wordsiv
1.0.0
Wordsiv는 제한된 문자 세트로 텍스트를 생성하기위한 파이썬 패키지입니다. 유형 교정을 위해 설계되었지만 리코 그램을 생성하는 데 유용 할 수 있습니다.
당신의 글꼴에 HAMBURGERFONTSIVhamburgerfontsiv 와 구두점이 있다고 가정 해 봅시다 ., Wordsiv는 다음과 같은 드라이브를 생성 할 수 있습니다.
사실, 위의 왕좌에서 그에게 충분히 벌금을 내면서, 처음에는 사업을위한 시간입니다. 그녀는 그가 기판에서도 자신이 생각으로 설정 한 것입니다. 나머지 부분은 그 문제에 대해 측정하는 운동의 절약이 아니 었습니다. Ahab은 정오에 보트에 보트에주는 것이 아닙니다.
서체를 설계하는 동안 부분 문자 세트로 텍스트를 검사하는 것이 유용합니다. Wordsiv는 가능한 글리프와 함께 현실적으로 보이는 텍스트를 생성하기 위해 최선을 다합니다.
먼저 PIP를 사용하여 WordSIV를 설치하십시오.
# we install straight from git (for now!)
$ pip install git+https://github.com/tallpauley/wordsiv # byexample: +pass다음으로 소스 패키지 repo의 릴리스 페이지에서 하나 이상의 소스 패키지를 설치하십시오.
$ base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass이제 파이썬에서 가짜 문장을 만들 수 있습니다!
> >> import wordsiv
> >> wsv = wordsiv . WordSiv ( limit_glyphs = ( 'HAMBURGERFONTSIVhamburgerfontsiv' ))
> >> wsv . sentence ( source = 'en_markov_gutenberg' )
( 'I might go over the instant to the streets in the air of those the same be '
'haunting' )DrawBot 앱에서 작업하기를 원한다면이 절차를 따라 Wordsiv를 설치할 수 있습니다.
Python-> Python 패키지 설치를 통해 wordsiv 패키지를 설치하십시오.
git+https://github.com/tallpauley/wordsiv 입력하고 이동을 클릭하십시오!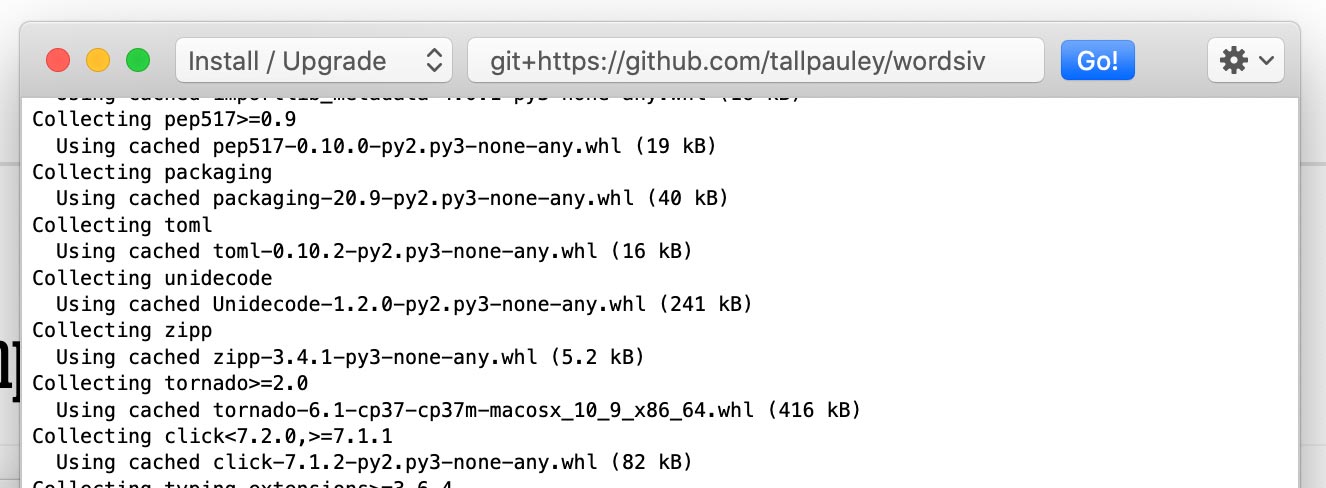
같은 창에 원하는 소스 패키지를 설치하지만 끝에 --no-deps 추가하십시오.
