wordsiv
1.0.0
Wordsiv เป็นแพ็คเกจ Python สำหรับการสร้างข้อความด้วยชุดอักขระที่ จำกัด มันถูกออกแบบมาสำหรับการพิสูจน์อักษรประเภท แต่อาจมีประโยชน์สำหรับการสร้าง lipograms
สมมติว่าคุณมีตัวอักษร HAMBURGERFONTSIVhamburgerfontsiv และเครื่องหมายวรรค ., ในแบบอักษรของคุณ คำพูดอาจสร้างดริฟท์ต่อไปนี้:
จริงพอสำหรับเขาที่ดีพอสำหรับเขาที่บัลลังก์ด้านบนบางครั้งในช่วงแรกของธุรกิจ เธอคือเขาตั้งเป็นความคิดที่เขามาจากพื้นผิวของมันมันเป็นส่วนที่เหลือของมันไม่ใช่สิ่งที่การออมของการเคลื่อนไหวที่เขาวัดเกี่ยวกับเรื่องนี้อาหับมอบให้กับเรือตอนเที่ยงหรือจากป่าสีเขียวสูงเช่นเดียวกับอาหับ
ในขณะที่ออกแบบตัวอักษรมันมีประโยชน์ในการตรวจสอบข้อความด้วยชุดอักขระบางส่วน Wordsiv พยายามอย่างดีที่สุดในการสร้างข้อความ ที่ดู สมจริงพร้อมกับร่ายมนตร์ที่มีอยู่
ก่อนอื่นให้ติดตั้งคำด้วย pip:
# we install straight from git (for now!)
$ pip install git+https://github.com/tallpauley/wordsiv # byexample: +passจากนั้นติดตั้งแพ็คเกจต้นทางอย่างน้อยหนึ่งแพ็คเกจจากหน้ารุ่นของแพ็คเกจต้นทาง repo:
$ base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passตอนนี้คุณสามารถสร้างประโยคปลอมใน Python!
> >> import wordsiv
> >> wsv = wordsiv . WordSiv ( limit_glyphs = ( 'HAMBURGERFONTSIVhamburgerfontsiv' ))
> >> wsv . sentence ( source = 'en_markov_gutenberg' )
( 'I might go over the instant to the streets in the air of those the same be '
'haunting' )หากคุณต้องการทำงานในแอพ DrawBot คุณสามารถทำตามขั้นตอนนี้เพื่อติดตั้ง WordSiv:
ติดตั้งแพ็คเกจ wordsiv ผ่าน Python-> ติดตั้งแพ็คเกจ Python :
git+https://github.com/tallpauley/wordsiv แล้วคลิก ไป!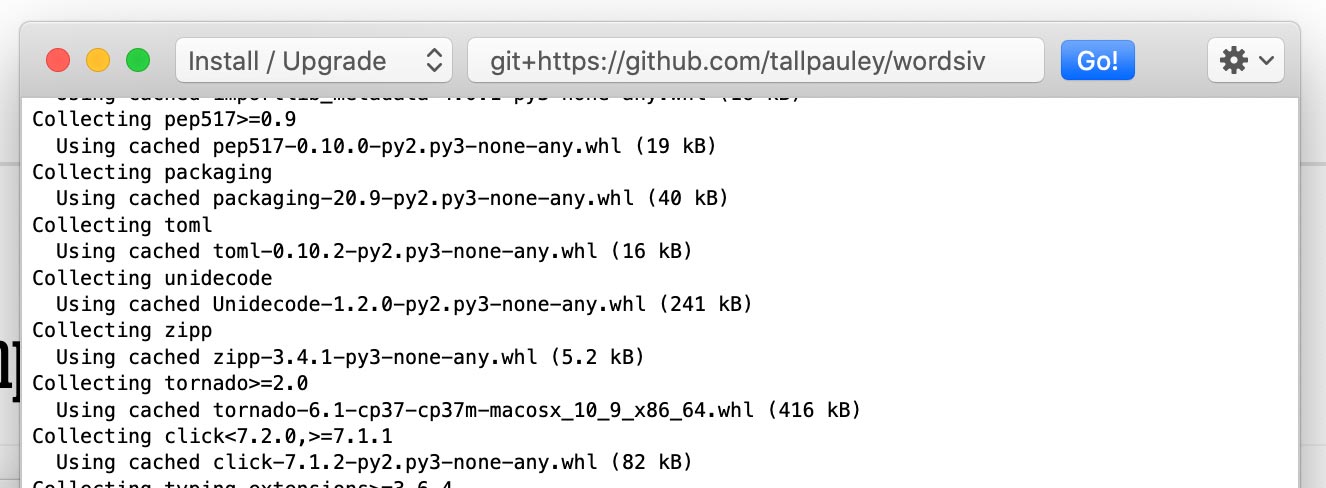
ติดตั้งแพ็คเกจต้นทางที่ต้องการในหน้าต่างเดียวกัน แต่เพิ่ม --no-deps ไปที่ท้ายที่สุด:
https://github.com/tallpauley/wordsiv-source-packages/releases/download/en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl --no-deps
.whl หรือ .tar.gz จากแพ็คเกจต้นทางรีลีสของแพ็คเกจ repo ภายใต้ สินทรัพย์ ดรอปดาวน์ เมื่อคุณเขียนสคริปต์ drawbot ของคุณคุณจะเพิ่มแต่ละแหล่งโดยใช้ add_source_module() :
import wordsiv
import en_wordcount_web
wsv = wordsiv . WordSiv ()
wsv . add_source_module ( en_wordcount_web )
print ( wsv . sentence ( source = "en_wordcount_web" ))
คำแรกต้องการคำบางคำซึ่งมาในรูปแบบของแหล่งที่มา: วัตถุที่ให้ข้อมูลคำดิบ
แหล่งข้อมูลเหล่านี้มีให้บริการผ่านแพ็คเกจต้นทางซึ่งเป็นเพียงแพ็คเกจ Python ติดตั้งกันเถอะ:
