hierarchical language modeling
1.0.0
Чистый шаблон для начала вашего проекта глубокого обучения ⚡
Нажмите на использование этого шаблона , чтобы инициализация нового репозитория.
Предложения всегда приветствуются!
Почему вы можете его использовать:
✅ Сохранить на шаблоне
Легко добавлять новые модели, наборы данных, задачи, эксперименты и тренироваться на разных ускорителях, таких как кластеры с несколькими GPU, TPU или Slurm.
✅ Образование
Тщательно прокомментировал. Вы можете использовать этот репо в качестве учебного ресурса.
✅ Способность повторного использования
Сбор полезных инструментов, конфигураций и фрагментов кода MLOPS. Вы можете использовать этот репо в качестве ссылки для различных утилит.
Почему вы, возможно, не захотите использовать его:
Время от времени разбивается
Lightning и Hydra все еще развиваются и интегрируют многие библиотеки, что означает, что иногда все сломается. Для списка известных проблем посетите эту страницу.
Не скорректирован для разработки данных
Шаблон на самом деле не скорректирован для создания трубопроводов данных, которые зависят друг от друга. Это более эффективно использовать его для прототипирования модели для готовых к использованию данных.
Переполнен простым вариантом использования
Настройка конфигурации построена с учетом простого обучения молнии. Возможно, вам придется приложить некоторые усилия, чтобы настроить его для различных вариантов использования, например, молнии.
Может не поддерживать ваш рабочий процесс
Например, вы не можете возобновить поиск по мультирунскому или гиперпараметру на основе Hydra.
Примечание : имейте в виду, что это неофициальный проект сообщества.
Pytorch Lightning - легкая обертка Pytorch для высокопроизводительных исследований ИИ. Думайте об этом как о рамке для организации вашего кода Pytorch.
Hydra - структура для элегантной настройки сложных приложений. Ключевой функцией является возможность динамического создания иерархической конфигурации путем композиции и переопределить ее через файлы конфигурации и командную строку.
Структура каталогов нового проекта выглядит следующим образом:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt Шаблон содержит пример с классификацией MNIST.
При запуске python src/train.py вы должны увидеть что -то вроде этого:
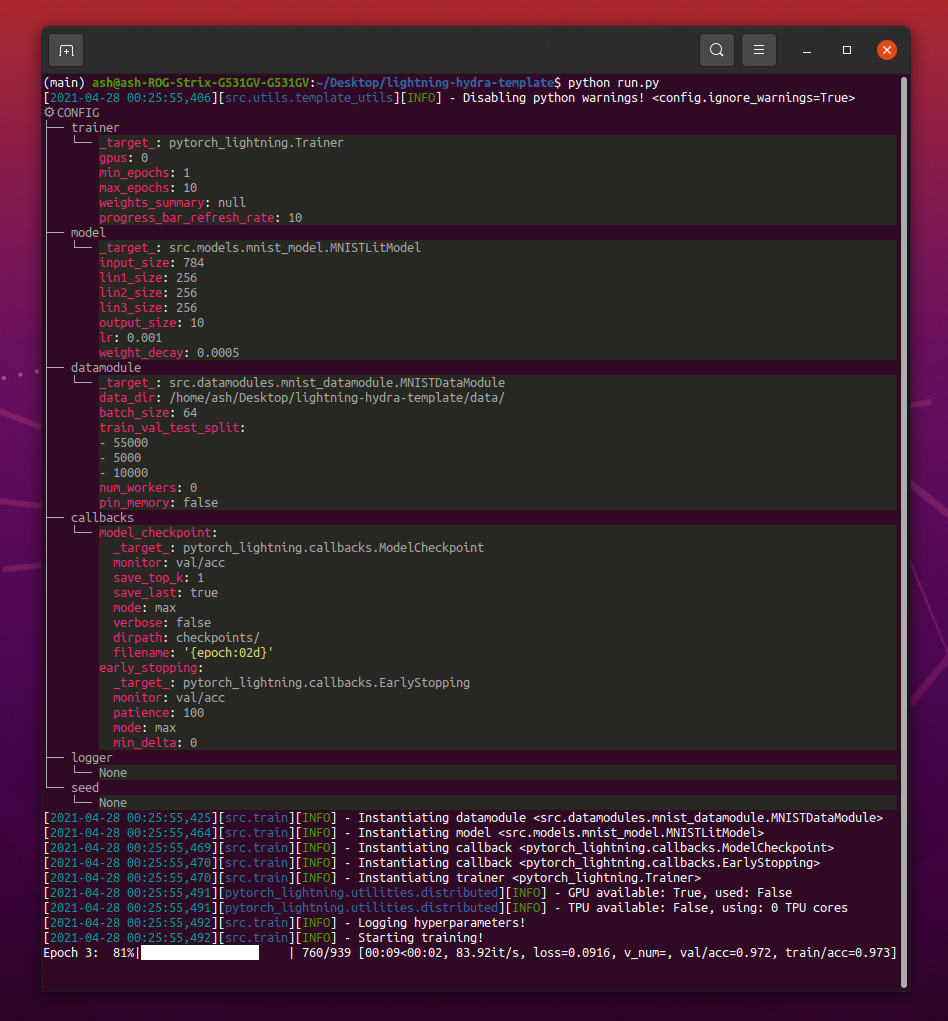
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4Примечание . Вы также можете добавить новые параметры с
+знак.
