wordsiv
1.0.0
Wordsiv هي حزمة Python لإنشاء نص مع مجموعة أحرف محدودة. إنه مصمم للتدقيق النوع ، ولكنه قد يكون مفيدًا لتوليد تصوير الدهون.
دعنا نقول أن لديك رسائل HAMBURGERFONTSIVhamburgerfontsiv وعلامات الترقيم ., في خطك. قد تولد Wordsiv الوعرة التالية:
صحيح بما فيه الكفاية ، لغرامة بما يكفي له في العروش أعلاه ، في وقت ما في هذا العمل أولاً. إنها أنه قد وضع فكرة أنه حتى من الطبقات الأساسية ، فهي ليست الأشياء التي يقيسها الحركة التي يقيسها حول هذه المسألة ، حيث يعطي Ahab القوارب عند الظهر ، أو من الغابة الخضراء ، كما هو الحال في Ahab.
أثناء تصميم محرف ، من المفيد فحص النص مع مجموعة أحرف جزئية. يحاول Wordsiv قصارى جهده لتوليد نص واقعية- مع أي رسومات متوفرة.
أولاً ، قم بتثبيت Wordsiv مع PIP:
# we install straight from git (for now!)
$ pip install git+https://github.com/tallpauley/wordsiv # byexample: +passبعد ذلك ، قم بتثبيت حزم مصدر واحدة أو أكثر من صفحة الإصدارات من حزم المصادر:
$ base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passالآن يمكنك جعل جمل زائفة في بيثون!
> >> import wordsiv
> >> wsv = wordsiv . WordSiv ( limit_glyphs = ( 'HAMBURGERFONTSIVhamburgerfontsiv' ))
> >> wsv . sentence ( source = 'en_markov_gutenberg' )
( 'I might go over the instant to the streets in the air of those the same be '
'haunting' )إذا كنت تفضل العمل في تطبيق DrawBot ، فيمكنك اتباع هذا الإجراء لتثبيت Wordsiv:
قم بتثبيت حزمة wordsiv عبر Python-> تثبيت حزم Python :
git+https://github.com/tallpauley/wordsiv وانقر فوق Go!
قم بتثبيت حزم المصدر المطلوبة في نفس النافذة ، ولكن أضف --no-deps في النهاية:
https://github.com/tallpauley/wordsiv-source-packages/releases/download/en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl --no-deps
.whl أو .tar.gz من صفحة إصدارات الحزم المصدر لإصدارات REPO أسفل الأصول المنسدلة. عندما تكتب البرنامج النصي DrawBot ، ستضيف كل مصدر باستخدام add_source_module() :
import wordsiv
import en_wordcount_web
wsv = wordsiv . WordSiv ()
wsv . add_source_module ( en_wordcount_web )
print ( wsv . sentence ( source = "en_wordcount_web" ))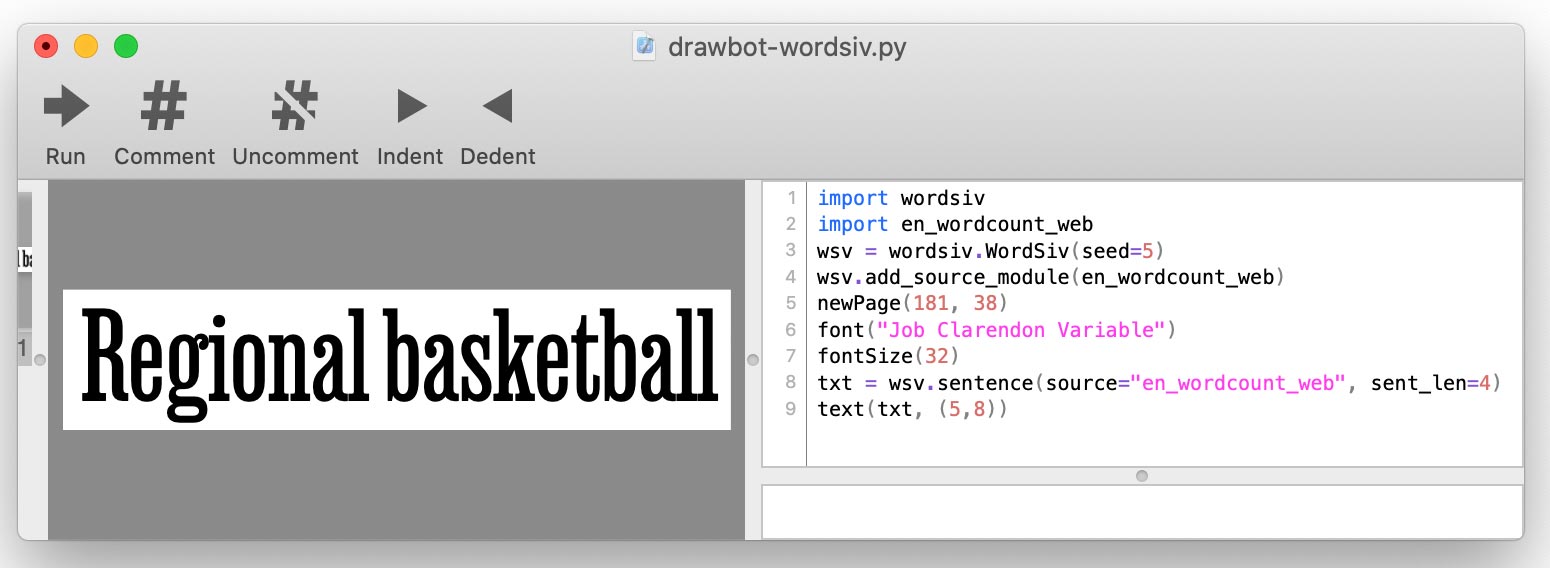
يحتاج Wordsiv أولاً إلى بعض الكلمات ، والتي تأتي في شكل مصادر: الكائنات التي توفر بيانات الكلمات الأولية.