base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
# A markov model trained on public domain books
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common English words compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common Trigrams compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_trigrams-0.1.0/en_wordcount_trigrams-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passการค้นพบ Auto Auto Discovers แพ็คเกจที่ติดตั้งเหล่านี้และสามารถใช้แหล่งข้อมูลเหล่านี้ได้ทันที ลองมาที่แหล่งที่มาพร้อมกับคำที่พบบ่อยที่สุดในภาษาอังกฤษในการใช้งานสมัยใหม่:
> >> from wordsiv import WordSiv
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )คำศัพท์รู้วิธีจัดเรียงคำจากแหล่งที่มาเป็นประโยคอย่างไร นี่คือที่ โมเดล เข้ามาเล่น
แหล่งที่มา en_wordcount_web ใช้โมเดล rand โดยค่าเริ่มต้น ที่นี่เราเลือกโมเดล rand อย่างชัดเจนเพื่อให้ได้ผลลัพธ์เช่นเดียวกับด้านบน:
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' , model = "rand" )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )ขอให้สังเกตว่าเราได้รับประโยคเดียวกันเมื่อเราเริ่มต้นวัตถุคำศัพท์ใหม่ () นี่เป็นเพราะคำพูดถูกออกแบบมาให้กำหนด
หากเราต้องการข้อความที่ค่อนข้าง เป็น ธรรมชาติเราอาจใช้ MarkovModel ของเรา ( model='mkv' )
> >> wsv . paragraph ( source = "en_markov_gutenberg" , model = "mkv" ) # byexample: +skip
"Why don't think so desirous of hugeness. Our pie is worship..."โมเดลมาร์คอฟได้รับการฝึกฝนเกี่ยวกับข้อความจริงและคาดการณ์แต่ละคำโดยดูที่คำก่อนหน้านี้ เราทำให้แบบจำลองโง่ที่สุดเท่าที่จะเป็นไปได้
แหล่งข้อมูลและแบบจำลอง WordCount ทำงานกับรายการคำและการเกิดขึ้นง่าย ๆ นับเพื่อสร้างคำ
การใช้ RandoMOTEL ( model='rand' ) จำนวนการเกิดขึ้นเพื่อเลือกคำที่สุ่มเลือกคำนิยมคำที่เป็นที่นิยมมากขึ้น:
# Default: probability by occurence count
> >> wsv . paragraph ( source = 'en_wordcount_web' , model = 'rand' ) # byexample: +skip
'Day music, commencement protection to threads who and dimension...'Randomontel ยังสามารถตั้งค่าให้เพิกเฉยต่อการนับจำนวนและเลือกคำที่สุ่มอย่างสมบูรณ์:
> >> wsv . sentence ( source = 'en_wordcount_web' , sent_len = 5 , prob = False ) # byexample: +skip
'Conceivably championships consecration ects— anointed.' SequentialModel ( model='seq' ) พ่นคำในลำดับที่ปรากฏในแหล่งที่มา เราสามารถใช้โมเดลนี้เพื่อแสดง trigrams 5 อันดับแรกในภาษาอังกฤษ:
> >> wsv . words ( source = 'en_wordcount_trigrams' , num_words = 5 ) # byexample: +skip
[ 'the' , 'ing' , 'and' , 'ion' , 'tio' ]Wordsiv ถูกสร้างขึ้นรอบ ๆ แนวคิดของการเลือกคำที่สามารถแสดงผลด้วยร่ายมนตร์ในไฟล์ตัวอักษรที่ไม่สมบูรณ์ Wordsiv สามารถกำหนดร่ายมนตร์ได้โดยอัตโนมัติในไฟล์ตัวอักษร
มาโหลดตัวอักษรด้วยตัวละคร HAMBURGERFONTSIVhamburgerfontsiv
> >> wsv = WordSiv ( font_file = 'tests/data/noto-sans-subset.ttf' )
> >> wsv . sentence ( source = 'en_markov_gutenberg' , max_sent_len = 10 )
'Nor is fair to be in as these annuities' เราสามารถ จำกัด ร่ายมนตร์ในลักษณะเดียวกัน แต่ด้วยตนเองด้วย limit_glyphs ด้วยตนเอง
> >> wsv = WordSiv ( limit_glyphs = 'HAMBURGERFONTSIVhamburgerfontsiv' )
> >> wsv . sentence ( source = 'en_wordcount_web' )
'Manage miss ago are motor to rather at first to be of has forget'font_file และ limit_glyphs บางครั้งอาจมีประโยชน์ในการระบุชุดอักขระที่เรา ต้องการแสดง และใช้อักขระเหล่านั้นเฉพาะในกรณีที่เรามีอยู่ในไฟล์ตัวอักษร เราสามารถทำได้โดยการระบุทั้ง font_file และ limit_glyphs :
> >> wsv = WordSiv (
... font_file = 'tests/data/noto-sans-subset.ttf' ,
... limit_glyphs = 'abcdefghijklmnop'
... )
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , min_wl = 3 )
'eng gnome gene game egg one aim him again one game one image boom' สามารถจัดการข้อความได้หลายวิธี นี่คือตัวอย่างบางส่วน:
ทั้งรุ่น MarkovModel และ WordCount ช่วยให้เราสามารถเพิ่มข้อความหรือตัวพิมพ์เล็กไม่ว่าคำแหล่งที่มาจะเป็นตัวพิมพ์ใหญ่หรือไม่ก็ตาม:
> >> wsv = WordSiv ()
> >> wsv . sentence ( 'en_wordcount_web' , uc = True , max_sent_len = 8 )
'MAPLE CANVAS SPORTING PAGES TRANSFERRED, WITH SUPERIOR GOVERNMENT.'
> >> wsv . sentence (
... 'en_markov_gutenberg' , lc = True , min_sent_len = 7 , max_sent_len = 10
... )
'i besought the bosom of the sun so'Randomontel โดยใช้ประโยชน์จากประโยคโดยค่าเริ่มต้น แต่เราสามารถปิดสิ่งนี้ได้:
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , sent_len = 10 )
'egcs very and mortgage expressed about and online truss controls.'โดยค่าเริ่มต้นโมเดล WordCount แทรกเครื่องหมายวรรคตอนที่มีความน่าจะเป็นที่ได้มาจากการใช้งานในภาษาอังกฤษ
เราสามารถปิดสิ่งนี้ได้โดยผ่านฟังก์ชั่นของเราเองสำหรับเครื่องหมายวรรคตอน:
> >> def only_period ( words , * args ): return ' ' . join ( words ) + '.'