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsПредупреждение : в настоящее время существуют проблемы с режимом DDP, прочитайте эту проблему, чтобы узнать больше.
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbПримечание : Lightning обеспечивает удобную интеграцию с самыми популярными рамками журнала. Узнайте больше здесь.
Примечание . Использование WANDB требует сначала настроить учетную запись. После этого просто заполните конфигурацию, как показано ниже.
ПРИМЕЧАНИЕ . Нажмите здесь, чтобы увидеть пример панели инструментов Wandb, сгенерированной этим шаблоном.
python train.py experiment=exampleПРИМЕЧАНИЕ . Конфигурации экспериментов помещаются в конфигурации/эксперимент/.
python train.py callbacks=defaultПРИМЕЧАНИЕ . Образные вызовы могут использоваться для таких вещей, как модель контрольно -пропускной пункты, ранняя остановка и многое другое.
ПРИМЕЧАНИЕ . Конфигурации обратных вызовов размещены в конфигурации/обратные вызовы/.
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"ПРИМЕЧАНИЕ . Pytorch Lightning предоставляет около 40+ полезных тренажеров.
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2Примечание . Посетите конфигурации/ отладку/ для различных конфигураций отладки.
python train.py ckpt_path="/path/to/ckpt/name.ckpt"Примечание . Контрольная точка может быть либо путем, либо URL.
Примечание . В настоящее время загрузка CKPT не возобновит эксперимент с регистратором, но он будет поддерживаться в будущем Lightning Release.
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"Примечание . Контрольная точка может быть либо путем, либо URL.
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005Примечание : Hydra сочиняет конфигурации лениво во время запуска работы. Если вы измените код или конфигурации после запуска задания/развертки, можно повлиять на конечные конфигурации.
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleПРИМЕЧАНИЕ . Использование Optuna Sweeper не требует, чтобы вы добавляли какую -либо шейку для вашего кода, все определено в одном файле конфигурации.
ПРЕДУПРЕЖДЕНИЕ : Optuna Sweeps не устойчивы к неудаче (если одна задача вылетает, то весь разверток вылетает).
python train.py -m ' experiment=glob(*) 'Примечание . Hydra предоставляет специальный синтаксис для контроля поведения мультирунцев. Узнайте больше здесь. Приведенная выше команда выполняет все эксперименты из Configs/Experiment/.
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]ПРИМЕЧАНИЕ :
trainer.deterministic=Trueделает питор более детерминированным, но влияет на производительность.
