิเตอร์ใหม่ด้วย
+Sign
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsคำเตือน : ขณะนี้มีปัญหาเกี่ยวกับโหมด DDP อ่านปัญหานี้เพื่อเรียนรู้เพิ่มเติม
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbหมายเหตุ : Lightning ให้การผสานรวมที่สะดวกกับเฟรมเวิร์กการบันทึกยอดนิยม เรียนรู้เพิ่มเติมที่นี่
หมายเหตุ : การใช้ WANDB ต้องการให้คุณตั้งค่าบัญชีก่อน หลังจากนั้นเสร็จสิ้นการกำหนดค่าดังต่อไปนี้
หมายเหตุ : คลิกที่นี่เพื่อดูตัวอย่างแดชบอร์ด Wandb ที่สร้างขึ้นด้วยเทมเพลตนี้
python train.py experiment=exampleหมายเหตุ : การกำหนดค่าการทดลองถูกวางไว้ใน configs/experiment/
python train.py callbacks=defaultหมายเหตุ : การโทรกลับสามารถใช้สำหรับสิ่งต่าง ๆ เช่นการตรวจสอบแบบจำลองการหยุดเร็วและอื่น ๆ อีกมากมาย
หมายเหตุ : การกำหนดค่าการเรียกกลับถูกวางไว้ใน configs/callbacks/
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"หมายเหตุ : Pytorch Lightning มีธงเทรนเนอร์ที่มีประโยชน์ประมาณ 40+
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2หมายเหตุ : เยี่ยมชม configs/ debug/ สำหรับการกำหนดค่าการดีบักที่แตกต่างกัน
python train.py ckpt_path="/path/to/ckpt/name.ckpt"หมายเหตุ : จุดตรวจสามารถเป็นเส้นทางหรือ URL
หมายเหตุ : ขณะนี้กำลังโหลด CKPT ไม่กลับมาทดสอบ Logger แต่จะได้รับการสนับสนุนใน Future Lightning Release
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"หมายเหตุ : จุดตรวจสามารถเป็นเส้นทางหรือ URL
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005หมายเหตุ : Hydra ประกอบด้วยการกำหนดค่าอย่างเกียจคร้านในเวลาเปิดงาน หากคุณเปลี่ยนรหัสหรือกำหนดค่าหลังจากเปิดงาน/กวาดการกำหนดค่าสุดท้ายอาจได้รับผลกระทบ
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleหมายเหตุ : การใช้ Optuna Sweeper ไม่ต้องการให้คุณเพิ่มหม้อไอน้ำใด ๆ ลงในรหัสของคุณทุกอย่างถูกกำหนดไว้ในไฟล์กำหนดค่าเดียว
คำเตือน : Optuna Sweeps ไม่ทนต่อความล้มเหลว (ถ้างานหนึ่งล่มการกวาดทั้งหมดก็ล่ม)
python train.py -m ' experiment=glob(*) 'หมายเหตุ : ไฮดราให้ไวยากรณ์พิเศษสำหรับการควบคุมพฤติกรรมของ multiruns เรียนรู้เพิ่มเติมที่นี่ คำสั่งด้านบนดำเนินการทดลองทั้งหมดจาก configs/experiment/
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]หมายเหตุ :
trainer.deterministic=Trueทำให้ pytorch กำหนดขึ้นได้มากขึ้น แต่ส่งผลกระทบต่อประสิทธิภาพ
หมายเหตุ : สิ่งนี้ควรจะทำได้ด้วยการกำหนดค่าอย่างง่ายโดยใช้ Ray AWS Launcher สำหรับ Hydra ตัวอย่างไม่ได้ใช้งานในเทมเพลตนี้
หมายเหตุ : Hydra ช่วยให้คุณสามารถแทนที่อาร์กิวเมนต์การกำหนดค่าการกำหนดค่าอัตโนมัติในเชลล์ในขณะที่คุณเขียนโดยกดปุ่ม
tabอ่านเอกสาร
pre-commit run -aหมายเหตุ : ใช้ตะขอล่วงหน้าเพื่อทำสิ่งต่าง ๆ เช่นรหัสการจัดรูปแบบอัตโนมัติและการกำหนดค่าดำเนินการวิเคราะห์รหัสหรือลบเอาต์พุตออกจากสมุดบันทึก Jupyter ดู # แนวทางปฏิบัติที่ดีที่สุดสำหรับข้อมูลเพิ่มเติม
อัปเดตรุ่น hook pre-commit ใน .pre-commit-config.yaml ด้วย:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "การทดสอบแต่ละครั้งควรติดแท็กเพื่อกรองไฟล์เหล่านั้นในไฟล์หรือใน UI ของ Logger:
python train.py tags=[ " mnist " , " experiment_X " ]หมายเหตุ : คุณอาจต้องหลบหนีอักขระวงเล็บในเชลล์ของคุณด้วย
python train.py tags=["mnist","experiment_X"]
หากไม่มีการให้แท็กคุณจะถูกขอให้ป้อนข้อมูลจากบรรทัดคำสั่ง:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):หากไม่มีการให้แท็กสำหรับ Multirun ข้อผิดพลาดจะถูกยกขึ้น:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !หมายเหตุ : รายการต่อท้ายจากบรรทัดคำสั่งไม่ได้รับการสนับสนุนใน Hydra :(
โครงการนี้มีอยู่ขอบคุณทุกคนที่มีส่วนร่วม
มีคำถาม? พบข้อผิดพลาด? ขาดคุณสมบัติเฉพาะ? อย่าลังเลที่จะยื่นปัญหาใหม่การสนทนาหรือการประชาสัมพันธ์ที่มีชื่อและคำอธิบายที่เกี่ยวข้อง
ก่อนที่จะมีปัญหาโปรดตรวจสอบว่า:
main ปัจจุบันคำแนะนำสำหรับการปรับปรุงยินดีต้อนรับเสมอ!