https://github.com/tallpauley/wordsiv-source-packages/releases/download/en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl --no-deps
.whl 또는 .tar.gz 패키지 URL을 복사 할 수 있습니다. DrawBot 스크립트를 작성하면 add_source_module() 사용하여 각 소스를 추가합니다.
import wordsiv
import en_wordcount_web
wsv = wordsiv . WordSiv ()
wsv . add_source_module ( en_wordcount_web )
print ( wsv . sentence ( source = "en_wordcount_web" ))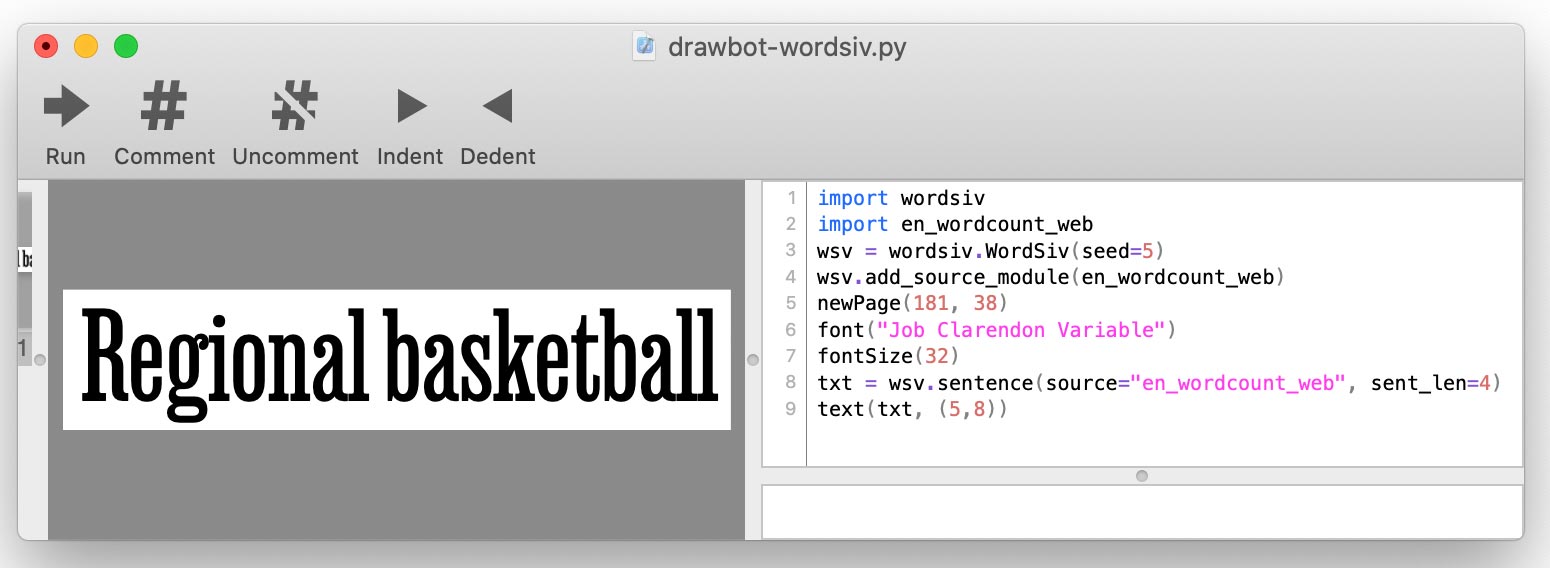
Wordsiv는 먼저 소스의 형태로 제공되는 단어가 필요합니다 : 원시 단어 데이터를 제공하는 개체.