Примечание . Это должно быть достижимо с помощью простой конфигурации, используя запуск Ray AWS для Hydra. Пример не реализован в этом шаблоне.
ПРИМЕЧАНИЕ . Hydra позволяет вам автоматически заполнить аргумент конфигурации переопределяется в оболочке при их записи, нажав клавишу
tab. Прочитайте документы.
pre-commit run -aПРИМЕЧАНИЕ . Примените предварительные крючки для выполнения таких вещей, как автоматический код и конфигурации, выполнение анализа кода или удаление выводов из ноутбуков Jupyter. Смотрите # лучшие практики для большего.
Обновить версии предварительного крючка в .pre-commit-config.yaml с:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Каждый эксперимент должен быть помечен, чтобы легко фильтровать их по файлам или в пользовательском интерфейсе logger:
python train.py tags=[ " mnist " , " experiment_X " ]Примечание . Возможно, вам понадобится избежать персонажей кронштейнов в вашей оболочке с
python train.py tags=["mnist","experiment_X"].
Если тегов не предоставлены, вам будет предложено ввести их из командной строки:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):Если для Multirun не предусмотрены теги, будет выдвинута ошибка:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !Примечание . Дополнительные списки из командной строки в настоящее время не поддерживаются в Hydra :(
Этот проект существует благодаря всем людям, которые вносят свой вклад.
Есть вопрос? Нашел ошибку? Отсутствует определенная функция? Не стесняйтесь подать новую проблему, обсуждение или PR с соответствующим названием и описанием.
Прежде чем решить проблему, убедитесь, что:
main ветви.Предложения по улучшениям всегда приветствуются!
Все модули молнии Pytorch динамически создаются из путей модуля, указанных в Config. Пример конфигурации модели:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10Используя эту конфигурацию, мы можем создать экземпляр объекта со следующей строкой:
model = hydra . utils . instantiate ( config . model ) Это позволяет вам легко итерации по новым моделям! Каждый раз, когда вы создаете новый, просто укажите его путь и параметры модуля в соответствующем файле конфигурации.
Переключать между моделями и датамодулами с аргументами командной строки:
python train.py model=mnistПример трубопровода, управляющий логикой экземпляров: src/train.py.
Местоположение: configs/train.yaml
Основная конфигурация проекта содержит конфигурацию обучения по умолчанию.
Он определяет, как конфигурация составлена при простой выполнении команды python train.py .
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null Местоположение: конфигурации/эксперимент
Конфигурации эксперимента позволяют перезаписать параметры из основной конфигурации.
Например, вы можете использовать их для контроля версий лучших гиперпараметров для каждой комбинации модели и набора данных.
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " Основной рабочий процесс
python src/train.py experiment=experiment_name.yamlДизайн эксперимента
Скажем, вы хотите выполнить много пробежек, чтобы построить то, как изменяется точность в отношении размера партии.
Выполните выполнения с некоторым параметром конфигурации, который позволяет легко идентифицировать их, например, теги:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] Напишите сценарий или ноутбук, который ищет logs/ папку и получает журналы CSV из выполнения, содержащих заданные теги в config. Построить результаты.
Hydra создает новый выходной каталог для каждого выполненного запуска.
Структура ведения журнала по умолчанию:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
Вы можете изменить эту структуру, изменяя пути в конфигурации Hydra.
Pytorch Lightning поддерживает многие популярные фреймворки журнала: веса и предвзятость, Нептун, Комета, Mlflow, Tensorboard.
Эти инструменты помогут вам отслеживать гиперпараметры и выходные метрики и позволяют сравнить и визуализировать результаты. Чтобы использовать один из них, просто завершите его конфигурацию в конфигурации/журнале и запустите:
python train.py logger=logger_nameВы можете использовать многие из них одновременно (см. Например, Configs/logger/many_loggers.yaml).
Вы также можете написать свой собственный регистратор.
