wordsiv
1.0.0
Wordsiv é um pacote Python para gerar texto com um conjunto de caracteres limitado. Ele foi projetado para prova de tipo, mas pode ser útil para gerar lipogramas.
Digamos que você tenha as cartas HAMBURGERFONTSIVhamburgerfontsiv e Pontuação ., Em sua fonte. Wordsiv pode gerar a seguinte bobagem:
É verdade que, para uma multa o suficiente para ele nos tronos acima, algum tempo para isso primeiro o negócio. Ela é que ele se estabeleceu como um pensamento que ele mesmo de seus substratos, é o resto que não é as coisas que a economia de um movimento que ele mede sobre o assunto, Ahab dá aos barcos ao meio -dia ou da floresta verde, assim como em Ahab.
Ao projetar um tipo de letra, é útil examinar o texto com um conjunto parcial de caracteres. O Wordsiv tenta o melhor para gerar texto realista com os glifos disponíveis.
Primeiro, instale o Wordsiv com Pip:
# we install straight from git (for now!)
$ pip install git+https://github.com/tallpauley/wordsiv # byexample: +passEm seguida, instale um ou mais pacotes de origem na página de lançamentos do repositório de pacotes de origem:
$ base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passAgora você pode fazer frases falsas em Python!
> >> import wordsiv
> >> wsv = wordsiv . WordSiv ( limit_glyphs = ( 'HAMBURGERFONTSIVhamburgerfontsiv' ))
> >> wsv . sentence ( source = 'en_markov_gutenberg' )
( 'I might go over the instant to the streets in the air of those the same be '
'haunting' )Se você preferir trabalhar no aplicativo Drawbot, pode seguir este procedimento para instalar o Wordsiv:
Instale o pacote wordsiv via Python-> Instale os pacotes Python :
git+https://github.com/tallpauley/wordsiv e clique em Go!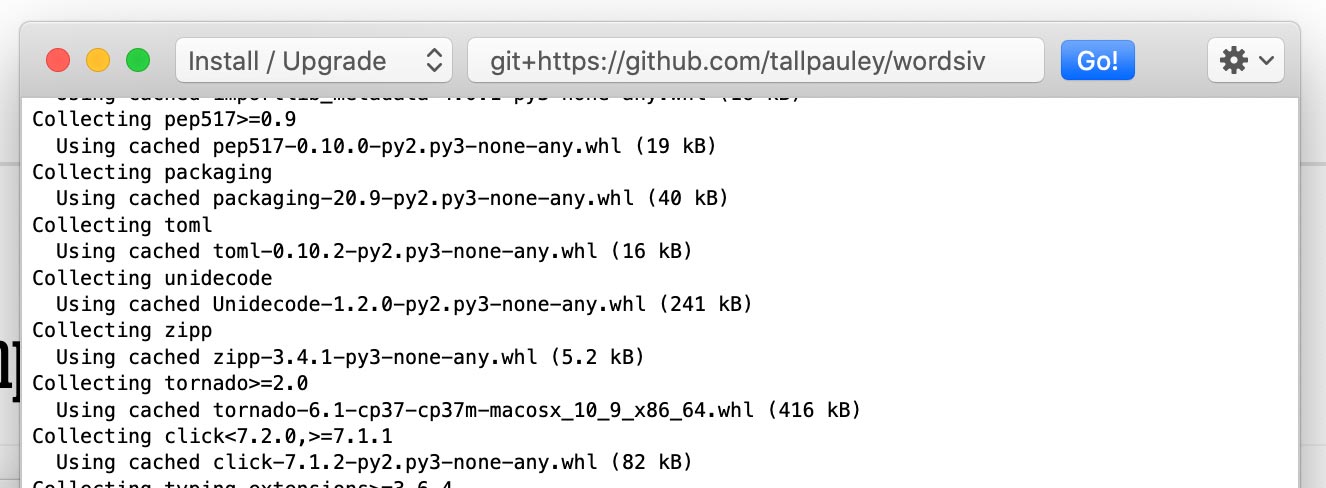
Instale os pacotes de origem desejados na mesma janela, mas adicione --no-deps no final:
https://github.com/tallpauley/wordsiv-source-packages/releases/download/en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl --no-deps
.whl ou .tar.gz da página de lançamentos de Pacotes de Origem de Origem sob os ativos suspensos. Ao escrever seu script de drawbot, você adicionará cada fonte usando add_source_module() :
import wordsiv
import en_wordcount_web
wsv = wordsiv . WordSiv ()
wsv . add_source_module ( en_wordcount_web )
print ( wsv . sentence ( source = "en_wordcount_web" ))
O Wordsiv primeiro precisa de algumas palavras, que vêm na forma de fontes: objetos que fornecem os dados do Word Raw.
