hierarchical language modeling
1.0.0
Un modèle propre pour lancer votre projet d'apprentissage en profondeur ⚡
Cliquez sur Utiliser ce modèle pour initialiser le nouveau référentiel.
Les suggestions sont toujours les bienvenues!
Pourquoi vous voudrez peut-être l'utiliser:
✅ Économiser sur la plaque de passerelle
Ajoutez facilement de nouveaux modèles, ensembles de données, tâches, expériences et s'entraîner sur différents accélérateurs, comme les grappes multi-GPU, TPU ou Slurm.
✅ Éducation
Bien commenté. Vous pouvez utiliser ce dépôt comme ressource d'apprentissage.
✅ Réutilisabilité
Collection d'outils, de configurations et d'extraits de code MLOPS utiles. Vous pouvez utiliser ce référentiel comme référence pour divers utilitaires.
Pourquoi vous ne voudrez peut-être pas l'utiliser:
Les choses se brisent de temps en temps
La foudre et l'hydra évoluent et intégrent encore de nombreuses bibliothèques, ce qui signifie que parfois les choses se cassent. Pour la liste des problèmes actuellement connus, visitez cette page.
Non ajusté pour l'ingénierie des données
Le modèle n'est pas vraiment ajusté pour la construction de pipelines de données qui dépendent les uns des autres. Il est plus efficace de l'utiliser pour le prototypage modèle sur les données prêtes à l'emploi.
Surveillance à un cas d'utilisation simple
La configuration de la configuration est construite en tenant compte de la simple formation Lightning. Vous devrez peut-être mettre un peu d'effort pour l'ajuster pour différents cas d'utilisation, par exemple le tissu Lightning.
Peut ne pas soutenir votre flux de travail
Par exemple, vous ne pouvez pas reprendre la recherche multiparamètre ou hyperparamètre basée sur HYDRA.
Remarque : Gardez à l'esprit qu'il s'agit d'un projet communautaire non officiel.
Pytorch Lightning - Un wrapper Pytorch léger pour la recherche sur l'IA à haute performance. Considérez-le comme un cadre pour organiser votre code pytorch.
HYDRA - Un cadre pour la configuration élégamment des applications complexes. La caractéristique clé est la possibilité de créer dynamiquement une configuration hiérarchique par composition et de la remplacer via des fichiers de configuration et la ligne de commande.
La structure du répertoire du nouveau projet ressemble à ceci:
├── .github <- Github Actions workflows
│
├── configs <- Hydra configs
│ ├── callbacks <- Callbacks configs
│ ├── data <- Data configs
│ ├── debug <- Debugging configs
│ ├── experiment <- Experiment configs
│ ├── extras <- Extra utilities configs
│ ├── hparams_search <- Hyperparameter search configs
│ ├── hydra <- Hydra configs
│ ├── local <- Local configs
│ ├── logger <- Logger configs
│ ├── model <- Model configs
│ ├── paths <- Project paths configs
│ ├── trainer <- Trainer configs
│ │
│ ├── eval.yaml <- Main config for evaluation
│ └── train.yaml <- Main config for training
│
├── data <- Project data
│
├── logs <- Logs generated by hydra and lightning loggers
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description,
│ e.g. `1.0-jqp-initial-data-exploration.ipynb`.
│
├── scripts <- Shell scripts
│
├── src <- Source code
│ ├── data <- Data scripts
│ ├── models <- Model scripts
│ ├── utils <- Utility scripts
│ │
│ ├── eval.py <- Run evaluation
│ └── train.py <- Run training
│
├── tests <- Tests of any kind
│
├── .env.example <- Example of file for storing private environment variables
├── .gitignore <- List of files ignored by git
├── .pre-commit-config.yaml <- Configuration of pre-commit hooks for code formatting
├── .project-root <- File for inferring the position of project root directory
├── environment.yaml <- File for installing conda environment
├── Makefile <- Makefile with commands like `make train` or `make test`
├── pyproject.toml <- Configuration options for testing and linting
├── requirements.txt <- File for installing python dependencies
├── setup.py <- File for installing project as a package
└── README.md
# clone project
git clone https://github.com/ashleve/lightning-hydra-template
cd lightning-hydra-template
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt Le modèle contient un exemple avec la classification MNIST.
