wordsiv
1.0.0
Wordsiv es un paquete de Python para generar texto con un conjunto de caracteres limitado. Está diseñado para la prueba de tipo, pero puede ser útil para generar lipogramas.
Digamos que tiene las letras HAMBURGERFONTSIVhamburgerfontsiv y la puntuación ., En su fuente. Wordsiv podría generar la siguiente tontería:
Es cierto que es lo suficientemente fino para él en los tronos anteriores, en algún momento de ese primer negocio. Ella es que él ha establecido como un pensamiento que incluso de sus sustratos es el resto no son las cosas que los ahorros de un movimiento que mide sobre el asunto, Ahab da a los botes al mediodía, o desde el bosque verde, tan alto como en Ahab.
Mientras diseña un tipo de letra, es útil examinar el texto con un conjunto de caracteres parcial. Wordsiv hace todo lo posible para generar texto de aspecto realista con los glifos disponibles.
Primero, instale Wordsiv con PIP:
# we install straight from git (for now!)
$ pip install git+https://github.com/tallpauley/wordsiv # byexample: +passA continuación, instale uno o más paquetes de origen en la página de versiones de los paquetes de origen Repo:
$ base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass¡Ahora puedes hacer frases falsas en Python!
> >> import wordsiv
> >> wsv = wordsiv . WordSiv ( limit_glyphs = ( 'HAMBURGERFONTSIVhamburgerfontsiv' ))
> >> wsv . sentence ( source = 'en_markov_gutenberg' )
( 'I might go over the instant to the streets in the air of those the same be '
'haunting' )Si prefiere trabajar en la aplicación Drawbot, puede seguir este procedimiento para instalar WordsIV:
Instale el paquete wordsiv a través de Python-> Instalar paquetes de Python :
git+https://github.com/tallpauley/wordsiv y haga clic en Go!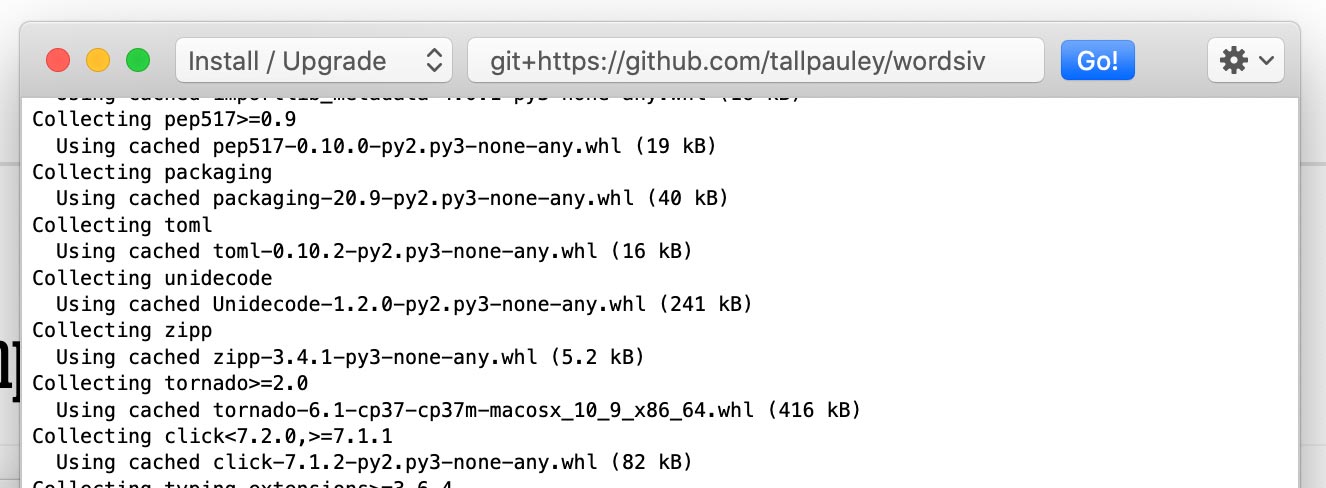
Instale los paquetes de origen deseados en la misma ventana, pero agregue --no-deps al final:
https://github.com/tallpauley/wordsiv-source-packages/releases/download/en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl --no-deps
.whl o .tar.gz de la página de comunicaciones de repo de paquetes de origen debajo del menú desplegable de activos . Cuando escriba su script bot, agregará cada fuente usando add_source_module() ::
import wordsiv
import en_wordcount_web
wsv = wordsiv . WordSiv ()
wsv . add_source_module ( en_wordcount_web )
print ( wsv . sentence ( source = "en_wordcount_web" ))
Wordsiv primero necesita algunas palabras, que vienen en forma de fuentes: objetos que proporcionan los datos de las palabras sin procesar.