Essas fontes estão disponíveis por meio de pacotes de origem, que são simplesmente pacotes Python. Vamos instalar alguns:
base=https://github.com/tallpauley/wordsiv-source-packages/releases/download
# A markov model trained on public domain books
$ pkg=en_markov_gutenberg-0.1.0/en_markov_gutenberg-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common English words compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_web-0.1.0/en_wordcount_web-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +pass
# Most common Trigrams compiled by Peter Norvig with data from Google
$ pkg=en_wordcount_trigrams-0.1.0/en_wordcount_trigrams-0.1.0-py3-none-any.whl
$ pip install $base / $pkg # byexample: +passWordsIV descobre automaticamente esses pacotes instalados e pode usar essas fontes imediatamente. Vamos tentar uma fonte com as palavras mais comuns no idioma inglês no uso moderno:
> >> from wordsiv import WordSiv
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )Como um Wordsiv sabe como organizar palavras de uma fonte em uma frase? É aqui que os modelos entram em jogo.
A origem en_wordcount_web usa o modelo rand por padrão. Aqui, selecionamos explicitamente o modelo rand para alcançar o mesmo resultado que acima:
> >> wsv = WordSiv ()
> >> wsv . sentence ( source = 'en_wordcount_web' , model = "rand" )
( 'Maple canvas sporting pages transferred with superior government brand with '
'women for key assign.' )Observe que recebemos a mesma frase quando inicializamos um novo objeto wordsiv (). Isso ocorre porque o Wordsiv foi projetado para ser determinisico.
Se queremos o texto que seja um tanto natural , podemos usar nosso Markovmodel ( model='mkv' ).
> >> wsv . paragraph ( source = "en_markov_gutenberg" , model = "mkv" ) # byexample: +skip
"Why don't think so desirous of hugeness. Our pie is worship..."Um modelo de Markov é treinado em texto real e prevê cada palavra observando as palavras anteriores. Mantemos o modelo o mais estúpido possível (um estado de uma palavra) para gerar o maior número possível de frases diferentes.
Fontes e modelos do WordCount funcionam com listas simples de palavras e contagens de ocorrência para gerar palavras.
O Randommommodel ( model='rand' ) usa contagens de ocorrência para escolher aleatoriamente palavras, favorecendo as palavras mais populares:
# Default: probability by occurence count
> >> wsv . paragraph ( source = 'en_wordcount_web' , model = 'rand' ) # byexample: +skip
'Day music, commencement protection to threads who and dimension...'O Randommommodel também pode ser definido para ignorar a contagem de ocorrências e escolher palavras completamente aleatoriamente:
> >> wsv . sentence ( source = 'en_wordcount_web' , sent_len = 5 , prob = False ) # byexample: +skip
'Conceivably championships consecration ects— anointed.' O sequencialModel ( model='seq' ) cospe as palavras na ordem em que aparecem na fonte. Poderíamos usar esse modelo para exibir os 5 principais trigrramas do idioma inglês:
> >> wsv . words ( source = 'en_wordcount_trigrams' , num_words = 5 ) # byexample: +skip
[ 'the' , 'ing' , 'and' , 'ion' , 'tio' ]O Wordsiv é construído em torno da idéia de selecionar palavras que podem ser renderizadas com os glifos em um arquivo de fonte incompleto. O Wordsiv pode determinar automaticamente o que os glifos estão em um arquivo de fonte.