Lorsque vous exécutez python src/train.py vous devriez voir quelque chose comme ceci:
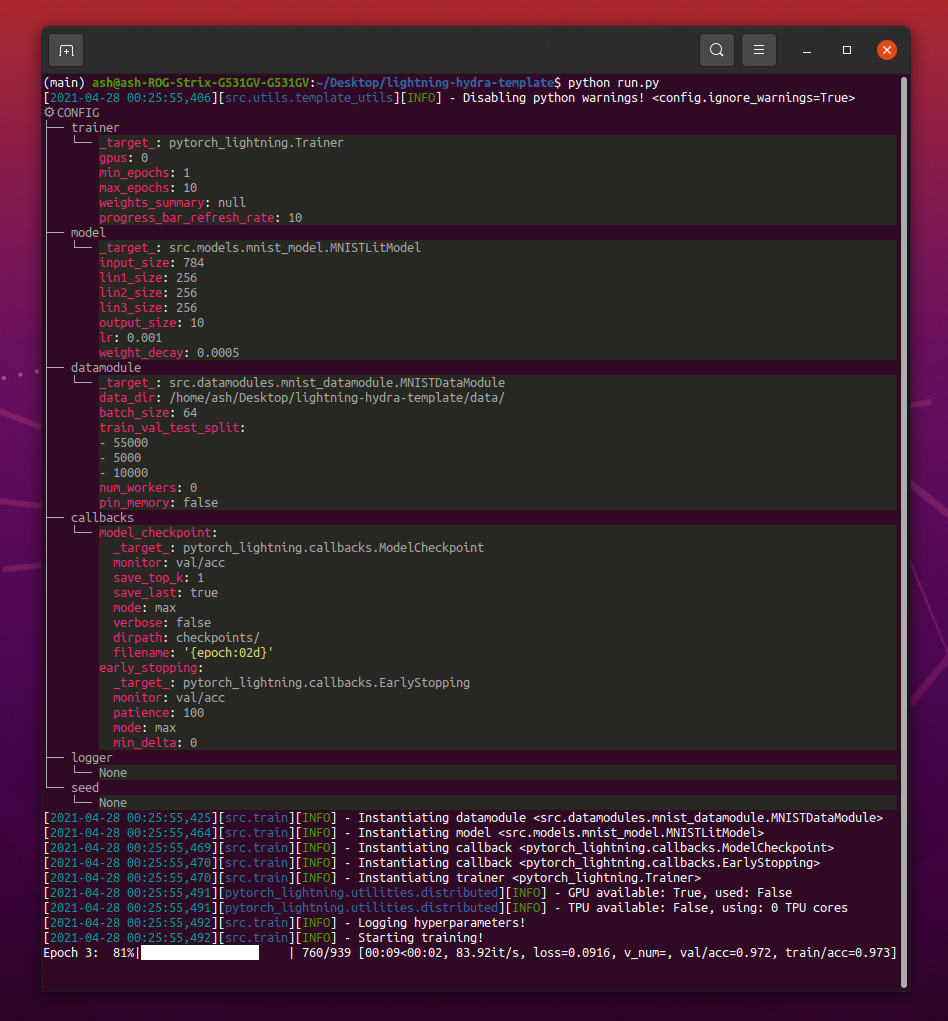
python train.py trainer.max_epochs=20 model.optimizer.lr=1e-4Remarque : vous pouvez également ajouter de nouveaux paramètres avec
+signe.
python train.py +model.new_param= " owo " # train on CPU
python train.py trainer=cpu
# train on 1 GPU
python train.py trainer=gpu
# train on TPU
python train.py +trainer.tpu_cores=8
# train with DDP (Distributed Data Parallel) (4 GPUs)
python train.py trainer=ddp trainer.devices=4
# train with DDP (Distributed Data Parallel) (8 GPUs, 2 nodes)
python train.py trainer=ddp trainer.devices=4 trainer.num_nodes=2
# simulate DDP on CPU processes
python train.py trainer=ddp_sim trainer.devices=2
# accelerate training on mac
python train.py trainer=mpsAVERTISSEMENT : Actuellement, il y a des problèmes avec le mode DDP, lisez ce problème pour en savoir plus.
