FastSpeech2
1.0.0
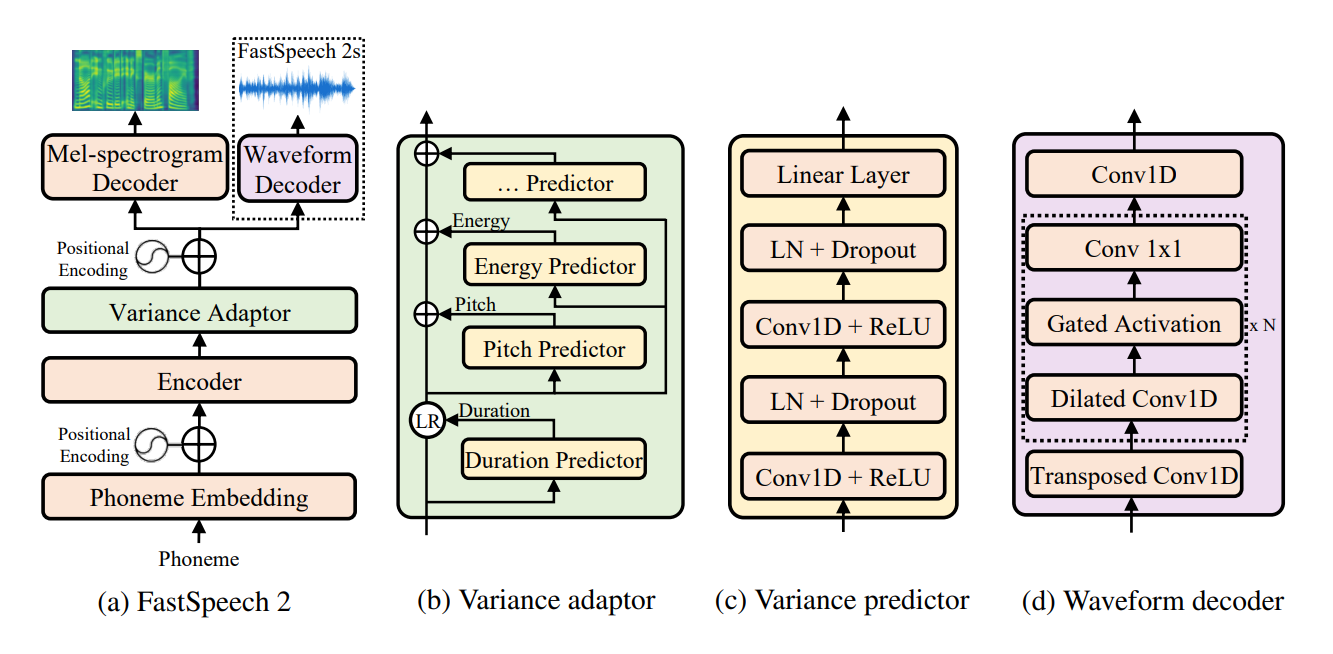
FastSpeech的非正式Pytorch实施2:快速和高质量的端到端文本到语音。此存储库将ESPNET的快速实现作为基础。在此实施中,我试图复制确切的纸张详细信息,但仍然需要进行一些更好的模型,此存储库为任何建议和改进而开放。该仓库使用NVIDIA的TACOTRON 2预处理进行音频预处理,将梅尔根(Melgan)作为Vocoder。
所有代码以Python 3.6.2编写。
在安装Pytorch之前,请通过运行以下命令来检查您的CUDA版本:
nvcc --version
pip install torch torchvision
在此存储库中,我使用了pytorch 1.6.0用于torch.bucketize功能,这在pytorch的先前版本中不存在。
pip install -r requirements.txt
tensorboard version 1.14.0分别使用受支持的tensorflow (1.14.0) filelists文件夹包含MFA(Motreal Force Aligner)处理的LJSpeech数据集文件,因此您无需将文本与LJSpeech数据集的音频(用于提取持续时间)对齐。对于其他数据集,请在此处遵循指令。对于其他预处理运行以下命令:
python .nvidia_preprocessing.py -d path_of_wavs
查找F0和能量的最小和最大
python .compute_statistics.py
在hparams.py中更新以下内容,按min和最大的f0和能量更新
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"
目前仅支持基于音素的合成。
python .inference.py -c .configsdefault.yaml -p .checkpointsfirst_1ts_version2_fastspeech_fe9a2c7_7k_steps.pyt --out output --text "ModuleList can be indexed like a regular Python list but modules it contains are properly registered."