Estas fuentes están disponibles a través de paquetes de origen, que son simplemente paquetes de Python. Instalemos algunos:
base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
# A markov model trained on public domain books
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common English words compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common Trigrams compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_trigrams-0.1.0/en_wordcount_trigrams-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passWordsIV descubre automáticamente estos paquetes instalados y puede usar estas fuentes de inmediato. Probemos una fuente con las palabras más comunes en el idioma inglés en el uso moderno:
> >> from wordsiv import WordSiv
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )¿Cómo sabe un Wordsiv cómo organizar las palabras de una fuente en una oración? Aquí es donde entran en juego los modelos .
La fuente en_wordcount_web usa Model rand de forma predeterminada. Aquí seleccionamos explícitamente el modelo rand para lograr el mismo resultado que el anterior:
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' , model = "rand" )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )Observe que obtenemos la misma oración cuando inicializamos un nuevo objeto Wordsiv (). Esto se debe a que WordsIV está diseñado para ser determinisico.
Si queremos un texto que sea algo natural , podríamos usar nuestro MarkovModel ( model='mkv' ).
> >> wsv . paragraph ( source = "en_markov_gutenberg" , model = "mkv" ) # byexample: +skip
"Why don't think so desirous of hugeness. Our pie is worship..."Un modelo de Markov está entrenado en texto real y pronostica cada palabra mirando las palabras (s) anteriores. Sin embargo, mantenemos el modelo lo más estúpido posible (un estado de una palabra) para generar tantas oraciones diferentes como sea posible.
Las fuentes y modelos de cuenta de palabras funcionan con listas simples de palabras y ocurrencias cuentan para generar palabras.
El Randmodel ( model='rand' ) utiliza recuentos de ocurrencias para elegir al azar palabras, favoreciendo palabras más populares:
# Default: probability by occurence count
> >> wsv . paragraph ( source = 'en_wordcount_web' , model = 'rand' ) # byexample: +skip
'Day music, commencement protection to threads who and dimension...'El Randmodel también se puede configurar para ignorar los recuentos de ocurrencias y elegir palabras completamente al azar:
> >> wsv . sentence ( source = 'en_wordcount_web' , sent_len = 5 , prob = False ) # byexample: +skip
'Conceivably championships consecration ects— anointed.' El secuencial Modelo ( model='seq' ) escupe palabras en el orden en que aparecen en la fuente. Podríamos usar este modelo para mostrar los 5 principales trigramas en el idioma inglés:
> >> wsv . words ( source = 'en_wordcount_trigrams' , num_words = 5 ) # byexample: +skip
[ 'the' , 'ing' , 'and' , 'ion' , 'tio' ]WordsIv se basa en la idea de seleccionar palabras que se pueden representar con los glifos en un archivo de fuentes incompleto. WordsIV puede determinar automáticamente qué glifos están en un archivo de fuentes.
Cargamos una fuente con los personajes HAMBURGERFONTSIVhamburgerfontsiv
> >> wsv = WordSiv ( font_file = 'tests/data/noto-sans-subset.ttf' )
> >> wsv . sentence ( source = 'en_markov_gutenberg' , max_sent_len = 10 )
'Nor is fair to be in as these annuities' Podemos limitar los glifos de la misma manera, pero manualmente con limit_glyphs
> >> wsv = WordSiv ( limit_glyphs = 'HAMBURGERFONTSIVhamburgerfontsiv' )
> >> wsv . sentence ( source = 'en_wordcount_web' )
'Manage miss ago are motor to rather at first to be of has forget'font_file y limit_glyphs A veces puede ser útil especificar el conjunto de caracteres que queremos mostrar , y solo usar esos caracteres si los tenemos en el archivo de fuentes. Podemos hacer esto especificando tanto font_file como limit_glyphs :
> >> wsv = WordSiv (
... font_file = 'tests/data/noto-sans-subset.ttf' ,
... limit_glyphs = 'abcdefghijklmnop'
... )
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , min_wl = 3 )
'eng gnome gene game egg one aim him again one game one image boom' Hay una variedad de formas en que se puede manipular el texto. Aquí hay algunos ejemplos:
Tanto los modelos MarkovModel como WordCount nos permiten un texto en mayúsculas o minúsculas, ya sea que las palabras de origen estén capitalizadas o no:
> >> wsv = WordSiv ()
> >> wsv . sentence ( 'en_wordcount_web' , uc = True , max_sent_len = 8 )
'MAPLE CANVAS SPORTING PAGES TRANSFERRED, WITH SUPERIOR GOVERNMENT.'
> >> wsv . sentence (
... 'en_markov_gutenberg' , lc = True , min_sent_len = 7 , max_sent_len = 10
... )
'i besought the bosom of the sun so'El Randmodel capitaliza las oraciones por defecto, pero podemos desactivar esto:
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , sent_len = 10 )
'egcs very and mortgage expressed about and online truss controls.'Por defecto, los modelos de WordCount insertan puntuación con probabilidades derivadas aproximadamente del uso en el idioma inglés.
Podemos apagar esto pasando nuestra propia función para la puntuación:
> >> def only_period ( words , * args ): return ' ' . join ( words ) + '.'