Lightning предоставляет удобный метод для регистрации пользовательских метрик изнутри LightningModule. Прочитайте документы или посмотрите на пример MNIST.
Шаблон поставляется с общими тестами, реализованными с помощью pytest .
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Большинство реализованных тестов не проверяют какой -либо конкретный вывод - они существуют, чтобы просто проверить, что выполнение некоторых команд не в конечном итоге бросает исключения. Вы можете выполнять их время от времени, чтобы ускорить разработку.
В настоящее время тесты охватывают случаи, такие как:
И многие другие. Вы должны быть в состоянии легко изменить их для вашего варианта использования.
Существует также реализован @RunIf Decorator, который позволяет запускать тесты, только если выполнены определенные условия, например, GPU или система не является Windows. Смотрите примеры.
Вы можете определить поиск гиперпараметра, добавив новый файл конфигурации в configs/hparams_search.
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) Далее, выполните его с: python train.py -m hparams_search=mnist_optuna
Использование этого подхода не требует добавления какого -либо шаблона в код, все определено в одном файле конфигурации. Единственная необходимая вещь - вернуть оптимизированное метрическое значение из файла запуска.
Вы можете использовать различные структуры оптимизации, интегрированные с Hydra, такие как Optuna, AX или NeverGrad.
optimization_results.yaml будет доступен в папке logs/task_name/multirun .
Этот подход не подтверждает возобновление прерывавшихся поисковых и передовых методов, таких как Prunning - для более сложных поисковых и рабочих процессов, вы, вероятно, должны написать специальную задачу оптимизации (без функции MultiRun).
Шаблон поставляется с рабочими процессами CI, реализованными в действиях GitHub:
.github/workflows/test.yaml : запуск всех тестов с pytest.github/workflows/code-quality-main.yaml : Запуск предварительных обязательств в основной филиале для всех файлов.github/workflows/code-quality-pr.yaml : запуск предварительных компаний по запросам только для измененных файлов Молния поддерживает несколько способов проведения распределенного обучения. Наиболее распространенным является DDP, который порождает отдельный процесс для каждого графического процессора и средние градиенты между ними. Чтобы узнать о других подходах, прочитайте документы Lightning.
Вы можете запустить DDP на примере MNIST с 4 графическими процессорами, как это:
python train.py trainer=ddpПримечание . При использовании DDP вы должны быть осторожны с тем, как писать свои модели - прочитайте документы.
Самый простой способ - передавать атрибут DataModule непосредственно на модель при инициализации:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )Примечание . Не очень надежное решение, поскольку оно предполагает, что все ваши данные DataModules имеют
some_paramатрибут.
Точно так же вы можете передать целую конфигурацию Datamodule в качестве параметра инициации:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )Вы также можете передать параметр конфигурации DataModule в вашу модель через интерполяцию переменной:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}Другой подход заключается в доступе к DataModule в LightningModule непосредственно через тренер:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramПримечание : это работает только после начала тренировок, так как тренер в противном случае не будет доступен в LightningModule.
Обычно не нужно устанавливать полную среду Anaconda, Miniconda должно быть достаточно (веса около 80 МБ).
Большое преимущество Conda заключается в том, что он позволяет устанавливать пакеты, не требуя, чтобы определенные компиляторы или библиотеки были доступны в системе (поскольку он устанавливает предварительно скомпилированные двоичные файлы), поэтому часто облегчает установку некоторых зависимостей, например, Cudatoolkit для поддержки графических процессоров.
Это также позволяет вам получить доступ к вашей среде по всему миру, что может быть более удобным, чем создание новой локальной среды для каждого проекта.
Пример установки:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shОбновить Conda:
conda update -n base -c defaults condaСоздайте новую среду Conda:
conda create -n myenv python=3.10
conda activate myenv Используйте предварительные крючки для стандартизации форматирования кода вашего проекта и сохранить умственную энергию.