# train with pytorch native automatic mixed precision (AMP)
python train.py trainer=gpu +trainer.precision=16 # set project and entity names in `configs/logger/wandb`
wandb :
project : " your_project_name "
entity : " your_wandb_team_name " # train model with Weights&Biases (link to wandb dashboard should appear in the terminal)
python train.py logger=wandbRemarque : Lightning fournit des intégrations pratiques avec les cadres de journalisation les plus populaires. Apprenez-en plus ici.
Remarque : l'utilisation de WandB vous oblige à configurer le compte d'abord. Après cela, complétez la configuration comme ci-dessous.
Remarque : cliquez ici pour voir l'exemple de tableau de bord WANDB généré avec ce modèle.
python train.py experiment=exampleRemarque : les configurations d'expérience sont placées dans des configurations / expérimentations /.
python train.py callbacks=defaultRemarque : les rappels peuvent être utilisés pour des choses telles que le point de contrôle du modèle, l'arrêt anticipé et bien d'autres.
Remarque : les configurations de rappels sont placées dans des configurations / rappels /.
# gradient clipping may be enabled to avoid exploding gradients
python train.py +trainer.gradient_clip_val=0.5
# run validation loop 4 times during a training epoch
python train.py +trainer.val_check_interval=0.25
# accumulate gradients
python train.py +trainer.accumulate_grad_batches=10
# terminate training after 12 hours
python train.py +trainer.max_time="00:12:00:00"Remarque : Pytorch Lightning fournit environ plus de 40 drapeaux d'entraîner utiles.
# runs 1 epoch in default debugging mode
# changes logging directory to `logs/debugs/...`
# sets level of all command line loggers to 'DEBUG'
# enforces debug-friendly configuration
python train.py debug=default
# run 1 train, val and test loop, using only 1 batch
python train.py debug=fdr
# print execution time profiling
python train.py debug=profiler
# try overfitting to 1 batch
python train.py debug=overfit
# raise exception if there are any numerical anomalies in tensors, like NaN or +/-inf
python train.py +trainer.detect_anomaly=true
# use only 20% of the data
python train.py +trainer.limit_train_batches=0.2
+trainer.limit_val_batches=0.2 +trainer.limit_test_batches=0.2Remarque : Visitez les configurations / débogage / pour différentes configurations de débogage.
python train.py ckpt_path="/path/to/ckpt/name.ckpt"Remarque : le point de contrôle peut être le chemin ou l'URL.
Remarque : Le chargement du chargement CKPT ne reprend pas l'expérience de journalisation, mais il sera pris en charge dans la future version de Lightning.
python eval.py ckpt_path="/path/to/ckpt/name.ckpt"Remarque : le point de contrôle peut être le chemin ou l'URL.
# this will run 6 experiments one after the other,
# each with different combination of batch_size and learning rate
python train.py -m data.batch_size=32,64,128 model.lr=0.001,0.0005Remarque : Hydra compose les configurations paresseusement au moment du lancement du travail. Si vous modifiez du code ou des configurations après avoir lancé un travail / balayage, les configurations composées finales peuvent être affectées.
# this will run hyperparameter search defined in `configs/hparams_search/mnist_optuna.yaml`
# over chosen experiment config
python train.py -m hparams_search=mnist_optuna experiment=exampleRemarque : L'utilisation du balayeur Optuna ne vous oblige pas à ajouter une bailli à votre code, tout est défini dans un seul fichier de configuration.
AVERTISSEMENT : les balayages Optuna ne sont pas résistants à l'échec (si un travail se bloque, tout le balayage se bloque).
python train.py -m ' experiment=glob(*) 'Remarque : HYDRA fournit une syntaxe spéciale pour contrôler le comportement des multimus. Apprenez-en plus ici. La commande ci-dessus exécute toutes les expériences à partir de configs / expériences /.
python train.py -m seed=1,2,3,4,5 trainer.deterministic=True logger=csv tags=[ " benchmark " ]Remarque :
trainer.deterministic=Truerend Pytorch plus déterministe mais a un impact sur les performances.