> >> wsv . paragraph (
... source = 'en_wordcount_web' , punc_func = only_period , sent_len = 5 , para_len = 2
... )
'By schools sign I avoid. Or about fascism writers what.' Para obtener más detalles sobre punc_func , consulte Punctation.py. Esto solo se aplica para los modelos de cuenta de Word, ya que el MarkovModel usa la puntuación en sus datos de origen.
Los modelos se encargan de generar oraciones y palabras , por lo que los modelos manejan los parámetros relacionados con ellas. Por ahora, consulte el código fuente de estos modelos para aprender los parámetros aceptados para word() , words() y sentence() API:
El objeto Wordsiv en sí maneja sentences() , paragraph() , paragraphs() y llamadas text con sus parámetros. Consulte el código fuente de la clase Wordsiv para aprender cómo personalizar la salida de texto.
Al probar el tipo, probablemente queramos que nuestra prueba permanezca igual siempre que tengamos el mismo conjunto de caracteres. Esto nos ayuda a comparar cambios en el tipo.
Por esta razón, Wordsiv usa un solo generador de números pseudo-aleatorios, que se sembra en la creación del objeto Wordsiv. Esto significa que un script de Python usando esta biblioteca producirá el mismo resultado donde sea que se ejecute.
Si desea que su script genere diferentes palabras, puede sembrar el objeto Wordsiv:
> >> wsv = WordSiv ( seed = 6 )
> >> wsv . sentence ( source = "en_markov_gutenberg" , min_sent_len = 7 )
'even if i forgot the go in their' Después de ver el sesgo codificado documental, consideré si incluso debemos generar texto basado en datos históricos (o incluso actuales), debido al sexismo, el racismo, el colonialismo, la homofobia, etc., contenidos en los textos.
Esta sección intenta abordar algunas de estas preguntas éticas que surgieron para mí (Chris Pauley) e intenta alejar este proyecto de generar texto ofensivo.
En primer lugar, esta biblioteca fue diseñada para los fines de:
Por supuesto, naturalmente leemos palabras (duh), por lo que no hace falta decir que debe supervisar el texto generado por esta biblioteca.
Consideré que si había textos más progresivos en los que podría entrenar un modelo de Markov. Sin embargo, estamos luchando por el texto de la fuente de la falta de sentido de todos modos, para maximizar las oraciones hechas con un conjunto de caracteres limitado.
Incluso el texto más positivo puede oscurecerse muy rápido cuando se revuelve. Un modelo de estado de Markov de tamaño 1 (ideal para conjuntos de caracteres limitados) entrenado con la Declaración Universal de Derechos Humanos de la ONU hizo esta oración:
Everyone is entitled to torture
or other limitation of brotherhood.
El punto es que la generación de palabras semi-aleatorias arruina el significado del texto, entonces, ¿por qué molestarse en elegir una fuente reflexiva? Sin embargo, realmente deberíamos tratar de mantenernos alejados del material fuente ofensivo, porque los patrones ofensivos aparecerán si hay alguna probabilidad involucrada.
Si desea contribuir con una fuente y/o modelo a este proyecto, aquí hay algunas pautas:
Por ejemplo, evitamos que MarkovModel recoja demasiado contexto del texto original manteniendo un tamaño de estado de 1. Tener un estado de una sola palabra también aumenta la cantidad de oraciones potenciales, por lo que funciona.
Las oraciones que generamos tienen menos sentido, pero dado que esto está diseñado para texto ficticio para la prueba, ¡esto es algo bueno!
Es complicado filtrar palabras "ofensivas", ya que:
Como estamos generando texto sin sentido para la prueba, debemos hacer todo lo posible para filtrar listas de palabras por listas de palabras ofensivas. Si realmente necesita juramentos en su texto, puede crear fuentes para sus propios fines.
No podemos evitar que las palabras aleatorias formen oraciones ofensivas, pero al menos podemos restringir las palabras que tienden a formar oraciones ofensivas.
Los modelos estadísticos como los utilizados en WordsIV captarán los patrones en el texto, especialmente Markovmodels. Trate de elegir el material fuente que sea bastante neutral (no es que nada realmente lo sea).
Entrené en_markov_guutenberg con estos textos de dominio público de NLTK, que parecía lo suficientemente seguro para un modelo tonto de Markov de un solo estado de palabras:
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
Si nota cualquier modelo en particular que genere oraciones ofensivas más que no, presente un problema en el repositorio de WordsIV-Source-Packages.
Definitivamente no soy el primero en generar palabras para la prueba. ¡Mira estos proyectos geniales y avísame si sabes más que debería agregar!
Probablemente no habría llegado muy lejos sin la inspiración de Word-O-Mat, y un buen guión de bote que Rob Stenson compartió conmigo. Este último es donde tuve la idea de sembrar el generador de números aleatorios para que sea determinista.
También tomé prestado mucho de Spacy en cómo configuré los paquetes de origen.
También quiero agradecer a mi esposa Pammy por escuchar amablemente mientras explico cada desafío esotérico que he abordado, y prestándome apoyo emocional cuando casi aniquilé 4 horas de trabajo con un error descuidado de GIT.


