FastSpeech2
1.0.0
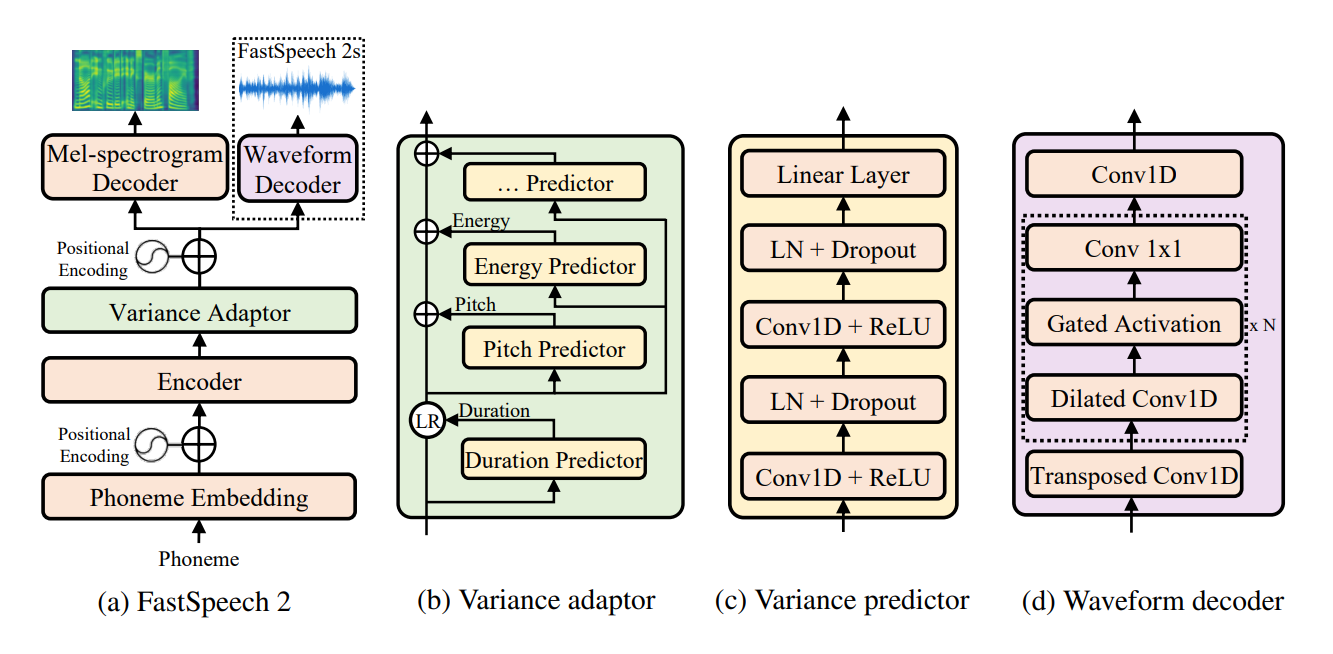
Implémentation non officielle Pytorch de FastSpeech 2: texte de bout en bout rapide et de haute qualité à la parole . Ce repo utilise l'implémentation FastSpeech de ESPNET comme base. Dans cette implémentation, j'ai essayé de reproduire les détails du papier exact, mais une certaine modification requise pour un meilleur modèle, ce repo s'ouvre pour toute suggestion et amélioration. Ce repo utilise le prétraitement du Tacotron 2 de Nvidia pour le prétraitement audio et Melgan comme vocoder.
Tout le code écrit en Python 3.6.2 .
Avant d'installer Pytorch, veuillez vérifier votre version CUDA en exécutant la commande suivante:
nvcc --version
pip install torch torchvision
Dans ce dépôt, j'ai utilisé Pytorch 1.6.0 pour la fonction torch.bucketize qui n'est pas présente dans les versions précédentes de Pytorch.
pip install -r requirements.txt
tensorboard version 1.14.0 séparément avec tensorflow (1.14.0) Le dossier filelists contient des fichiers de données LJSpeech traités MFA (MotReal Force Aligner), vous n'avez donc pas besoin d'aligner le texte avec l'audio (pour la durée d'extrait) pour l'ensemble de données LJSpeech. Pour un autre ensemble de données, suivez l'instruction ici. Pour d'autres prétraitements Exécuter la commande suivante:
python .nvidia_preprocessing.py -d path_of_wavs
Pour trouver le min et le max de F0 et de l'énergie
python .compute_statistics.py
Mettez à jour ce qui suit dans hparams.py par min et max de F0 et de l'énergie
p_min = Min F0/pitch
p_max = Max F0
e_min = Min energy
e_max = Max energy
python train_fastspeech.py --outdir etc -c configs/default.yaml -n "name"
Actuellement, seuls la synthèse basée sur les phonèmes est soutenue.