Remarque : Cela doit être réalisable avec une configuration simple à l'aide du lanceur Ray AWS pour HYDRA. L'exemple n'est pas implémenté dans ce modèle.
Remarque : HYDRA vous permet de les remplacer l'argument de configuration de la saisie semi-automatique dans Shell lorsque vous les écrivez, en appuyant sur la touche
tab. Lisez les documents.
pre-commit run -aRemarque : Appliquez des crochets pré-engagés pour faire des choses comme le code et les configurations de format automatique, effectuant une analyse de code ou supprimer la sortie des ordinateurs portables Jupyter. Voir # les meilleures pratiques pour en savoir plus.
Mettez à jour les versions de Hook pré-Commit dans .pre-commit-config.yaml avec:
pre-commit autoupdate # run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "Chaque expérience doit être marquée afin de les filtrer facilement sur les fichiers ou dans l'interface utilisateur de journalisation:
python train.py tags=[ " mnist " , " experiment_X " ]Remarque : vous devrez peut-être échapper aux caractères du support de votre coquille avec
python train.py tags=["mnist","experiment_X"].
Si aucune étiquette n'est fournie, il vous sera demandé de les saisir à partir de la ligne de commande:
>>> python train.py tags=[]
[2022-07-11 15:40:09,358][src.utils.utils][INFO] - Enforcing tags ! < cfg.extras.enforce_tags=True >
[2022-07-11 15:40:09,359][src.utils.rich_utils][WARNING] - No tags provided in config. Prompting user to input tags...
Enter a list of comma separated tags (dev):Si aucune étiquette n'est fournie pour Multirun, une erreur sera augmentée:
>>> python train.py -m +x=1,2,3 tags=[]
ValueError: Specify tags before launching a multirun !Remarque : les listes d'ajout de la ligne de commande ne sont actuellement pas prises en charge dans Hydra :(
Ce projet existe grâce à toutes les personnes qui contribuent.
Vous avez une question? Vous avez trouvé un bug? Vous manquez une fonctionnalité spécifique? N'hésitez pas à déposer un nouveau problème, une discussion ou des relations publiques avec le titre et la description respectifs.
Avant de faire un problème, veuillez vérifier que:
main actuelle.Les suggestions d'amélioration sont toujours les bienvenues!
Tous les modules Pytorch Lightning sont instanciés dynamiquement à partir des chemins de module spécifiés dans la configuration. Exemple de configuration du modèle:
_target_ : src.models.mnist_model.MNISTLitModule
lr : 0.001
net :
_target_ : src.models.components.simple_dense_net.SimpleDenseNet
input_size : 784
lin1_size : 256
lin2_size : 256
lin3_size : 256
output_size : 10En utilisant cette configuration, nous pouvons instancier l'objet avec la ligne suivante:
model = hydra . utils . instantiate ( config . model ) Cela vous permet d'itérer facilement sur de nouveaux modèles! Chaque fois que vous en créez un nouveau, spécifiez simplement son chemin de module et ses paramètres dans le fichier de configuration approprié.
Communiquez entre les modèles et les données avec des arguments de ligne de commande:
python train.py model=mnistExemple de pipeline Gérant la logique d'instanciation: src / train.py.
Emplacement: configs / train.yaml
La configuration du projet principal contient la configuration de formation par défaut.
Il détermine comment la configuration est composée lors de l'exécution de la commande python train.py .
