FastSpeech2
1.0.0
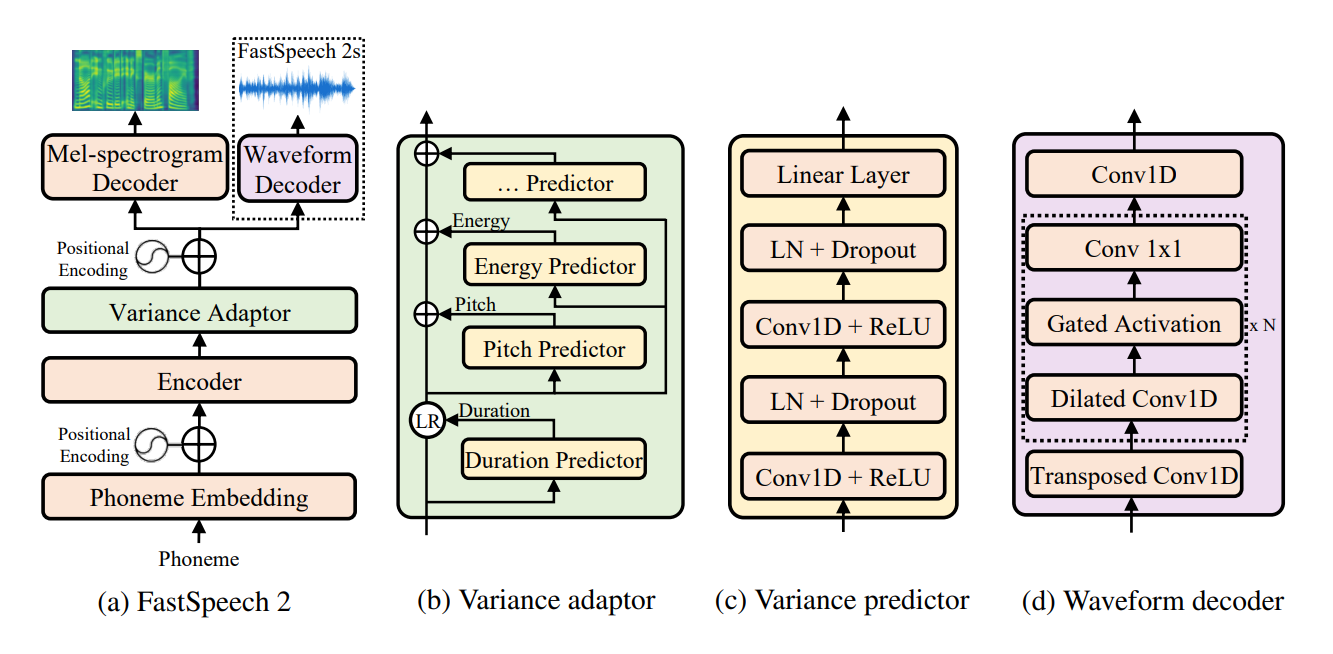
Inoffizielle Pytorch-Implementierung von Fastspeech 2: Schneller und hochwertiger End-to-End-Text zur Sprache . Dieses Repo verwendet die Fastspeech -Implementierung von ESPNET als Basis. In dieser Implementierung habe ich versucht, die genauen Papierdetails zu replizieren, aber dennoch eine Änderung für ein besseres Modell erforderlich, dieses Repo ist für jegliche Vorschläge und Verbesserungen geöffnet. Dieses Repo verwendet die Vorverarbeitung von Nvidia Tacotron 2 für Audio-Vorverarbeitung und Melgan als Vocoder.
Alle in Python 3.6.2 geschriebenen Code.
Vor der Installation von Pytorch überprüfen Sie bitte Ihre CUDA -Version, indem Sie den folgenden Befehl ausführen:
nvcc --version
pip install torch torchvision
In diesem Repo habe ich Pytorch 1.6.0 für torch.bucketize Funktion verwendet, die in früheren Pytorch -Versionen nicht vorhanden ist.