تتوفر هذه المصادر عبر حزم المصدر ، والتي هي ببساطة حزم بيثون. دعنا نثبت بعض:
base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
# A markov model trained on public domain books
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common English words compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common Trigrams compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_trigrams-0.1.0/en_wordcount_trigrams-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passيكتشف Wordiv Auto-Discovers هذه الحزم المثبتة ، ويمكنه استخدام هذه المصادر على الفور. دعونا نجرب مصدرا مع الكلمات الأكثر شيوعا في اللغة الإنجليزية في الاستخدام الحديث:
> >> from wordsiv import WordSiv
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )كيف يعرف Wordsiv كيفية ترتيب الكلمات من مصدر إلى جملة؟ هذا هو المكان الذي تلعب فيه النماذج .
يستخدم المصدر en_wordcount_web طراز rand افتراضيًا. هنا نختار بشكل صريح طراز rand لتحقيق نفس النتيجة أعلاه:
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' , model = "rand" )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )لاحظ أننا نحصل على نفس الجملة عندما نهيئة كائن Wordsiv () جديد. هذا لأن Wordsiv مصمم ليكون حتميًا.
إذا كنا نريد نصًا طبيعيًا إلى حد ما ، فقد نستخدم markovmodel ( model='mkv' ).
> >> wsv . paragraph ( source = "en_markov_gutenberg" , model = "mkv" ) # byexample: +skip
"Why don't think so desirous of hugeness. Our pie is worship..."يتم تدريب نموذج Markov على نص حقيقي ، ويتوقع كل كلمة من خلال النظر إلى الكلمات (الكلمات) السابقة. نحافظ على النموذج أغبياء قدر الإمكان (حالة كلمة واحدة) لإنشاء أكبر عدد ممكن من الجمل المختلفة.
تعمل مصادر WordCount والنماذج مع قوائم بسيطة من الكلمات وحدوثها لإنشاء الكلمات.
يستخدم Randommodel ( model='rand' ) تعدادات في اختيار الكلمات بشكل عشوائي ، لصالح كلمات أكثر شعبية:
# Default: probability by occurence count
> >> wsv . paragraph ( source = 'en_wordcount_web' , model = 'rand' ) # byexample: +skip
'Day music, commencement protection to threads who and dimension...'يمكن أيضًا ضبط Randommodel لتجاهل التهمات واختيار الكلمات بشكل عشوائي تمامًا:
> >> wsv . sentence ( source = 'en_wordcount_web' , sent_len = 5 , prob = False ) # byexample: +skip
'Conceivably championships consecration ects— anointed.' يبصق SequentialModel ( model='seq' ) الكلمات بالترتيب الذي تظهر في المصدر. يمكننا استخدام هذا النموذج لعرض أفضل 5 تريغرام في اللغة الإنجليزية:
> >> wsv . words ( source = 'en_wordcount_trigrams' , num_words = 5 ) # byexample: +skip
[ 'the' , 'ing' , 'and' , 'ion' , 'tio' ]تم تصميم Wordsiv حول فكرة اختيار الكلمات التي يمكن تقديمها باستخدام الرسوم الحرارية في ملف خط غير مكتمل. يمكن لـ WordsIV تحديد ماهية الحروف الرسومية تلقائيًا في ملف الخط.