python .inference.py -c .configsdefault.yaml -p .checkpointsfirst_1ts_version2_fastspeech_fe9a2c7_7k_steps.pyt --out output --text "ModuleList can be indexed like a regular Python list but modules it contains are properly registered."
python export_torchscript.py -c configs/default.yaml -n fastspeech_scrip --outdir etc
sample . Entraînement :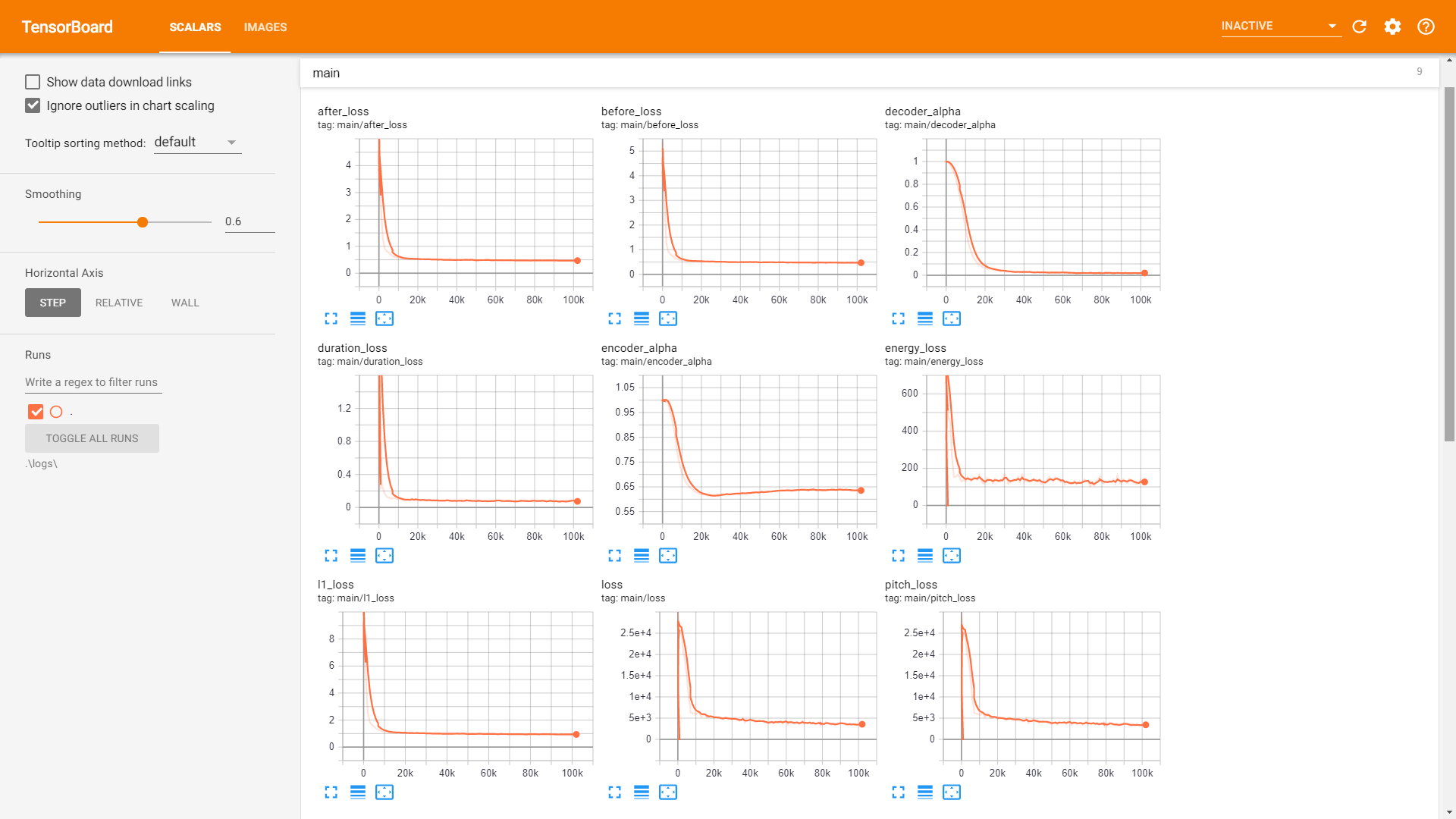
Validation: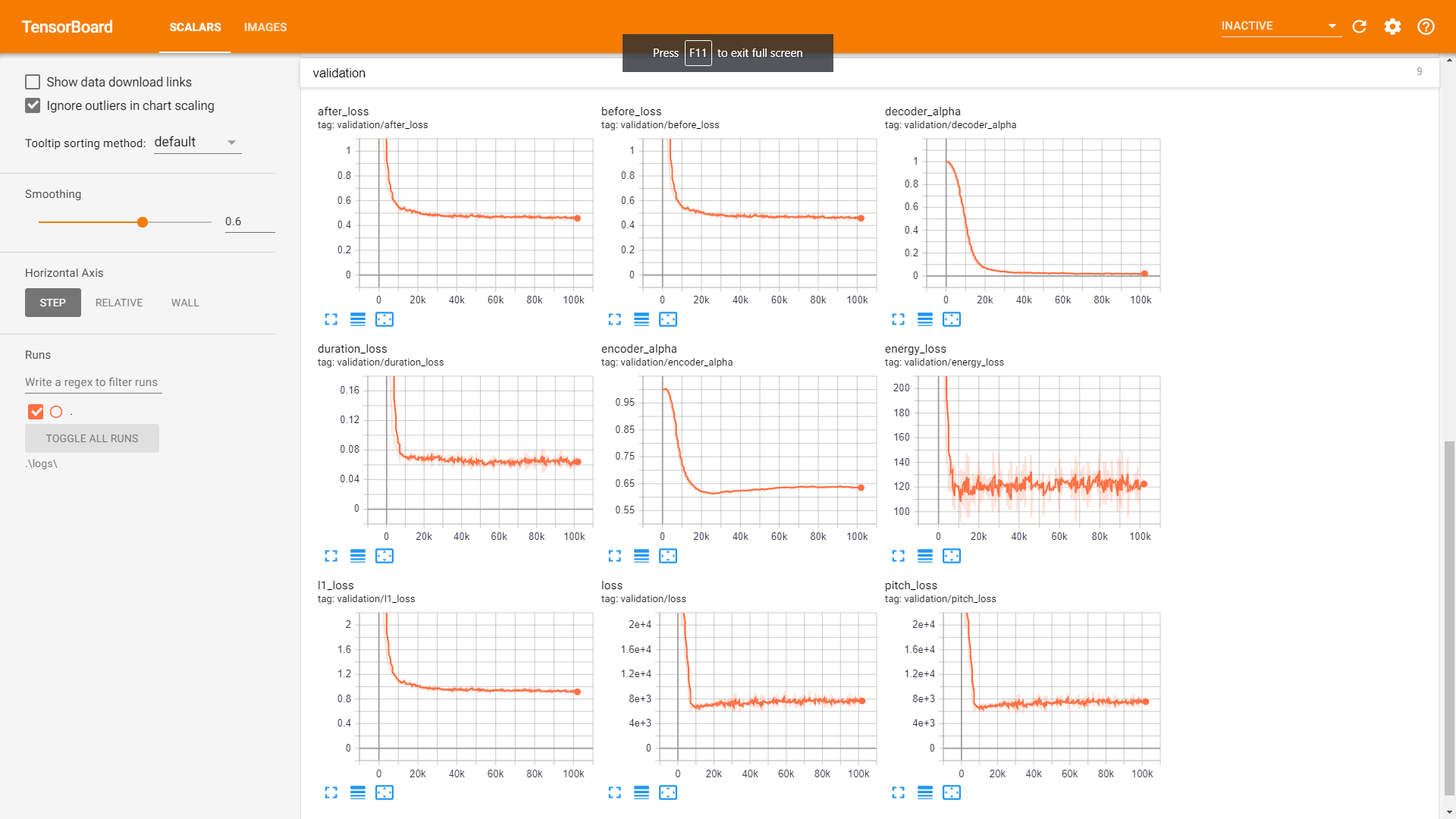
Postnet pour une meilleure qualité audio.