pip install -r requirements.txt
tensorboard version 1.14.0 separat mit unterstütztem tensorflow (1.14.0) Der filelists enthält MFA -Datensatzdateien (Motreal Force Aligner), sodass Sie den Text für den LJSpeech -Datensatz nicht mit Audio (für die Extraktdauer) ausrichten müssen. Für einen anderen Datensatz folgen Sie den Anweisungen hier. Für andere vorverarbeitende Ausführungsbefehlsbefehl:
python .nvidia_preprocessing.py -d path_of_wavs
Zum Auffinden der Min und Max von F0 und Energie
python .compute_statistics.py
Aktualisieren Sie Folgendes in hparams.py von Min und Max von F0 und Energie
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"
Derzeit wurde nur von Phonemes basierende Synthese unterstützt.
python .inference.py -c .configsdefault.yaml -p .checkpointsfirst_1ts_version2_fastspeech_fe9a2c7_7k_steps.pyt --out output --text "ModuleList can be indexed like a regular Python list but modules it contains are properly registered."
python export_torchscript.py -c configs/default.yaml -n fastspeech_scrip --outdir etc
sample . Ausbildung :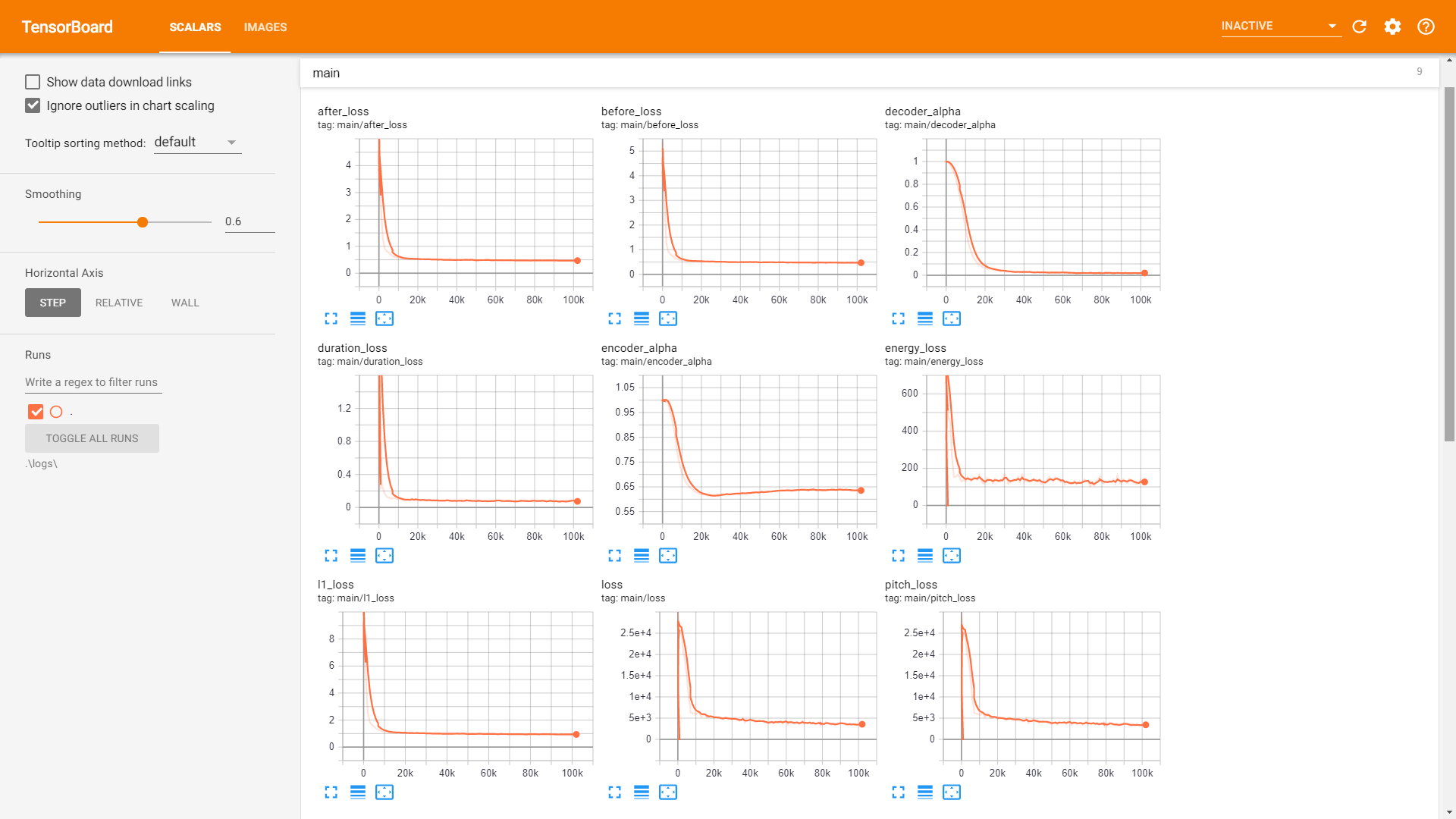
Validierung :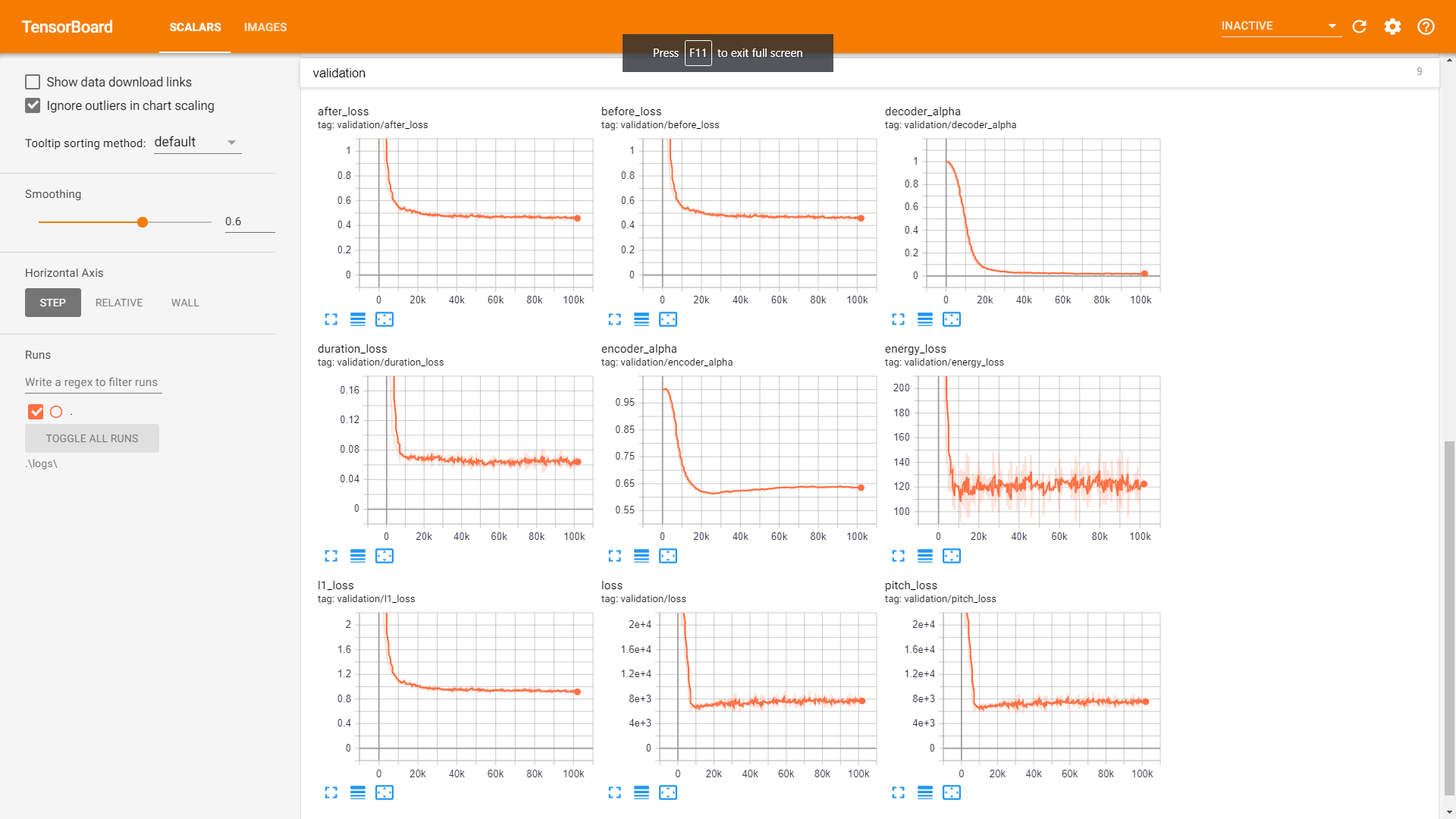
Postnet für eine bessere Audioqualität.