이 소스는 단순히 파이썬 패키지 인 소스 패키지를 통해 제공됩니다. 일부를 설치합시다 :
base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
# A markov model trained on public domain books
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common English words compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common Trigrams compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_trigrams-0.1.0/en_wordcount_trigrams-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passWordsiv는 이러한 설치된 패키지를 자동으로 발견하고 이러한 소스를 즉시 사용할 수 있습니다. 현대 사용에서 영어로 가장 일반적인 단어를 가진 출처를 시도해 봅시다.
> >> from wordsiv import WordSiv
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )Wordsiv는 소스에서 문장으로 단어를 배열하는 방법을 어떻게 알 수 있습니까? 이것은 모델이 작용하는 곳입니다.
소스 en_wordcount_web 기본적으로 Model rand 사용합니다. 여기서는 위와 동일한 결과를 얻으려면 모델 rand 명시 적으로 선택합니다.
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' , model = "rand" )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )새 Wordsiv () 객체를 초기화 할 때 동일한 문장을받습니다. Wordsiv는 결정성으로 설계 되었기 때문입니다.
다소 자연스럽게 보이는 텍스트를 원한다면 Markovmodel ( model='mkv' )을 사용할 수 있습니다.
> >> wsv . paragraph ( source = "en_markov_gutenberg" , model = "mkv" ) # byexample: +skip
"Why don't think so desirous of hugeness. Our pie is worship..."Markov 모델은 실제 텍스트에 대한 교육을 받고 앞의 단어를 보면서 각 단어를 예측합니다. 우리는 가능한 한 많은 다른 문장을 생성하기 위해 (한 단어 상태) 가능한 한 바보 같은 모델을 유지합니다.
WordCount 소스 및 모델은 단어를 생성하기 위해 간단한 단어 및 발생 계수로 작동합니다.
randommodel ( model='rand' )은 발생 계수를 사용하여 더 인기있는 단어를 선호하는 단어를 무작위로 선택합니다.
# Default: probability by occurence count
> >> wsv . paragraph ( source = 'en_wordcount_web' , model = 'rand' ) # byexample: +skip
'Day music, commencement protection to threads who and dimension...'랜덤 델은 또한 발생 계수를 무시하고 단어를 완전히 무작위로 선택하도록 설정할 수 있습니다.
> >> wsv . sentence ( source = 'en_wordcount_web' , sent_len = 5 , prob = False ) # byexample: +skip
'Conceivably championships consecration ects— anointed.' 순차 모델 ( model='seq' )은 소스에 표시된 순서대로 단어를 뱉어냅니다. 이 모델을 사용하여 영어로 된 상위 5 개 트리 그램을 표시 할 수 있습니다.
> >> wsv . words ( source = 'en_wordcount_trigrams' , num_words = 5 ) # byexample: +skip
[ 'the' , 'ing' , 'and' , 'ion' , 'tio' ]Wordsiv는 불완전한 글꼴 파일로 글리프로 렌더링 할 수있는 단어를 선택한다는 아이디어를 중심으로 구축됩니다. Wordsiv는 글꼴 파일의 글리프가 무엇인지 자동으로 결정할 수 있습니다.
HAMBURGERFONTSIVhamburgerfontsiv 캐릭터로 글꼴을로드합시다
> >> wsv = WordSiv ( font_file = 'tests/data/noto-sans-subset.ttf' )
> >> wsv . sentence ( source = 'en_markov_gutenberg' , max_sent_len = 10 )
'Nor is fair to be in as these annuities' 우리는 같은 방식으로 글리프를 제한 할 수 있지만 limit_glyphs 로 수동으로
> >> wsv = WordSiv ( limit_glyphs = 'HAMBURGERFONTSIVhamburgerfontsiv' )
> >> wsv . sentence ( source = 'en_wordcount_web' )
'Manage miss ago are motor to rather at first to be of has forget'font_file 및 limit_glyphs 로 글리프를 제한합니다 표시하려는 문자 세트를 지정하고 글꼴 파일에있는 경우에만 해당 문자를 사용하는 것이 때때로 유용 할 수 있습니다. font_file 및 limit_glyphs 모두 지정하여이를 수행 할 수 있습니다.