دعنا نحمل الخط مع الشخصيات HAMBURGERFONTSIVhamburgerfontsiv
> >> wsv = WordSiv ( font_file = 'tests/data/noto-sans-subset.ttf' )
> >> wsv . sentence ( source = 'en_markov_gutenberg' , max_sent_len = 10 )
'Nor is fair to be in as these annuities' يمكننا الحد من الحروف الرسومية بنفس الطريقة ، ولكن يدويًا مع limit_glyphs
> >> wsv = WordSiv ( limit_glyphs = 'HAMBURGERFONTSIVhamburgerfontsiv' )
> >> wsv . sentence ( source = 'en_wordcount_web' )
'Manage miss ago are motor to rather at first to be of has forget'font_file و limit_glyphs قد يكون من المفيد في بعض الأحيان تحديد مجموعة الأحرف التي نريد عرضها ، واستخدام تلك الأحرف فقط إذا كان لدينا في ملف الخط. يمكننا القيام بذلك عن طريق تحديد كل من font_file و limit_glyphs :
> >> wsv = WordSiv (
... font_file = 'tests/data/noto-sans-subset.ttf' ,
... limit_glyphs = 'abcdefghijklmnop'
... )
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , min_wl = 3 )
'eng gnome gene game egg one aim him again one game one image boom' هناك مجموعة متنوعة من الطرق يمكن معالجة النص. فيما يلي بعض الأمثلة:
تتيح لنا كل من نماذج MarkovModel و WordCount نصًا كبيرًا أو صغيرًا ، سواء كانت الكلمات المصدرية أم لا أم لا:
> >> wsv = WordSiv ()
> >> wsv . sentence ( 'en_wordcount_web' , uc = True , max_sent_len = 8 )
'MAPLE CANVAS SPORTING PAGES TRANSFERRED, WITH SUPERIOR GOVERNMENT.'
> >> wsv . sentence (
... 'en_markov_gutenberg' , lc = True , min_sent_len = 7 , max_sent_len = 10
... )
'i besought the bosom of the sun so'راندودريل بالاستفادة من الجمل بشكل افتراضي ، لكن يمكننا إيقاف تشغيل هذا:
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , sent_len = 10 )
'egcs very and mortgage expressed about and online truss controls.'افتراضيًا ، تقوم نماذج WordCount بإدخال علامات الترقيم مع الاحتمالات المستمدة تقريبًا من الاستخدام في اللغة الإنجليزية.
يمكننا إيقاف هذا عن طريق تمرير وظيفتنا الخاصة لعلامات الترقيم:
> >> def only_period ( words , * args ): return ' ' . join ( words ) + '.'
> >> wsv . paragraph (
... source = 'en_wordcount_web' , punc_func = only_period , sent_len = 5 , para_len = 2
... )
'By schools sign I avoid. Or about fascism writers what.' لمزيد من التفاصيل حول punc_func ، راجع علامات الترقيم. ينطبق هذا فقط على نماذج WordCount ، حيث يستخدم MarkovModel علامات الترقيم في بيانات المصدر الخاصة به.
تعتني النماذج بتوليد الجمل والكلمات ، لذلك يتم التعامل مع المعلمات المتعلقة بهذه النماذج. في الوقت الحالي ، يرجى الرجوع إلى الكود المصدري لهذه النماذج لتعلم المعلمات المقبولة لـ word() و words() و sentence() APIs:
يعالج كائن Wordsiv نفسه sentences() ، paragraph() ، paragraphs() والمكالمات text مع معلماتها. راجع رمز مصدر فئة WordsIV لمعرفة كيفية تخصيص إخراج النص.
عند التخريب ، ربما نريد أن يظل دليلنا على حاله طالما أن لدينا نفس مجموعة الأحرف. هذا يساعدنا على مقارنة التغييرات في النوع.
لهذا السبب ، يستخدم Wordsiv مولد أرقام عشوائي واحد واحد ، يتم زرعه عند إنشاء كائن WordsIV. هذا يعني أن البرنامج النصي Python باستخدام هذه المكتبة سوف ينتج نفس النتيجة أينما تم تشغيله.
إذا كنت تريد أن ينشئ البرنامج النصي كلمات مختلفة ، فيمكنك أن ترفع كائن Wordsiv:
> >> wsv = WordSiv ( seed = 6 )
> >> wsv . sentence ( source = "en_markov_gutenberg" , min_sent_len = 7 )
'even if i forgot the go in their' بعد مشاهدة التحيز الوثائقي المشفر ، فكرت فيما إذا كان ينبغي لنا أن ننشئ نصًا استنادًا إلى البيانات التاريخية (أو حتى الحالية) ، بسبب التمييز الجنسي والعنصرية والاستعمار والخوف المثلي ، وما إلى ذلك ، الوارد في النصوص.