Vamos carregar uma fonte com os personagens HAMBURGERFONTSIVhamburgerfontsiv
> >> wsv = WordSiv ( font_file = 'tests/data/noto-sans-subset.ttf' )
> >> wsv . sentence ( source = 'en_markov_gutenberg' , max_sent_len = 10 )
'Nor is fair to be in as these annuities' Podemos limitar os glifos da mesma maneira, mas manualmente com limit_glyphs
> >> wsv = WordSiv ( limit_glyphs = 'HAMBURGERFONTSIVhamburgerfontsiv' )
> >> wsv . sentence ( source = 'en_wordcount_web' )
'Manage miss ago are motor to rather at first to be of has forget'font_file e limit_glyphs Às vezes, pode ser útil especificar o conjunto de caracteres que queremos exibir e apenas usando esses caracteres, se os tivermos no arquivo de fonte. Podemos fazer isso especificando font_file e limit_glyphs :
> >> wsv = WordSiv (
... font_file = 'tests/data/noto-sans-subset.ttf' ,
... limit_glyphs = 'abcdefghijklmnop'
... )
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , min_wl = 3 )
'eng gnome gene game egg one aim him again one game one image boom' Existem várias maneiras pelas quais o texto pode ser manipulado. Aqui estão alguns exemplos:
Os modelos Markovmodel e WordCount nos permitem maçarico ou texto em minúsculas, se as palavras de origem são ou não capitalizadas ou não:
> >> wsv = WordSiv ()
> >> wsv . sentence ( 'en_wordcount_web' , uc = True , max_sent_len = 8 )
'MAPLE CANVAS SPORTING PAGES TRANSFERRED, WITH SUPERIOR GOVERNMENT.'
> >> wsv . sentence (
... 'en_markov_gutenberg' , lc = True , min_sent_len = 7 , max_sent_len = 10
... )
'i besought the bosom of the sun so'O Randododel, capitaliza as frases por padrão, mas podemos desativar isso:
> >> wsv . sentence ( 'en_wordcount_web' , cap_sent = False , sent_len = 10 )
'egcs very and mortgage expressed about and online truss controls.'Por padrão, os modelos WordCount inserem pontuação com probabilidades derivadas aproximadamente do uso no idioma inglês.
Podemos desligar isso passando nossa própria função para pontuação:
> >> def only_period ( words , * args ): return ' ' . join ( words ) + '.'
> >> wsv . paragraph (
... source = 'en_wordcount_web' , punc_func = only_period , sent_len = 5 , para_len = 2
... )
'By schools sign I avoid. Or about fascism writers what.' Para mais detalhes sobre punc_func , consulte a pontuação.py. Isso se aplica apenas aos modelos WordCount, pois o Markovmodel usa a pontuação nos dados de origem.
Os modelos cuidam da geração de frases e palavras ; portanto, os parâmetros relacionados a eles são tratados pelos modelos. Por enquanto, consulte o código -fonte para esses modelos aprender os parâmetros aceitos para word() , words() e sentence() APIs:
O próprio objeto wordsiv lida com sentences() , paragraph() , paragraphs() e chamadas text com seus parâmetros. Consulte o código -fonte da classe wordsiv para aprender como personalizar a saída de texto.
Quando o tipo de prova, provavelmente queremos que nossa prova permaneça a mesma, desde que tenhamos o mesmo conjunto de personagens. Isso nos ajuda a comparar alterações no tipo.
Por esse motivo, o Wordsiv usa um único gerador de números pseudo-aleatórios, que é semeado na criação do objeto Wordsiv. Isso significa que um script python usando esta biblioteca produzirá o mesmo resultado onde quer que ele seja executado.