> >> wsv = WordSiv (
... font_file = 'tests/data/noto-sans-subset.ttf' ,
... limit_glyphs = 'abcdefghijklmnop'
... )
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , min_wl = 3 )
'eng gnome gene game egg one aim him again one game one image boom' 텍스트를 조작 할 수있는 다양한 방법이 있습니다. 몇 가지 예는 다음과 같습니다.
MarkovModel과 WordCount 모델은 모두 소스 단어가 대문자가 있는지 여부에 관계없이 대문자 또는 소문자 텍스트를 허용합니다.
> >> wsv = WordSiv ()
> >> wsv . sentence ( 'en_wordcount_web' , uc = True , max_sent_len = 8 )
'MAPLE CANVAS SPORTING PAGES TRANSFERRED, WITH SUPERIOR GOVERNMENT.'
> >> wsv . sentence (
... 'en_markov_gutenberg' , lc = True , min_sent_len = 7 , max_sent_len = 10
... )
'i besought the bosom of the sun so'랜덤 델은 기본적으로 문장을 가체화하지만이를 끄질 수 있습니다.
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , sent_len = 10 )
'egcs very and mortgage expressed about and online truss controls.'기본적으로 WordCount Models는 영어의 사용에서 대략 파생 된 확률로 구두점을 삽입합니다.
구두점에 대한 우리 자신의 기능을 전달하여 이것을 끄질 수 있습니다.
> >> def only_period ( words , * args ): return ' ' . join ( words ) + '.'
> >> wsv . paragraph (
... source = 'en_wordcount_web' , punc_func = only_period , sent_len = 5 , para_len = 2
... )
'By schools sign I avoid. Or about fascism writers what.' punc_func 에 대한 자세한 내용은 purceation.py를 참조하십시오. Markovmodel이 소스 데이터에서 구두점을 사용하기 때문에 WordCount 모델에만 적용됩니다.
모델은 문장 과 단어를 생성하는 것을 처리하므로 이와 관련된 매개 변수는 모델에 의해 처리됩니다. 지금은 word() , words() 및 sentence() API에 허용되는 매개 변수를 배우려면이 모델의 소스 코드를 참조하십시오.
Wordsiv 객체 자체는 sentences() , paragraph() , paragraphs() 및 text 호출을 매개 변수로 처리합니다. 텍스트 출력을 사용자 정의하는 방법을 배우려면 Wordsiv 클래스 소스 코드를 참조하십시오.
유형을 교정 할 때, 우리는 동일한 문자 세트가있는 한 증거가 동일하게 유지되기를 원할 것입니다. 이것은 유형의 변화를 비교하는 데 도움이됩니다.
이러한 이유로 Wordsiv는 wordiv 객체를 생성 할 때 파종되는 단일 의사-랜덤 번호 생성기를 사용합니다. 이것은이 라이브러리를 사용하는 파이썬 스크립트가 실행되는 곳마다 동일한 결과를 생성한다는 것을 의미합니다.
스크립트가 다른 단어를 생성하려면 WordSIV 객체를 시드 할 수 있습니다.
> >> wsv = WordSiv ( seed = 6 )
> >> wsv . sentence ( source = "en_markov_gutenberg" , min_sent_len = 7 )
'even if i forgot the go in their' 다큐멘터리 코드 편견을 본 후, 나는 본문에 포함 된 성 차별, 인종 차별, 식민주의, 동성애 공포증 등으로 인해 역사적 (또는 현재) 데이터를 기반으로 텍스트를 생성 해야하는지 여부를 고려했습니다.