# order of defaults determines the order in which configs override each other
defaults :
- _self_
- data : mnist.yaml
- model : mnist.yaml
- callbacks : default.yaml
- logger : null # set logger here or use command line (e.g. `python train.py logger=csv`)
- trainer : default.yaml
- paths : default.yaml
- extras : default.yaml
- hydra : default.yaml
# experiment configs allow for version control of specific hyperparameters
# e.g. best hyperparameters for given model and datamodule
- experiment : null
# config for hyperparameter optimization
- hparams_search : null
# optional local config for machine/user specific settings
# it's optional since it doesn't need to exist and is excluded from version control
- optional local : default.yaml
# debugging config (enable through command line, e.g. `python train.py debug=default)
- debug : null
# task name, determines output directory path
task_name : " train "
# tags to help you identify your experiments
# you can overwrite this in experiment configs
# overwrite from command line with `python train.py tags="[first_tag, second_tag]"`
# appending lists from command line is currently not supported :(
# https://github.com/facebookresearch/hydra/issues/1547
tags : ["dev"]
# set False to skip model training
train : True
# evaluate on test set, using best model weights achieved during training
# lightning chooses best weights based on the metric specified in checkpoint callback
test : True
# simply provide checkpoint path to resume training
ckpt_path : null
# seed for random number generators in pytorch, numpy and python.random
seed : null Emplacement: configs / expérience
Les configurations d'expérience vous permettent d'écraser les paramètres de la configuration principale.
Par exemple, vous pouvez les utiliser pour contrôler les meilleurs hyperparamètres pour chaque combinaison de modèle et d'ensemble de données.
# @package _global_
# to execute this experiment run:
# python train.py experiment=example
defaults :
- override /data : mnist.yaml
- override /model : mnist.yaml
- override /callbacks : default.yaml
- override /trainer : default.yaml
# all parameters below will be merged with parameters from default configurations set above
# this allows you to overwrite only specified parameters
tags : ["mnist", "simple_dense_net"]
seed : 12345
trainer :
min_epochs : 10
max_epochs : 10
gradient_clip_val : 0.5
model :
optimizer :
lr : 0.002
net :
lin1_size : 128
lin2_size : 256
lin3_size : 64
data :
batch_size : 64
logger :
wandb :
tags : ${tags}
group : " mnist " Flux de travail de base
python src/train.py experiment=experiment_name.yamlConception d'expérience
Supposons que vous souhaitez exécuter de nombreuses exécutions pour tracer comment la précision change en ce qui concerne la taille du lot.
Exécutez les exécutions avec un paramètre de configuration qui vous permet de les identifier facilement, comme les balises:
python train.py -m logger=csv data.batch_size=16,32,64,128 tags=[ " batch_size_exp " ] Écrivez un script ou un cahier qui recherche les logs/ dossiers et récupère les journaux CSV à partir des exécutions contenant des balises données dans la configuration. Tracer les résultats.
HYDRA crée un nouveau répertoire de sortie pour chaque exécution exécutée.
Structure de journalisation par défaut:
├── logs
│ ├── task_name
│ │ ├── runs # Logs generated by single runs
│ │ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the run
│ │ │ │ ├── .hydra # Hydra logs
│ │ │ │ ├── csv # Csv logs
│ │ │ │ ├── wandb # Weights&Biases logs
│ │ │ │ ├── checkpoints # Training checkpoints
│ │ │ │ └── ... # Any other thing saved during training
│ │ │ └── ...
│ │ │
│ │ └── multiruns # Logs generated by multiruns
│ │ ├── YYYY-MM-DD_HH-MM-SS # Datetime of the multirun
│ │ │ ├──1 # Multirun job number
│ │ │ ├──2
│ │ │ └── ...
│ │ └── ...
│ │
│ └── debugs # Logs generated when debugging config is attached
│ └── ...
Vous pouvez modifier cette structure en modifiant les chemins dans la configuration HYDRA.
Pytorch Lightning prend en charge de nombreux cadres de journalisation populaires: poids et biais, Neptune, comète, mlflow, tensorboard.
Ces outils vous aident à suivre les hyperparamètres et les mesures de sortie et vous permettent de comparer et de visualiser les résultats. Pour utiliser l'un d'eux, complétez simplement sa configuration dans des configurations / journalistes et exécuter:
python train.py logger=logger_nameVous pouvez en utiliser beaucoup à la fois (voir configs / logger / many_loggers.yaml par exemple).
Vous pouvez également écrire votre propre enregistreur.
Lightning fournit une méthode pratique pour enregistrer les mesures personnalisées à l'intérieur de LightningModule. Lisez les documents ou jetez un œil à l'exemple MNIST.
Le modèle est livré avec des tests génériques implémentés avec pytest .