Se você deseja que seu script gere palavras diferentes, você pode semear o objeto Wordsiv:
> >> wsv = WordSiv ( seed = 6 )
> >> wsv . sentence ( source = "en_markov_gutenberg" , min_sent_len = 7 )
'even if i forgot the go in their' Depois de assistir ao viés codificado pelo documentário, considerei se deveríamos gerar texto com base em dados históricos (ou mesmo atuais), devido ao sexismo, racismo, colonialismo, homofobia etc., contidos nos textos.
Esta seção tenta abordar algumas dessas questões éticas que surgiram para mim (Chris Pauley) e tentar afastar esse projeto da geração de texto ofensivo.
Primeiro, esta biblioteca foi projetada para fins de:
Obviamente, lemos naturalmente palavras (duh), por isso é preciso dizer que você deve supervisionar o texto gerado por esta biblioteca.
Eu considerei se houvesse textos mais progressistas em que eu poderia treinar um modelo de Markov. No entanto, estamos subindo o texto de origem para a falta de sentido, para maximizar as frases feitas com um conjunto limitado de caracteres.
Mesmo o texto mais positivo pode ficar escuro muito rápido quando mexido. Um modelo de Markov de tamanho 1 (ideal para conjuntos de caracteres limitados) treinado com a declaração universal da ONU dos direitos humanos fez esta frase:
Everyone is entitled to torture
or other limitation of brotherhood.
O ponto é que a geração de palavras semi-aleatórias arruina o significado do texto, então por que se preocupar em escolher uma fonte atenciosa? No entanto, devemos realmente tentar ficar longe do material de origem ofensivo, porque os padrões ofensivos aparecerão se houver alguma probabilidade envolvida.
Se você deseja contribuir com uma fonte e/ou modelo para este projeto, aqui estão algumas diretrizes:
Por exemplo, impedimos Markovmodel de captar muito contexto do texto original, mantendo um tamanho de estado de 1. Ter um único estado de palavra também aumenta a quantidade de frases em potencial também, para que funcione.
As frases que geramos fazem menos sentido, mas como isso foi projetado para texto fictício para prova, isso é uma coisa boa!
É complicado filtrar palavras "ofensivas", já que:
Como estamos gerando texto sem sentido para a prova, devemos tentar o possível para filtrar listas de palavras por listas de palavras ofensivas. Se você realmente precisar de jurados em seu texto, pode criar fontes para seus próprios propósitos.
Não podemos impedir que as palavras aleatórias formem frases ofensivas, mas podemos pelo menos restringir as palavras que tendem a formar sentenças ofensivas.
Modelos estatísticos como os usados no Wordsiv captarão padrões no texto - especialmente Markovmodels. Tente escolher material de origem que seja bastante neutro (não que algo realmente seja).
Treinei en_markov_gutenberg com esses textos de domínio público do NLTK, que pareciam seguro o suficiente para um modelo de Markov idiota e de um estado único:
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt',
'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt',
'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt',
'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt',
'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt',
'shakespeare-macbeth.txt', 'whitman-leaves.txt']
Se você notar algum modelo específico que gera frases ofensivas mais do que não, registre um problema no repo Wordsiv-Source-Packages.
Definitivamente, não sou o primeiro a gerar palavras para prova. Confira esses projetos legais e deixe -me saber se você souber mais, eu devo acrescentar!
Eu provavelmente não teria chegado muito longe sem a inspiração do Word-O-MAT, e um bom script de drawbot que Rob Stenson compartilhou comigo. O último é onde tive a idéia de semear o gerador de números aleatórios para torná -lo determinístico.
Também peguei emprestado fortemente da Spacy na maneira como configurei os pacotes de origem.
Também quero agradecer à minha esposa Pammy por ouvir gentilmente, enquanto explico cada desafio esotérico que eu abordava, e me emprestando apoio emocional quando quase eliminei 4 horas de trabalho com um erro descuidado.