> >> wsv . paragraph (
... source = 'en_wordcount_web' , punc_func = only_period , sent_len = 5 , para_len = 2
... )
'By schools sign I avoid. Or about fascism writers what.' สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับ punc_func ดูเครื่องหมายวรรคตอน สิ่งนี้ใช้กับโมเดล WordCount เท่านั้นเนื่องจาก MarkovModel ใช้เครื่องหมายวรรคตอนในข้อมูลแหล่งที่มา
แบบจำลองดูแลการสร้าง ประโยค และ คำศัพท์ ดังนั้นพารามิเตอร์ที่เกี่ยวข้องกับสิ่งเหล่านี้จะถูกจัดการโดยโมเดล สำหรับตอนนี้โปรดดูที่ซอร์สโค้ดสำหรับโมเดลเหล่านี้เพื่อเรียนรู้พารามิเตอร์ที่ยอมรับสำหรับ word() , words() และ sentence() APIs:
วัตถุ คำศัพท์ นั้นจัดการกับ sentences() , paragraph() , paragraphs() และการเรียก text ด้วยพารามิเตอร์ของพวกเขา ดูซอร์สโค้ดคลาส WordSIV เพื่อเรียนรู้วิธีปรับแต่งเอาต์พุตข้อความ
เมื่อประเภทการพิสูจน์อักษรเราอาจต้องการให้การพิสูจน์ของเรายังคงอยู่เหมือนกันตราบใดที่เรามีชุดอักขระเดียวกัน สิ่งนี้ช่วยให้เราเปรียบเทียบการเปลี่ยนแปลงในประเภท
ด้วยเหตุผลนี้ Wordsiv ใช้เครื่องกำเนิดหมายเลขแท่นหลอกแบบหลอกเดียวซึ่งได้รับการเพาะปลูกเมื่อสร้างวัตถุคำศัพท์ ซึ่งหมายความว่าสคริปต์ Python ที่ใช้ไลบรารีนี้จะให้ผลลัพธ์เดียวกันทุกที่ที่ทำงาน
หากคุณต้องการให้สคริปต์ของคุณสร้างคำที่แตกต่างกันคุณสามารถเพาะวัตถุคำศัพท์ได้:
> >> wsv = WordSiv ( seed = 6 )
> >> wsv . sentence ( source = "en_markov_gutenberg" , min_sent_len = 7 )
'even if i forgot the go in their' หลังจากดูอคติที่เขียนด้วยสารคดีฉันคิดว่าเราควรสร้างข้อความตามข้อมูลในอดีต (หรือปัจจุบัน) เนื่องจากการกีดกันทางเพศการเหยียดเชื้อชาติการล่าอาณานิคมลัทธิหวั่นเกรง ฯลฯ ที่มีอยู่ในตำรา
ส่วนนี้พยายามที่จะตอบคำถามทางจริยธรรมเหล่านี้ที่เกิดขึ้นกับฉัน (Chris Pauley) และพยายามที่จะนำโครงการนี้ออกไปจากการสร้างข้อความที่น่ารังเกียจ
ก่อนอื่นห้องสมุดนี้ได้รับการออกแบบมาเพื่อจุดประสงค์ของ:
แน่นอนว่าเรา อ่าน คำ (duh) โดยธรรมชาติดังนั้นโดยไม่บอกว่าคุณควรควบคุมข้อความที่สร้างโดยห้องสมุดนี้
ฉันพิจารณาว่ามีข้อความที่ก้าวหน้ากว่านี้ฉันสามารถฝึกอบรมโมเดลมาร์คอฟได้หรือไม่ อย่างไรก็ตามเรากำลังดิ้นรนข้อความต้นฉบับไปยังความหมายต่อไปเพื่อเพิ่มประโยคที่ทำด้วยชุดอักขระที่ จำกัด
แม้แต่ข้อความที่เป็นบวกที่สุดก็สามารถมืดได้อย่างรวดเร็วเมื่อมีสัญญาณรบกวน โมเดลมาร์คอฟขนาดรัฐ 1 (เหมาะสำหรับชุดตัวละครที่ จำกัด ) ที่ได้รับการฝึกฝนด้วยการประกาศสิทธิมนุษยชนสากลของสหประชาชาติทำให้ประโยคนี้:
Everyone is entitled to torture
or other limitation of brotherhood.
