wordsiv
1.0.0
WordsIV是一个用于生成具有有限字符集的文本的Python软件包。它设计用于类型的类型,但可能对生成脂肪图很有用。
假设您有字母HAMBURGERFONTSIVhamburgerfontsiv和标点符号.,词语可能会产生以下drivel:
是的,在上面的王位上对他有足够的罚款,这是一段时间以来的一段时间。她是他的想法,即使是从底层出发的想法,其余的不是他对此事进行衡量的动作的节省的东西,Ahab在中午或从绿色森林中给了船,而绿色的森林则像Ahab一样高。
在设计字体时,使用部分字符集检查文本很有用。 Wordsiv尽力使用任何可用的字形生成逼真的文本。
首先,使用pip安装单词iv:
# we install straight from git (for now!)
$ pip install git+https://github.com/tallpauley/wordsiv # byexample: +pass接下来,从源软件包的发行版页面上安装一个或多个源软件包:
$ base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass现在您可以在Python中做虚假句子!
> >> import wordsiv
> >> wsv = wordsiv . WordSiv ( limit_glyphs = ( 'HAMBURGERFONTSIVhamburgerfontsiv' ))
> >> wsv . sentence ( source = 'en_markov_gutenberg' )
( 'I might go over the instant to the streets in the air of those the same be '
'haunting' )如果您希望在Drawbot应用程序中工作,则可以按照此过程安装WordsIV:
通过Python->安装Python软件包安装wordsiv软件包:
git+https://github.com/tallpauley/wordsiv ,然后单击GO!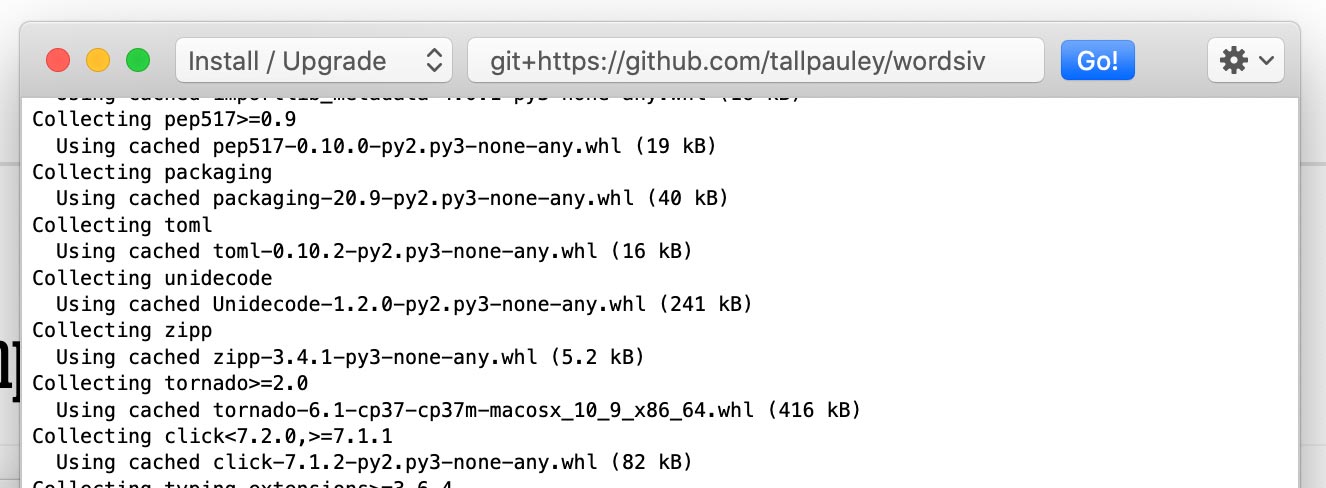
在同一窗口中安装所需的源软件包,但在结尾处添加--no-deps :
https://github.com/tallpauley/wordsiv-source-packages/releases/download/en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl --no-deps
.whl或.tar.gz软件包URL。当您编写drawbot脚本时,您将使用add_source_module()添加每个源:
import wordsiv
import en_wordcount_web
wsv = wordsiv . WordSiv ()
wsv . add_source_module ( en_wordcount_web )
print ( wsv . sentence ( source = "en_wordcount_web" ))
Wordsiv首先需要一些单词,这些单词以源形式出现:提供原始单词数据的对象。
这些来源可通过源软件包获得,这些源软件包只是Python软件包。让我们安装一些:
base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
# A markov model trained on public domain books
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common English words compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common Trigrams compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_trigrams-0.1.0/en_wordcount_trigrams-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passWordsiv自动发现这些已安装的软件包,并可以立即使用这些来源。让我们在现代用法中尝试用英语中最常见的词语来源:
> >> from wordsiv import WordSiv
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )一个单词如何知道如何将单词从源中排列到句子中?这是模型发挥作用的地方。
源en_wordcount_web默认使用模型rand 。在这里,我们明确选择模型rand以达到与上述相同的结果:
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' , model = "rand" )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )请注意,当我们初始化一个新的wordsiv()对象时,我们会得到相同的句子。这是因为词语被设计为决定性。
如果我们想要有些自然的文本,我们可能会使用MarkovModel( model='mkv' )。
> >> wsv . paragraph ( source = "en_markov_gutenberg" , model = "mkv" ) # byexample: +skip