โมดูล Lightning Pytorch ทั้งหมดจะถูกสร้างอินสแตนซ์แบบไดนามิกจากเส้นทางโมดูลที่ระบุในการกำหนดค่า ตัวอย่างการกำหนดค่าโมเดล:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10การใช้การกำหนดค่านี้เราสามารถสร้างอินสแตนซ์วัตถุด้วยบรรทัดต่อไปนี้:
model = hydra . utils . instantiate ( config . model ) สิ่งนี้ช่วยให้คุณวนซ้ำรุ่นใหม่ได้อย่างง่ายดาย! ทุกครั้งที่คุณสร้างใหม่เพียงแค่ระบุพา ธ โมดูลและพารามิเตอร์ในไฟล์กำหนดค่าที่เหมาะสม
สลับระหว่างโมเดลและ DataModules พร้อมอาร์กิวเมนต์บรรทัดคำสั่ง:
python train.py model=mnistตัวอย่างไปป์ไลน์การจัดการลอจิกอินสแตนซ์: src/train.py
สถานที่: configs/train.yaml
การกำหนดค่าโครงการหลักประกอบด้วยการกำหนดค่าการฝึกอบรมเริ่มต้น
มันกำหนดวิธีการกำหนดค่าเมื่อเพียงแค่ดำเนินการคำสั่ง python train.py
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null สถานที่: configs/experiment
การกำหนดค่าการทดลองช่วยให้คุณสามารถเขียนทับพารามิเตอร์จากการกำหนดค่าหลัก
ตัวอย่างเช่นคุณสามารถใช้กับพารามิเตอร์ที่ดีที่สุดในการควบคุมรุ่นที่ดีที่สุดสำหรับแต่ละชุดรูปแบบและชุดข้อมูล
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " เวิร์กโฟลว์พื้นฐาน
python src/train.py experiment=experiment_name.yamlการออกแบบการทดลอง
สมมติว่าคุณต้องการดำเนินการวิ่งหลายครั้งเพื่อพล็อตความแม่นยำของการเปลี่ยนแปลงที่เกี่ยวกับขนาดแบทช์
ดำเนินการรันด้วยพารามิเตอร์การกำหนดค่าบางอย่างที่ช่วยให้คุณสามารถระบุได้อย่างง่ายดายเช่นแท็ก:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] เขียนสคริปต์หรือโน้ตบุ๊กที่ค้นหา logs/ โฟลเดอร์และดึงบันทึก CSV จากการรันที่มีแท็กที่กำหนดในการกำหนดค่า พล็อตผลลัพธ์
ไฮดราสร้างไดเรกทอรีเอาต์พุตใหม่สำหรับการรันที่ดำเนินการทุกครั้ง
โครงสร้างการบันทึกเริ่มต้น:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
คุณสามารถเปลี่ยนโครงสร้างนี้ได้โดยการปรับเปลี่ยนเส้นทางในการกำหนดค่าไฮดรา
Pytorch Lightning รองรับเฟรมเวิร์กการบันทึกยอดนิยมมากมาย: น้ำหนักและอคติ, ดาวเนปจูน, ดาวหาง, MLFlow, Tensorboard
เครื่องมือเหล่านี้ช่วยให้คุณติดตามพารามิเตอร์และตัวชี้วัดเอาต์พุตและช่วยให้คุณเปรียบเทียบและแสดงภาพผลลัพธ์ หากต้องการใช้หนึ่งในนั้นเพียงแค่เสร็จสิ้นการกำหนดค่าใน configs/logger และเรียกใช้:
python train.py logger=logger_nameคุณสามารถใช้จำนวนมากในครั้งเดียว (ดู configs/logger/many_loggers.yaml)
คุณยังสามารถเขียนเครื่องบันทึกของคุณเอง
Lightning ให้วิธีที่สะดวกสำหรับการบันทึกตัวชี้วัดที่กำหนดเองจากด้านใน LightningModule อ่านเอกสารหรือดูตัวอย่าง MNIST
เทมเพลตมาพร้อมกับการทดสอบทั่วไปที่ใช้กับ pytest