# run all tests
pytest
# run tests from specific file
pytest tests/test_train.py
# run all tests except the ones marked as slow
pytest -k " not slow "La plupart des tests implémentés ne vérifient aucune sortie spécifique - ils existent pour vérifier simplement que l'exécution de certaines commandes ne finit pas par lancer des exceptions. Vous pouvez les exécuter de temps en temps pour accélérer le développement.
Actuellement, les tests couvrent des cas comme:
Et beaucoup d'autres. Vous devriez pouvoir les modifier facilement pour votre cas d'utilisation.
Il y a aussi l'implémenté @RunIf décorateur, qui vous permet d'exécuter des tests uniquement si certaines conditions sont remplies, par exemple le GPU est disponible ou si le système n'est pas Windows. Voir les exemples.
Vous pouvez définir la recherche d'hyperparamètre en ajoutant un nouveau fichier de configuration à configs / hparams_search.
# @package _global_
defaults :
- override /hydra/sweeper : optuna
# choose metric which will be optimized by Optuna
# make sure this is the correct name of some metric logged in lightning module!
optimized_metric : " val/acc_best "
# here we define Optuna hyperparameter search
# it optimizes for value returned from function with @hydra.main decorator
hydra :
sweeper :
_target_ : hydra_plugins.hydra_optuna_sweeper.optuna_sweeper.OptunaSweeper
# 'minimize' or 'maximize' the objective
direction : maximize
# total number of runs that will be executed
n_trials : 20
# choose Optuna hyperparameter sampler
# docs: https://optuna.readthedocs.io/en/stable/reference/samplers.html
sampler :
_target_ : optuna.samplers.TPESampler
seed : 1234
n_startup_trials : 10 # number of random sampling runs before optimization starts
# define hyperparameter search space
params :
model.optimizer.lr : interval(0.0001, 0.1)
data.batch_size : choice(32, 64, 128, 256)
model.net.lin1_size : choice(64, 128, 256)
model.net.lin2_size : choice(64, 128, 256)
model.net.lin3_size : choice(32, 64, 128, 256) Ensuite, exécutez-le avec: python train.py -m hparams_search=mnist_optuna
L'utilisation de cette approche ne nécessite pas d'ajouter de chaudronage au code, tout est défini dans un seul fichier de configuration. La seule chose nécessaire est de renvoyer la valeur métrique optimisée du fichier de lancement.
Vous pouvez utiliser différents cadres d'optimisation intégrés à Hydra, comme Optuna, AX ou Nevergrad.
L' optimization_results.yaml sera disponible dans le dossier logs/task_name/multirun .
Cette approche ne prend pas en charge la reprise de la recherche interrompue et des techniques avancées comme la taille - pour une recherche et des flux de travail plus sophistiqués, vous devriez probablement écrire une tâche d'optimisation dédiée (sans fonctionnalité Multiun).
Le modèle est livré avec des flux de travail CI implémentés dans les actions GitHub:
.github/workflows/test.yaml : exécuter tous les tests avec pytest.github/workflows/code-quality-main.yaml : exécuter des pré-comité sur la branche principale pour tous les fichiers.github/workflows/code-quality-pr.yaml : exécuter des pré-engagements sur les demandes de traction pour les fichiers modifiés uniquement Lightning prend en charge plusieurs façons de faire une formation distribuée. Le plus courant est le DDP, qui engendre un processus séparé pour chaque GPU et fait des gradients en moyenne entre eux. Pour en savoir plus sur d'autres approches, lisez les documents Lightning.
Vous pouvez exécuter DDP sur un exemple MNIST avec 4 GPU comme ceci:
python train.py trainer=ddpRemarque : Lorsque vous utilisez DDP, vous devez faire attention à la façon dont vous écrivez vos modèles - lisez les documents.
Le moyen le plus simple consiste à passer l'attribut Datamodule directement au modèle sur l'initialisation:
# ./src/train.py
datamodule = hydra . utils . instantiate ( config . data )
model = hydra . utils . instantiate ( config . model , some_param = datamodule . some_param )Remarque : Pas une solution très robuste, car elle suppose que tous vos datamodules ont un
some_paramdisponible.