Просто установите предварительный пакет с:
pip install pre-commitЗатем установите крючки от .pre-commit-config.yaml:
pre-commit installПосле этого ваш код будет автоматически переформатирован на каждом новом коммите.
Переформатировать все файлы в команде использования проекта:
pre-commit run -aЧтобы обновить версии крюка в .pre-commit-config.yaml Использование:
pre-commit autoupdate Системные переменные (например, абсолютные пути к наборам данных) не должны находиться под управлением версий, или это приведет к конфликту между различными пользователями. Ваши личные ключи также не должны быть версированы, так как вы не хотите, чтобы их просочились.
Шаблон содержит файл .env.example , который служит примером. Создайте новый файл с именем .env (это имя исключено из управления версией в .gitignore). Вы должны использовать его для хранения переменных среды, как это:
MY_VAR=/home/user/my_system_path
Все переменные от .env загружаются в train.py автоматически.
Hydra позволяет ссылаться на любую переменную env в .yaml
path_to_data : ${oc.env:MY_VAR} В зависимости от того, какой регистратор вы используете, часто полезно определить метрическое имя с помощью / символом:
self . log ( "train/loss" , loss )Таким образом, регистраторы будут рассматривать ваши метрики как принадлежащие различным разделам, что помогает их организовать в пользовательском интерфейсе.
Используйте официальную библиотеку Torchmetrics, чтобы обеспечить надлежащий расчет метрик. Это особенно важно для обучения мульти-GPU!
Например, вместо того, чтобы вычислять точность самостоятельно, вы должны использовать предоставленный класс Accuracy как это:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...Обязательно используйте различные метрические экземпляры для каждого шага, чтобы обеспечить правильное снижение значения по всем процессам графического процессора.
Torchmetrics предоставляет метрики для большинства вариантов использования, таких как оценка F1 или матрица путаницы. Прочитайте документацию для большего.
Руководство по стилю доступно здесь.
Будьте явными в своем инициировании. Попробуйте определить все соответствующие значения по умолчанию, чтобы пользователь не должен был догадаться. Обеспечить подсказки типа. Таким образом, ваш модуль многоразовый для проектов!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):Сохранить рекомендуемый порядок метода.
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... Используйте DVC для управления большими файлами версий, таких как ваши данные или обученные модели ML.
Для инициализации репозитория DVC:
dvc init Чтобы начать отслеживать файл или каталог, используйте dvc add :
dvc add data/MNISTDVC хранит информацию о добавленном файле (или каталоге) в специальном файле .DVC с именем DATA/MNIST.DVC, небольшим текстовым файлом с читаемым человеком форматом. Этот файл можно легко версировать, как исходный код с GIT, в качестве заполнителя для исходных данных:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " Это позволяет другим людям легко использовать ваши модули в своих собственных проектах. Измените имя папки src на имя вашего проекта и заполните файл setup.py .
Теперь ваш проект может быть установлен из локальных файлов:
pip install -e .Или непосредственно из репозитория GIT:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradeТаким образом, любой файл может быть легко импортирован в любой другой файл, как так:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleНекоторые конфигурации являются специфичными для пользователя/машины/установки (например, конфигурация локального кластера или пути жестких потоков на определенной машине). Для таких сценариев можно создать файл configs/local/default.yaml, который автоматически загружается, но не отслеживается GIT.
Например, вы можете использовать его для конфигурации Slurm Cluster:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd Этот шаблон был вдохновлен:
Другие полезные хранилища:
Lightning-Hydra-Template лицензирован по лицензии MIT.
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Удалить все выше для вашего проекта
Что он делает
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvМодель поезда с конфигурацией по умолчанию
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuМодель поезда с выбранной конфигурацией эксперимента из конфигураций/эксперимент/
python src/train.py experiment=experiment_name.yamlВы можете переопределить любой параметр из командной строки, подобной этой
python src/train.py trainer.max_epochs=20 data.batch_size=64