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "การทดสอบที่ใช้งานส่วนใหญ่ไม่ได้ตรวจสอบผลลัพธ์ที่เฉพาะเจาะจงใด ๆ - มีอยู่เพียงแค่ตรวจสอบว่าการดำเนินการคำสั่งบางอย่างไม่ได้จบลงในการโยนข้อยกเว้น คุณสามารถดำเนินการได้นาน ๆ ครั้งเพื่อเร่งการพัฒนา
ปัจจุบันการทดสอบครอบคลุมกรณีเช่น:
และอื่น ๆ อีกมากมาย คุณควรจะสามารถแก้ไขได้อย่างง่ายดายสำหรับกรณีการใช้งานของคุณ
นอกจากนี้ยังมี @RunIf Decorator ที่นำมาใช้ซึ่งช่วยให้คุณสามารถทำการทดสอบได้เฉพาะในกรณีที่มีเงื่อนไขบางประการเช่น GPU พร้อมใช้งานหรือระบบไม่ใช่ Windows ดูตัวอย่าง
คุณสามารถกำหนดการค้นหา hyperparameter โดยเพิ่มไฟล์กำหนดค่าใหม่ลงใน configs/hparams_search
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) ถัดไปดำเนินการด้วย: python train.py -m hparams_search=mnist_optuna
การใช้วิธีนี้ไม่จำเป็นต้องเพิ่มรหัสหม้อไอน้ำลงในรหัสทุกอย่างถูกกำหนดไว้ในไฟล์กำหนดค่าเดียว สิ่งเดียวที่จำเป็นคือการส่งคืนค่าตัวชี้วัดที่ดีที่สุดจากไฟล์เปิดตัว
คุณสามารถใช้เฟรมเวิร์กการเพิ่มประสิทธิภาพที่แตกต่างกันซึ่งรวมเข้ากับไฮดราเช่น Optuna, AX หรือ Nevergrad
optimization_results.yaml _results.yaml จะพร้อมใช้งานภายใต้โฟลเดอร์ logs/task_name/multirun
วิธีการนี้ไม่สนับสนุนการค้นหาการค้นหาที่ถูกขัดจังหวะและเทคนิคขั้นสูงเช่น Prunning - สำหรับการค้นหาและเวิร์กโฟลว์ที่ซับซ้อนยิ่งขึ้นคุณควรเขียนงานการเพิ่มประสิทธิภาพโดยเฉพาะ (ไม่มีคุณสมบัติ Multirun)
เทมเพลตมาพร้อมกับเวิร์กโฟลว์ CI ที่ใช้ในการกระทำของ GitHub:
.github/workflows/test.yaml : รันการทดสอบทั้งหมดด้วย pytest.github/workflows/code-quality-main.yaml.github/workflows/code-quality-pr.yaml : การรันคำสั่งล่วงหน้าในคำขอดึงสำหรับไฟล์ที่แก้ไขเท่านั้น สายฟ้ารองรับการฝึกอบรมแบบกระจายหลายวิธี สิ่งที่พบบ่อยที่สุดคือ DDP ซึ่งวางไข่กระบวนการแยกต่างหากสำหรับแต่ละ GPU และค่าเฉลี่ยการไล่ระดับสีระหว่างพวกเขา เพื่อเรียนรู้เกี่ยวกับวิธีการอื่น ๆ อ่านเอกสารสายฟ้า
คุณสามารถเรียกใช้ DDP ในตัวอย่าง MNIST ด้วย 4 GPU เช่นนี้:
python train.py trainer=ddpหมายเหตุ : เมื่อใช้ DDP คุณต้องระวังวิธีการเขียนแบบจำลองของคุณ - อ่านเอกสาร
วิธีที่ง่ายที่สุดคือการผ่านแอตทริบิวต์ DataModule โดยตรงไปยังโมเดลในการเริ่มต้น:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )หมายเหตุ : ไม่ใช่วิธีแก้ปัญหาที่แข็งแกร่งมากเนื่องจากจะถือว่า DataModules ทั้งหมดของคุณมีแอตทริบิวต์
some_param