يحاول هذا القسم معالجة بعض هذه الأسئلة الأخلاقية التي نشأت بالنسبة لي (كريس باولي) ، ومحاولة توجيه هذا المشروع بعيدًا عن توليد النص الهجومي.
أولاً ، تم تصميم هذه المكتبة لأغراض:
بالطبع ، نقرأ بشكل طبيعي الكلمات (duh) ، لذلك من نافلة القول أنه يجب عليك الإشراف على النص الناتج عن هذه المكتبة.
فكرت إذا كانت هناك نصوص أكثر تقدمية يمكنني تدريب نموذج ماركوف على. ومع ذلك ، فإننا ندافع عن نص المصدر إلى عدم المعنى على أي حال ، لزيادة الجمل المصنوعة من مجموعة أحرف محدودة.
حتى النص الأكثر إيجابية يمكن أن يصبح الظلام سريعًا عند التدافع. نموذج ماركوف لحجم الدولة 1 (مثالي لمجموعات الشخصيات المحدودة) المدربين مع إعلان الأمم المتحدة العالمي لحقوق الإنسان جعل هذه الجملة:
Everyone is entitled to torture
or other limitation of brotherhood.
النقطة المهمة هي أن توليد الكلمات شبه العشوائية يدمر معنى النص ، فلماذا تهتم باختيار مصدر مدروس؟ ومع ذلك ، يجب أن نحاول حقًا الابتعاد عن مواد المصدر الهجومي ، لأن الأنماط الهجومية ستظهر إذا كان هناك أي احتمال.
إذا كنت ترغب في المساهمة بمصدر و/أو نموذج في هذا المشروع ، فإليك بعض الإرشادات:
على سبيل المثال ، نمنع MarkovModel من التقاط الكثير من السياق من النص الأصلي عن طريق الحفاظ على حجم الحالة 1. إن وجود حالة كلمة واحدة يزيد أيضًا من مقدار الجمل المحتملة أيضًا ، لذلك يعمل.
الجمل التي نولدها أقل منطقية ، ولكن بما أن هذا مصمم للنص الوهمية للتدقيق ، فهذا شيء جيد!
إنه تصفية صعبة من الكلمات "الهجومية" ، منذ:
نظرًا لأننا نولد نصًا غير منطقي للتدقيق ، يجب أن نبذل قصارى جهدنا لتصفية قوائم الكلمات من خلال قوائم الكلمات الهجومية. إذا كنت بحاجة حقًا إلى أقامات في النص الخاص بك ، فيمكنك إنشاء مصادر لأغراضك الخاصة.
لا يمكننا منع كلمات عشوائية من تشكيل جمل هجومية ، لكن يمكننا على الأقل تقييد الكلمات التي تميل إلى تكوين جمل هجومية.
ستستغرق النماذج الإحصائية مثل تلك المستخدمة في WordsIV الأنماط في النص - وخاصة عوامل MarkovModels. حاول اختيار مواد المصدر محايدة إلى حد ما (وليس أن أي شيء هو حقا ).
لقد دربت en_markov_gutenberg مع نصوص المجال العام هذه من NLTK ، والتي بدت آمنة بما يكفي لنموذج ماركوف غبي من أحادي الكلمات:
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
إذا لاحظت أي نماذج معينة تولد جملًا مسيئة أكثر من غيرها ، فيرجى تقديم مشكلة في REPO Wordsiv-Source-Packages.
أنا بالتأكيد لست أول من قام بإنشاء كلمات للتدقيق. تحقق من هذه المشاريع الرائعة ، واسمحوا لي أن أعرف ما إذا كنت تعرف المزيد يجب أن أضيف!
ربما لم أكن لأكون بعيدًا عن الإلهام لـ Word-O-Mat ، ونص Drawbot الجميل الذي شاركه Rob Stenson معي. هذا الأخير هو المكان الذي حصلت فيه على فكرة أن يبشر مولد الأرقام العشوائية لجعله حتميًا.
لقد استعارت أيضًا بشكل كبير من Spacy في كيفية إعداد حزم المصدر.
أريد أيضًا أن أشكر زوجتي بامي على الاستماع بلطف حيث أشرح كل تحدٍ باطني تعاملت معه ، وأقدم لي الدعم العاطفي عندما قمت بمسح 4 ساعات من العمل مع خطأ غير مبهم.