"Why don't think so desirous of hugeness. Our pie is worship..."Markov模型对真实文本进行了训练,并通过查看前面的单词来预测每个单词。不过,我们使模型尽可能愚蠢(一个单词状态),以生成尽可能多的不同句子。
WordCount源和模型与简单的单词和事件列表一起工作以生成单词。
randommodel( model='rand' )使用事件随机选择单词,偏爱更流行的单词:
# Default: probability by occurence count
> >> wsv . paragraph ( source = 'en_wordcount_web' , model = 'rand' ) # byexample: +skip
'Day music, commencement protection to threads who and dimension...'Randommodel也可以设置为忽略事件的数量,并完全随机选择单词:
> >> wsv . sentence ( source = 'en_wordcount_web' , sent_len = 5 , prob = False ) # byexample: +skip
'Conceivably championships consecration ects— anointed.'顺序模型( model='seq' )以它们出现在源中的顺序吐出单词。我们可以使用此模型以英语显示前5个Trigram:
> >> wsv . words ( source = 'en_wordcount_trigrams' , num_words = 5 ) # byexample: +skip
[ 'the' , 'ing' , 'and' , 'ion' , 'tio' ]wordsiv是围绕选择单词的想法来构建的,这些单词可以用不完整的字体文件中的字形呈现。 wordsiv可以自动确定字体文件中的字形。
让我们加载字体,字符HAMBURGERFONTSIVhamburgerfontsiv
> >> wsv = WordSiv ( font_file = 'tests/data/noto-sans-subset.ttf' )
> >> wsv . sentence ( source = 'en_markov_gutenberg' , max_sent_len = 10 )
'Nor is fair to be in as these annuities'我们可以以相同的方式限制字形,但可以用limit_glyphs手动
> >> wsv = WordSiv ( limit_glyphs = 'HAMBURGERFONTSIVhamburgerfontsiv' )
> >> wsv . sentence ( source = 'en_wordcount_web' )
'Manage miss ago are motor to rather at first to be of has forget'font_file和limit_glyphs限制字形有时可以指定要显示的字符集,并且只有在字体文件中将其放置时才使用这些字符集。我们可以通过指定font_file和limit_glyphs来做到这一点:
> >> wsv = WordSiv (
... font_file = 'tests/data/noto-sans-subset.ttf' ,
... limit_glyphs = 'abcdefghijklmnop'
... )
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , min_wl = 3 )
'eng gnome gene game egg one aim him again one game one image boom' 可以通过多种方式操纵文本。这里有一些例子:
MarkovModel和WordCount模型都使我们能够大写或小写的文本,无论源单词是否大写:
> >> wsv = WordSiv ()
> >> wsv . sentence ( 'en_wordcount_web' , uc = True , max_sent_len = 8 )
'MAPLE CANVAS SPORTING PAGES TRANSFERRED, WITH SUPERIOR GOVERNMENT.'
> >> wsv . sentence (
... 'en_markov_gutenberg' , lc = True , min_sent_len = 7 , max_sent_len = 10
... )
'i besought the bosom of the sun so'默认情况下,通过大写句子来大写,但我们可以将其关闭:
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , sent_len = 10 )
'egcs very and mortgage expressed about and online truss controls.'默认情况下,WordCount模型插入标点符号的概率大致从英语中使用。
我们可以通过将自己的功能传递出标点符号来关闭:
> >> def only_period ( words , * args ): return ' ' . join ( words ) + '.'