python export_torchscript.py -c configs/default.yaml -n fastspeech_scrip --outdir etc
sample文件夹。 训练 :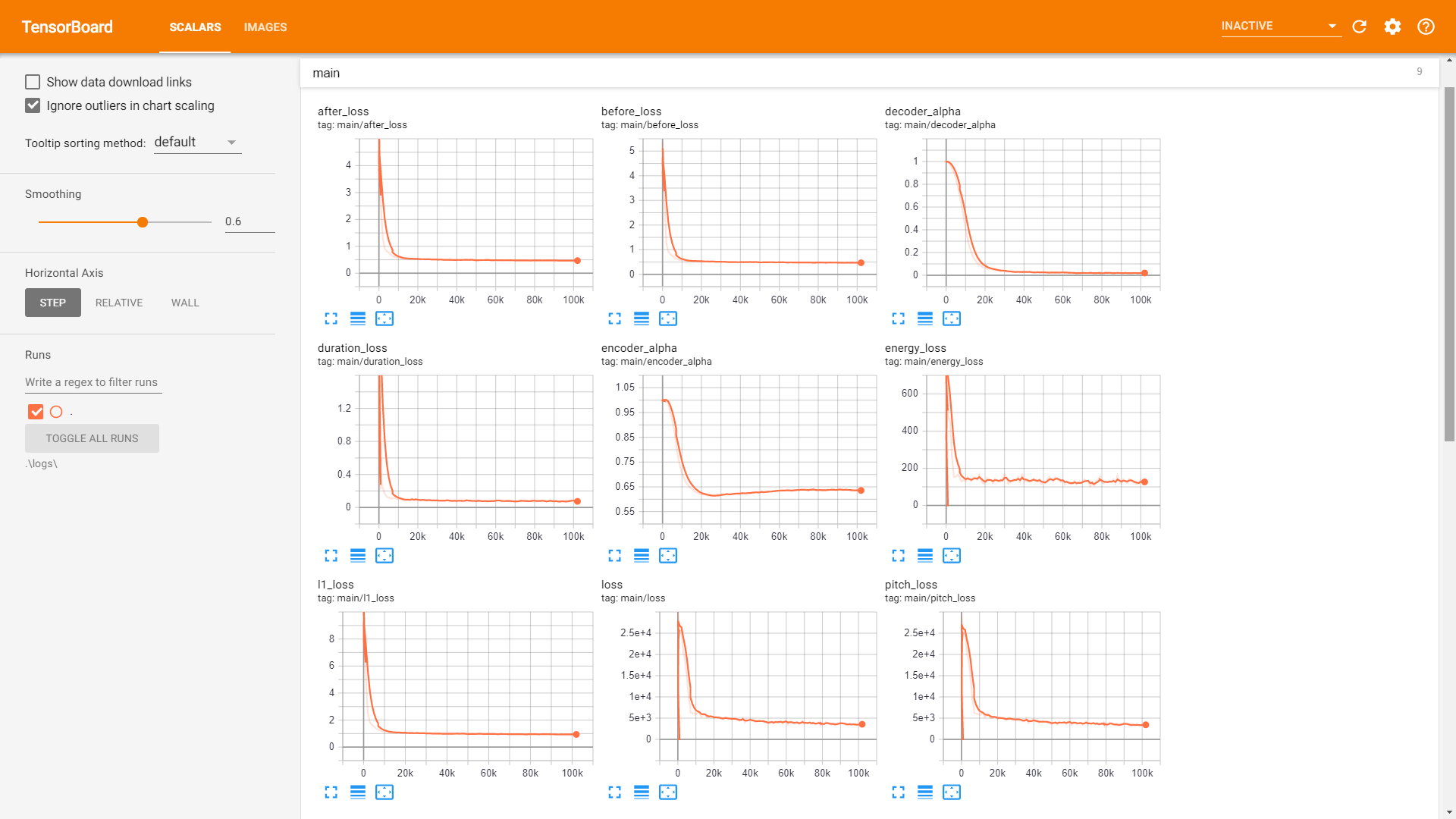
验证 : 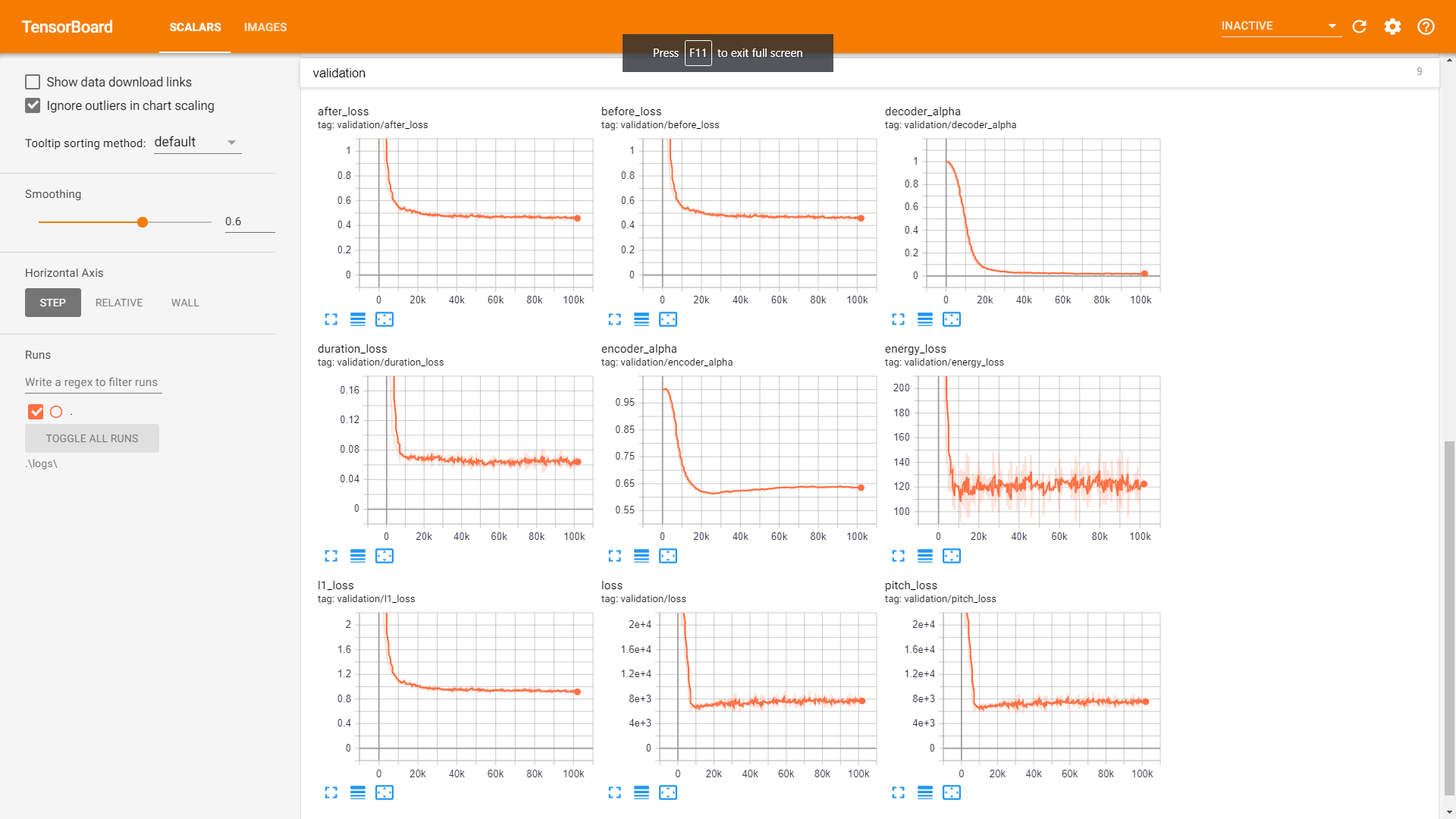
Postnet提高音频质量。