De même, vous pouvez transmettre une configuration de Datamodule entière en tant que paramètre INIT:
# ./src/train.py
model = hydra . utils . instantiate ( config . model , dm_conf = config . data , _recursive_ = False )Vous pouvez également transmettre un paramètre de configuration Datamodule à votre modèle via une interpolation variable:
# ./configs/model/my_model.yaml
_target_ : src.models.my_module.MyLitModule
lr : 0.01
some_param : ${data.some_param}Une autre approche consiste à accéder à Datamodule dans LightningModule directement via Trainer:
# ./src/models/mnist_module.py
def on_train_start ( self ):
self . some_param = self . trainer . datamodule . some_paramRemarque : cela ne fonctionne qu'après le début de la formation, sinon le formateur ne sera pas encore disponible dans LightningModule.
Il n'est généralement pas nécessaire d'installer un environnement anaconda complet, MiniConda devrait être suffisant (poids autour de 80 Mo).
Le grand avantage de Conda est qu'il permet d'installer des packages sans exiger que certains compilateurs ou bibliothèques soient disponibles dans le système (car il installe des binaires précompilés), il est donc souvent plus facile d'installer certaines dépendances, par exemple Cudatoolkit pour la prise en charge du GPU.
Il vous permet également d'accéder à votre environnement dans le monde, ce qui pourrait être plus pratique que la création d'un nouvel environnement local pour chaque projet.
Exemple d'installation:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shMettre à jour Conda:
conda update -n base -c defaults condaCréer un nouvel environnement conda:
conda create -n myenv python=3.10
conda activate myenv Utilisez des crochets de pré-engagement pour normaliser le formatage du code de votre projet et économiser de l'énergie mentale.
Installez simplement le package pré-engagement avec:
pip install pre-commitEnsuite, installez les crochets à partir de .pre-COMMIT-CONFIG.YAML:
pre-commit installAprès cela, votre code sera automatiquement reformaté sur chaque nouvel engagement.
Pour reformater tous les fichiers de la commande d'utilisation du projet:
pre-commit run -aPour mettre à jour les versions de crochet dans .pre-comit-config.yaml Utilisation:
pre-commit autoupdate Les variables spécifiques au système (par exemple, les chemins absolus vers les ensembles de données) ne doivent pas être sous contrôle de version ou cela entraînera un conflit entre différents utilisateurs. Vos clés privées ne devraient pas non plus être versées car vous ne voulez pas qu'elles soient divulguées.
Le modèle contient le fichier .env.example , qui sert d'exemple. Créez un nouveau fichier appelé .env (ce nom est exclu du contrôle de version dans .gitignore). Vous devez l'utiliser pour stocker des variables d'environnement comme celle-ci:
MY_VAR=/home/user/my_system_path
Toutes les variables de .env sont chargées automatiquement dans train.py .
Hydra vous permet de référencer toute variable Env dans .yaml configs comme ceci:
path_to_data : ${oc.env:MY_VAR} Selon l'orgitateur que vous utilisez, il est souvent utile de définir le nom métrique avec / le caractère:
self . log ( "train/loss" , loss )De cette façon, les journalistes traiteront vos mesures comme appartenant à différentes sections, ce qui aide à les organiser dans l'interface utilisateur.
Utilisez la bibliothèque officielle de TorchMetrics pour assurer un calcul approprié des mesures. Ceci est particulièrement important pour la formation multi-GPU!
Par exemple, au lieu de calculer la précision par vous-même, vous devez utiliser la classe Accuracy fournie comme ceci:
from torchmetrics . classification . accuracy import Accuracy
class LitModel ( LightningModule ):
def __init__ ( self )
self . train_acc = Accuracy ()
self . val_acc = Accuracy ()
def training_step ( self , batch , batch_idx ):
...
acc = self . train_acc ( predictions , targets )
self . log ( "train/acc" , acc )
...
def validation_step ( self , batch , batch_idx ):
...
acc = self . val_acc ( predictions , targets )
self . log ( "val/acc" , acc )
...Assurez-vous d'utiliser une instance métrique différente pour chaque étape pour assurer une réduction de la valeur appropriée sur tous les processus GPU.