> >> wsv . paragraph (
... source = 'en_wordcount_web' , punc_func = only_period , sent_len = 5 , para_len = 2
... )
'By schools sign I avoid. Or about fascism writers what.'有关punc_func的更多详细信息,请参见点上。这仅适用于WordCount模型,因为MarkovModel使用其源数据中的标点符号。
模型负责生成句子和单词,因此与这些句子有关的参数是由模型处理的。目前,请参阅这些模型的源代码,以了解对word() , words()和sentence() API的参数接受的参数:
单词iv对象本身处理sentences() , paragraph() , paragraphs()和带有参数的text调用。请参阅词语类源代码,以了解如何自定义文本输出。
在校对类型时,我们可能希望我们的证明在拥有相同的角色集的情况下保持不变。这有助于我们比较类型的变化。
因此,wordsiv使用单个伪随机数生成器,该数字生成器是在创建词语对象时播种的。这意味着使用此库的Python脚本将在运行何处产生相同的结果。
如果您希望脚本生成不同的单词,则可以播种单词iv对象:
> >> wsv = WordSiv ( seed = 6 )
> >> wsv . sentence ( source = "en_markov_gutenberg" , min_sent_len = 7 )
'even if i forgot the go in their' 在观看了纪录片编码的偏见之后,我考虑了我们是否应该基于历史(甚至是当前)数据来生成文本,因为性别歧视,种族主义,殖民主义,同性恋恐惧症等。
本节试图解决对我(Chris Pauley)引起的一些道德问题,并试图使该项目避免产生进攻性文本。
首先,该库是为了以下目的而设计的。
当然,我们自然会读单词(duh),因此不用说您应该监督该库生成的文本。
我考虑过是否有更多的进步文本可以培训马尔可夫模型。但是,无论如何,我们都将源文本争先恐后地毫无意义,以最大程度地利用有限的字符集制成的句子。
当炒作时,即使是最积极的文本也会很快变黑。一个州尺寸1的马尔可夫模型(适合有限角色集的理想)接受《联合国普遍人权宣言》训练的句子:
Everyone is entitled to torture
or other limitation of brotherhood.
关键是,半随机单词生成破坏了文本的含义,那么为什么要挑选一个周到的来源呢?但是,我们真的应该尝试远离进攻性材料,因为如果涉及任何概率,进攻模式将出现。
如果您想为该项目贡献资源和/或模型,这里有一些准则:
例如,我们通过保持1个状态大小为1来阻止MarkovModel从原始文本中拾取过多的上下文。拥有一个单词状态也增加了潜在句子的数量,因此它可以解决。
我们生成的句子不太有意义,但是由于这是为用于证明的虚拟文本而设计的,所以这是一件好事!
由于:
由于我们正在生成荒谬的文本进行校对,因此我们应该尽力通过令人反感的单词列表来过滤单词列表。如果您确实需要在文本中发誓,则可以为自己的目的创建来源。
我们不能阻止随机单词形成令人反感的句子,但是我们至少可以限制倾向于形成进攻性句子的单词。
诸如WordsIV中使用的统计模型将在文本(尤其是MarkovModels)中的模式中获取。尝试选择相当中立的原始材料(并非真正的东西)。
我用NLTK培训了EN_Markov_gutenberg的这些公共领域文本,该文本似乎足够安全,可以使用愚蠢的单字马尔可夫模型:
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
如果您注意到任何特定的模型生成进攻性句子都多,请在单词source-packages repo上提交问题。
我绝对不是第一个生成证据单词的人。查看这些很酷的项目,让我知道,如果您知道更多,我应该添加!
没有Word-O-Mat的灵感,我可能不会走得很远,Rob Stenson与我分享了一个不错的Drawbot脚本。后者是我想到将随机数生成器播种以使其确定性的想法。
我还从Spacy大量借用了如何设置源包。
还要感谢我的妻子帕米(Pammy)的善意,当我解释我所解决的每个深奥挑战时,并在我几乎用粗心的git错误中消除了4个小时的工作时,为我提供情感支持。