ประเด็นคือการสร้างคำกึ่งสุ่มทำลายความหมายของข้อความดังนั้นทำไมต้องเลือกแหล่งที่มาอย่างรอบคอบ? อย่างไรก็ตามเราควรพยายามอยู่ห่างจากแหล่งข้อมูลที่น่ารังเกียจเพราะรูปแบบที่น่ารังเกียจ จะ ปรากฏขึ้นหากมีความน่าจะเป็นที่เกี่ยวข้อง
หากคุณต้องการมีส่วนร่วมแหล่งที่มาและ/หรือรูปแบบให้กับโครงการนี้นี่คือแนวทางบางอย่าง:
ตัวอย่างเช่นเราป้องกันไม่ให้ Markovmodel หยิบบริบทมากเกินไปจากข้อความต้นฉบับโดยรักษาขนาดสถานะไว้ที่ 1 การมีสถานะคำเดียวจะเพิ่มจำนวนประโยคที่มีศักยภาพเช่นกัน
ประโยคที่เราสร้างทำให้รู้สึกน้อยลง แต่เนื่องจากสิ่งนี้ถูกออกแบบมาสำหรับข้อความจำลองสำหรับการพิสูจน์อักษรนี่เป็นสิ่งที่ดี!
มันเป็นเรื่องยุ่งยากในการกรองคำ "น่ารังเกียจ" ตั้งแต่:
เนื่องจากเรากำลังสร้างข้อความที่ไร้สาระสำหรับการพิสูจน์อักษรเราควรพยายามอย่างดีที่สุดในการกรอง WordLists ด้วยรายการคำที่น่ารังเกียจ หากคุณต้องการคำสาบานในข้อความของคุณจริงๆคุณสามารถสร้างแหล่งที่มาเพื่อจุดประสงค์ของคุณเอง
เราไม่สามารถป้องกันคำสุ่มจากการสร้างประโยคที่น่ารังเกียจได้ แต่อย่างน้อยเราก็สามารถ จำกัด คำที่ มีแนวโน้มที่จะสร้าง ประโยคที่น่ารังเกียจ
แบบจำลองทางสถิติเช่นที่ใช้ใน Wordsiv จะเลือกรูปแบบในข้อความ - โดยเฉพาะ MarkovModels พยายามเลือกแหล่งข้อมูลที่ค่อนข้างเป็นกลาง (ไม่ใช่สิ่งที่เป็น จริง )
ฉันได้รับการฝึกฝน EN_MARKOV_GUTENBERG ด้วยข้อความโดเมนสาธารณะเหล่านี้จาก NLTK ซึ่งดูปลอดภัยพอสำหรับรุ่นมาร์คอฟที่โง่และเป็นใบ้คำเดียว:
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
หากคุณสังเกตเห็นโมเดลใด ๆ ที่สร้างประโยคที่น่ารังเกียจมากกว่าไม่ได้โปรดยื่นปัญหาที่ Repo คำว่า source-source-packages
ฉันไม่ใช่คนแรกที่สร้างคำสำหรับการพิสูจน์อักษร ตรวจสอบโครงการที่ยอดเยี่ยมเหล่านี้และแจ้งให้เราทราบหากคุณรู้มากกว่านี้ฉันควรเพิ่ม!
ฉันอาจจะไม่ได้ไปไกลมากนักหากปราศจากแรงบันดาลใจของ Word-o-mat และสคริปต์ Drawbot ที่ดีที่ Rob Stenson แบ่งปันกับฉัน หลังคือที่ที่ฉันมีความคิดที่จะเพาะตัวเครื่องกำเนิดตัวเลขสุ่มเพื่อให้เป็นตัวกำหนด
ฉันยังยืมอย่างหนักจาก Spacy ในวิธีที่ฉันตั้งค่าแพ็คเกจต้นทาง
นอกจากนี้ยังอยากขอบคุณภรรยาของฉันแพมมี่ที่ฟังอย่างกรุณาขณะที่ฉันอธิบายความท้าทายที่ลึกลับที่ฉันได้จัดการและให้การสนับสนุนทางอารมณ์แก่ฉันเมื่อฉันเกือบจะหมดเวลาทำงาน 4 ชั่วโมงด้วยความผิดพลาดที่ไม่ระมัดระวัง