TorchMetrics fournit des mesures pour la plupart des cas d'utilisation, comme le score F1 ou la matrice de confusion. Lisez la documentation pour en savoir plus.
Le guide de style est disponible ici.
Soyez explicite dans votre init. Essayez de définir toutes les valeurs par défaut pertinentes afin que l'utilisateur n'ait pas à deviner. Fournir des conseils de type. De cette façon, votre module est réutilisable dans tous les projets!
class LitModel ( LightningModule ):
def __init__ ( self , layer_size : int = 256 , lr : float = 0.001 ):Conserver l'ordre de méthode recommandée.
class LitModel ( LightningModule ):
def __init__ ():
...
def forward ():
...
def training_step ():
...
def training_step_end ():
...
def on_train_epoch_end ():
...
def validation_step ():
...
def validation_step_end ():
...
def on_validation_epoch_end ():
...
def test_step ():
...
def test_step_end ():
...
def on_test_epoch_end ():
...
def configure_optimizers ():
...
def any_extra_hook ():
... Utilisez DVC pour contrôler les gros fichiers, comme vos données ou vos modèles ML formés.
Pour initialiser le référentiel DVC:
dvc init Pour commencer à suivre un fichier ou un répertoire, utilisez dvc add :
dvc add data/MNISTDVC stocke des informations sur le fichier ajouté (ou un répertoire) dans un fichier .dvc spécial nommé Data / Mnist.dvc, un petit fichier texte avec un format lisible par l'homme. Ce fichier peut être facilement versé comme un code source avec GIT, comme espace réservé pour les données d'origine:
git add data/MNIST.dvc data/.gitignore
git commit -m " Add raw data " Il permet à d'autres personnes d'utiliser facilement vos modules dans leurs propres projets. Modifiez le nom du dossier src au nom de votre projet et complétez le fichier setup.py .
Maintenant, votre projet peut être installé à partir de fichiers locaux:
pip install -e .Ou directement à partir du référentiel GIT:
pip install git+git://github.com/YourGithubName/your-repo-name.git --upgradeAinsi, n'importe quel fichier peut être facilement importé dans n'importe quel autre fichier comme tel:
from project_name . models . mnist_module import MNISTLitModule
from project_name . data . mnist_datamodule import MNISTDataModuleCertaines configurations sont spécifiques à l'utilisateur / machine / d'installation (par exemple, configuration du cluster local ou des chemins de carter sur une machine spécifique). Pour de tels scénarios, un fichier configs / local / default.yaml peut être créé qui est automatiquement chargé mais non suivi par GIT.
Par exemple, vous pouvez l'utiliser pour une configuration de cluster Slurm:
# @package _global_
defaults :
- override /hydra/launcher@_here_ : submitit_slurm
data_dir : /mnt/scratch/data/
hydra :
launcher :
timeout_min : 1440
gpus_per_task : 1
gres : gpu:1
job :
env_set :
MY_VAR : /home/user/my/system/path
MY_KEY : asdgjhawi8y23ihsghsueity23ihwd Ce modèle a été inspiré par:
Autres référentiels utiles:
Lightning-Hydra-Template est concédé sous licence MIT.
MIT License
Copyright (c) 2021 ashleve
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Supprimez tout ci-dessus pour votre projet
Ce qu'il fait
# clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# [OPTIONAL] create conda environment
conda create -n myenv python=3.9
conda activate myenv
# install pytorch according to instructions
# https://pytorch.org/get-started/
# install requirements
pip install -r requirements.txt # clone project
git clone https://github.com/YourGithubName/your-repo-name
cd your-repo-name
# create conda environment and install dependencies
conda env create -f environment.yaml -n myenv
# activate conda environment
conda activate myenvModèle de train avec configuration par défaut
# train on CPU
python src/train.py trainer=cpu
# train on GPU
python src/train.py trainer=gpuModèle de train avec la configuration de l'expérience choisie à partir de configs / expériences /
python src/train.py experiment=experiment_name.yamlVous pouvez remplacer n'importe quel paramètre à partir de la ligne de commande comme celle-ci
python src/train.py trainer.max_epochs=20 data.batch_size=64