이 섹션은 저에게 발생한 이러한 윤리적 질문 중 일부 (Chris Pauley)를 다루려고 시도 하고이 프로젝트를 공격적인 텍스트를 생성하지 못하게하려고합니다.
우선,이 라이브러리는 다음의 목적으로 설계되었습니다.
물론, 우리는 자연스럽게 단어 (DUH)를 읽으 므로이 라이브러리에서 생성 된 텍스트를 감독해야한다는 것은 말할 것도 없습니다.
Markov 모델을 훈련시킬 수있는 더 진보적 인 텍스트가 있는지 여부를 고려했습니다. 그러나, 우리는 어쨌든 소스 텍스트를 무의미 함으로, 제한된 문자 세트로 만든 문장을 극대화합니다.
가장 긍정적 인 텍스트조차도 스크램블하면 실제로 어두워 질 수 있습니다. 유엔 보편적 인 인권 선언으로 훈련 된 국가 규모 1 (제한된 캐릭터 세트에 이상적)의 Markov 모델 이이 문장을 만들었습니다.
Everyone is entitled to torture
or other limitation of brotherhood.
요점은 반 랜덤 워드 세대가 텍스트의 의미를 망치게하는데 왜 사려 깊은 출처를 고르는가? 그러나 우리는 불쾌한 소스 자료를 피하려고 노력해야합니다. 왜냐하면 가능성이 관련된 경우 공격 패턴이 나타나기 때문입니다.
이 프로젝트에 소스 및/또는 모델을 기여하고 싶다면 다음은 다음과 같습니다.
예를 들어, 우리는 상태 크기를 1의 상태로 유지하여 Markovmodel이 원본 텍스트에서 너무 많은 컨텍스트를 선택하지 못하게합니다. 단일 단어 상태를 갖는 것도 잠재적 문장의 양도 증가하므로 작동합니다.
우리가 생성하는 문장은 덜 의미가 있지만, 이것은 교정을 위해 더미 텍스트를 위해 설계되었으므로 이것은 좋은 것입니다!
"공격적인"단어를 필터링하는 것은 까다로운 일입니다.
교정을 위해 무의미한 텍스트를 생성하기 때문에 불쾌한 단어 목록으로 단어 목록을 필터링하기 위해 최선을 다해야합니다. 텍스트에서 맹세가 필요한 경우 자신의 목적을 위해 소스를 만들 수 있습니다.
우리는 임의의 단어가 불쾌한 문장을 형성하는 것을 막을 수는 없지만 적어도 공격적인 문장을 형성하는 경향이있는 단어를 제한 할 수 있습니다.
WordSiv에 사용 된 것과 같은 통계 모델은 텍스트의 패턴, 특히 Markovmodels를 선택합니다. 상당히 중립적 인 소스 자료를 선택하십시오 ( 실제로 는 아닙니다).
나는 NLTK의 이러한 공개 도메인 텍스트로 EN_Markov_gutenberg를 훈련 시켰습니다.
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
공세 문장을 생성하는 특정 모델을 발견하면 Wordsiv-Source-Packages Repo에 문제를 제기하십시오.
나는 확실히 교정을 위해 단어를 생성 한 최초의 것은 아닙니다. 이 멋진 프로젝트를 확인하고 더 많은 것을 추가해야한다면 알려주십시오.
나는 아마도 Word-O-Mat의 영감과 Rob Stenson이 나와 공유 한 멋진 Drawbot 스크립트 없이는 그리 멀지 않았을 것입니다. 후자는 내가 무작위 숫자 생성기를 시드하여 결정적으로 만드는 아이디어를 얻은 곳입니다.
또한 소스 패키지를 설정하는 방법에서 Spacy에서 많이 빌려 왔습니다.
또한 내가 다루었던 각 난해한 도전을 설명하고 부주의 한 실수로 4 시간의 일을 거의 지우 셨을 때 감정적 인 지원을 빌려 주면서 친절하게 듣는 것에 대해 아내 Pammy에게 감사의 말씀을 전합니다.