ในทำนองเดียวกันคุณสามารถผ่าน dataModule config ทั้งหมดเป็นพารามิเตอร์ init:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )นอกจากนี้คุณยังสามารถส่งพารามิเตอร์ dataModule config ไปยังโมเดลของคุณผ่านการแก้ไขตัวแปร:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}อีกวิธีหนึ่งคือการเข้าถึง DataModule ใน LightningModule โดยตรงผ่าน Trainer:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramหมายเหตุ : สิ่งนี้ใช้งานได้หลังจากการฝึกอบรมเริ่มต้นขึ้นเนื่องจากมิฉะนั้นผู้ฝึกสอนจะไม่สามารถใช้งานได้ใน LightningModule
โดยปกติแล้วจะไม่จำเป็นต้องติดตั้งสภาพแวดล้อม Anaconda เต็มรูปแบบ Miniconda ควรจะเพียงพอ (น้ำหนักประมาณ 80MB)
ข้อได้เปรียบที่ยิ่งใหญ่ของ Conda คืออนุญาตให้ติดตั้งแพ็คเกจโดยไม่ต้องใช้คอมไพเลอร์หรือไลบรารีบางอย่างในระบบ (เนื่องจากติดตั้งไบนารีที่คอมไพล์ล่วงหน้า) ดังนั้นจึงมักจะทำให้ง่ายต่อการติดตั้งการอ้างอิงบางอย่างเช่น cudatoolkit สำหรับการสนับสนุน GPU
นอกจากนี้ยังช่วยให้คุณเข้าถึงสภาพแวดล้อมของคุณทั่วโลกซึ่งอาจสะดวกกว่าการสร้างสภาพแวดล้อมในท้องถิ่นใหม่สำหรับทุกโครงการ
การติดตั้งตัวอย่าง:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shอัปเดต Conda:
conda update -n base -c defaults condaสร้างสภาพแวดล้อม conda ใหม่:
conda create -n myenv python=3.10
conda activate myenv ใช้ตะขอล่วงหน้าเพื่อสร้างมาตรฐานการจัดรูปแบบรหัสของโครงการของคุณและประหยัดพลังงานจิต
เพียงติดตั้งแพ็คเกจล่วงหน้าพร้อม:
pip install pre-commitถัดไปติดตั้ง hooks จาก. pre-config.yaml:
pre-commit installหลังจากนั้นรหัสของคุณจะได้รับการปรับปรุงใหม่โดยอัตโนมัติในการกระทำใหม่ทุกครั้ง
หากต้องการฟอร์แมตไฟล์ทั้งหมดในคำสั่งใช้โครงการ:
pre-commit run -aหากต้องการอัปเดตเวอร์ชัน Hook ใน. pre-config.yaml ใช้:
pre-commit autoupdate ตัวแปรเฉพาะของระบบ (เช่นเส้นทางสัมบูรณ์ไปยังชุดข้อมูล) ไม่ควรอยู่ภายใต้การควบคุมเวอร์ชันหรือจะส่งผลให้เกิดความขัดแย้งระหว่างผู้ใช้ที่แตกต่างกัน คีย์ส่วนตัวของคุณไม่ควรมีการปรับรุ่นเนื่องจากคุณไม่ต้องการให้พวกเขารั่วไหลออกมา
เทมเพลตมีไฟล์ .env.example ซึ่งทำหน้าที่เป็นตัวอย่าง สร้างไฟล์ใหม่ที่เรียกว่า .env (ชื่อนี้ไม่รวมออกจากตัวควบคุมเวอร์ชันใน. Gitignore) คุณควรใช้สำหรับการจัดเก็บตัวแปรสภาพแวดล้อมเช่นนี้:
MY_VAR=/home/user/my_system_path
ตัวแปรทั้งหมดจาก .env จะถูกโหลดใน train.py โดยอัตโนมัติ
Hydra ช่วยให้คุณสามารถอ้างอิงตัวแปร env ใด ๆ ใน .yaml configs เช่นนี้:
path_to_data : ${oc.env:MY_VAR} ขึ้นอยู่กับว่าคุณใช้เครื่องบันทึกแบบใดมักจะมีประโยชน์ในการกำหนดชื่อตัวชี้วัดด้วย / อักขระ:
self . log ( "train/loss" , loss )วิธีนี้คนตัดไม้จะปฏิบัติต่อตัวชี้วัดของคุณว่าเป็นส่วนต่าง ๆ ซึ่งช่วยให้พวกเขาจัดระเบียบใน UI
ใช้ห้องสมุด Torchmetrics อย่างเป็นทางการเพื่อให้แน่ใจว่าการคำนวณตัวชี้วัดที่เหมาะสม นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับการฝึกอบรมหลาย GPU!
ตัวอย่างเช่นแทนที่จะคำนวณความถูกต้องด้วยตัวเองคุณควรใช้คลาส Accuracy ที่ให้เช่นนี้:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...ตรวจสอบให้แน่ใจว่าใช้อินสแตนซ์การวัดที่แตกต่างกันสำหรับแต่ละขั้นตอนเพื่อให้แน่ใจว่าการลดค่าที่เหมาะสมสำหรับกระบวนการ GPU ทั้งหมด
Torchmetrics ให้การวัดสำหรับกรณีการใช้งานส่วนใหญ่เช่นคะแนน F1 หรือเมทริกซ์ความสับสน อ่านเอกสารสำหรับข้อมูลเพิ่มเติม
คู่มือสไตล์มีให้ที่นี่
ชัดเจนใน init ของคุณ พยายามกำหนดค่าเริ่มต้นที่เกี่ยวข้องทั้งหมดเพื่อให้ผู้ใช้ไม่ต้องเดา ให้คำแนะนำประเภท วิธีนี้โมดูลของคุณสามารถนำกลับมาใช้ใหม่ได้ในโครงการ!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):รักษาลำดับวิธีที่แนะนำ
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... ใช้ DVC เป็นรุ่นควบคุมไฟล์ขนาดใหญ่เช่นข้อมูลของคุณหรือรุ่น ML ที่ผ่านการฝึกอบรม
เพื่อเริ่มต้นที่เก็บข้อมูล DVC:
dvc init ในการเริ่มติดตามไฟล์หรือไดเรกทอรีให้ใช้ dvc add :
dvc add data/MNISTDVC เก็บข้อมูลเกี่ยวกับไฟล์ที่เพิ่มเข้ามา (หรือไดเรกทอรี) ในไฟล์. dvc พิเศษชื่อ data/mnist.dvc ไฟล์ข้อความขนาดเล็กที่มีรูปแบบที่มนุษย์อ่านได้ ไฟล์นี้สามารถเวอร์ชันได้อย่างง่ายดายเช่นซอร์สโค้ดที่มี Git เป็นตัวยึดตำแหน่งสำหรับข้อมูลต้นฉบับ:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " ช่วยให้คนอื่นใช้โมดูลของคุณในโครงการของตนเองได้อย่างง่ายดาย เปลี่ยนชื่อของโฟลเดอร์ src เป็นชื่อโครงการของคุณและกรอกไฟล์ setup.py
ตอนนี้โครงการของคุณสามารถติดตั้งได้จากไฟล์ท้องถิ่น:
pip install -e .หรือโดยตรงจากที่เก็บ Git:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradeดังนั้นไฟล์ใด ๆ ที่สามารถนำเข้าได้อย่างง่ายดายในไฟล์อื่น ๆ เช่น:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleการกำหนดค่าบางอย่างคือผู้ใช้/เครื่อง/การติดตั้งเฉพาะ (เช่นการกำหนดค่าของคลัสเตอร์ท้องถิ่นหรือเส้นทางฮาร์ดไดรฟ์บนเครื่องเฉพาะ) สำหรับสถานการณ์ดังกล่าวสามารถสร้างไฟล์/local/default.yaml ซึ่งสามารถสร้างได้ซึ่งโหลดโดยอัตโนมัติ แต่ไม่ได้ติดตามโดย Git
ตัวอย่างเช่นคุณสามารถใช้สำหรับการกำหนดค่าคลัสเตอร์ slurm:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd เทมเพลตนี้ได้รับแรงบันดาลใจจาก:
ที่เก็บที่มีประโยชน์อื่น ๆ :
Lightning-Hydra-Template ได้รับอนุญาตภายใต้ใบอนุญาต MIT
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
ลบทุกอย่างด้านบนสำหรับโครงการของคุณ
มันทำอะไร
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvรุ่นรถไฟที่มีการกำหนดค่าเริ่มต้น
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuโมเดลรถไฟที่มีการกำหนดค่าการทดลองที่เลือกจาก configs/experiment/
python src/train.py experiment=experiment_name.yamlคุณสามารถแทนที่พารามิเตอร์ใด ๆ จากบรรทัดคำสั่งเช่นนี้
python src/train.py trainer.max_epochs=20 data.batch_size=64

