3DDFA_V2
v0.12 Release Notes
由江朱郭,木安朱,杨杨,范杨,Zhen Lei和Stan Z. li。代码仓库由江郭拥有和维护。

[更新]
2021.7.10 :在Gradio上在线运行3DDFA_V2。2021.1.15 :借用更快的网格渲染(加速约3倍,15ms-> 4ms)的密集置端估计的实现,请参见UTILS/RENDER_CTYPES.PY。2020.10.7 :添加延迟中的完整管道的延迟评估,刚刚由python3 latency.py --onnx运行,有关详细信息,请参见延迟评估。2020.10.6 :添加对面包箱的onnxRuntime支持,以减少面部检测延迟,只需附加--onnx操作即可激活它,请参见Faceboxes_onnx.py有关详细信息。2020.10.2 :添加onnxRuntime支持以大大减少3DMM参数推理潜伏期,只需在运行demo.py时附加--onnx操作,请参见tddfa_onnx.py。2020.9.20 :添加功能,包括姿势obj和序列ply pose2020.9.19 :添加PNCC(预计的归一级坐标代码),UV纹理映射功能,请参见Demo.py中的pncc , uv_tex选项。 这项工作扩展了3DDFA,称为3DDFA_V2 ,标题为ECCV 2020接受快速,准确和稳定的3D致密面对齐。补充材料在这里。在我的实验室的情况下,上面的GIF显示了跟踪结果的网络摄像头演示。此存储库是3DDFA_V2的官方实施。
与3DDFA相比,3DDFA_V2实现了更好的性能和稳定性。此外,3DDFA_V2还包含快速面探测器的面包箱,而不是DLIB。还包括一个由C ++和Cython编写的简单3D渲染。此存储库支持OnnxRuntime,并且使用默认骨架进行回归3MM参数的延迟约为CPU上的1.35ms/Image,单个图像作为输入。如果您对此存储库有兴趣,只需在此Google Colab上尝试一下即可!欢迎有宝贵的问题,公关和讨论吗?
请参阅要求。TXT,在MACOS和Linux平台上进行了测试。 Windows用户可能会参考FQA建筑问题。请注意,此存储库使用Python3。主要依赖项是pytorch, brew install libomp ,opencv --onnx python和onXruntime libomp 。
git clone https://github.com/cleardusk/3DDFA_V2.git
cd 3DDFA_V2sh ./build.sh # 1. running on still image, the options include: 2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj
python3 demo.py -f examples/inputs/emma.jpg --onnx # -o [2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj]
# 2. running on videos
python3 demo_video.py -f examples/inputs/videos/214.avi --onnx
# 3. running on videos smoothly by looking ahead by `n_next` frames
python3 demo_video_smooth.py -f examples/inputs/videos/214.avi --onnx
# 4. running on webcam
python3 demo_webcam_smooth.py --onnx跟踪的实现仅仅是通过对齐方式。如果头部姿势> 90°或运动太快,则对齐可能会失败。阈值用于棘手检查跟踪状态,但不稳定。
您可以参考Demo.ipynb或Google Colab,以获取在静止图像上运行的分步教程。
例如,运行python3 demo.py -f examples/inputs/emma.jpg -o 3d将给出以下结果:
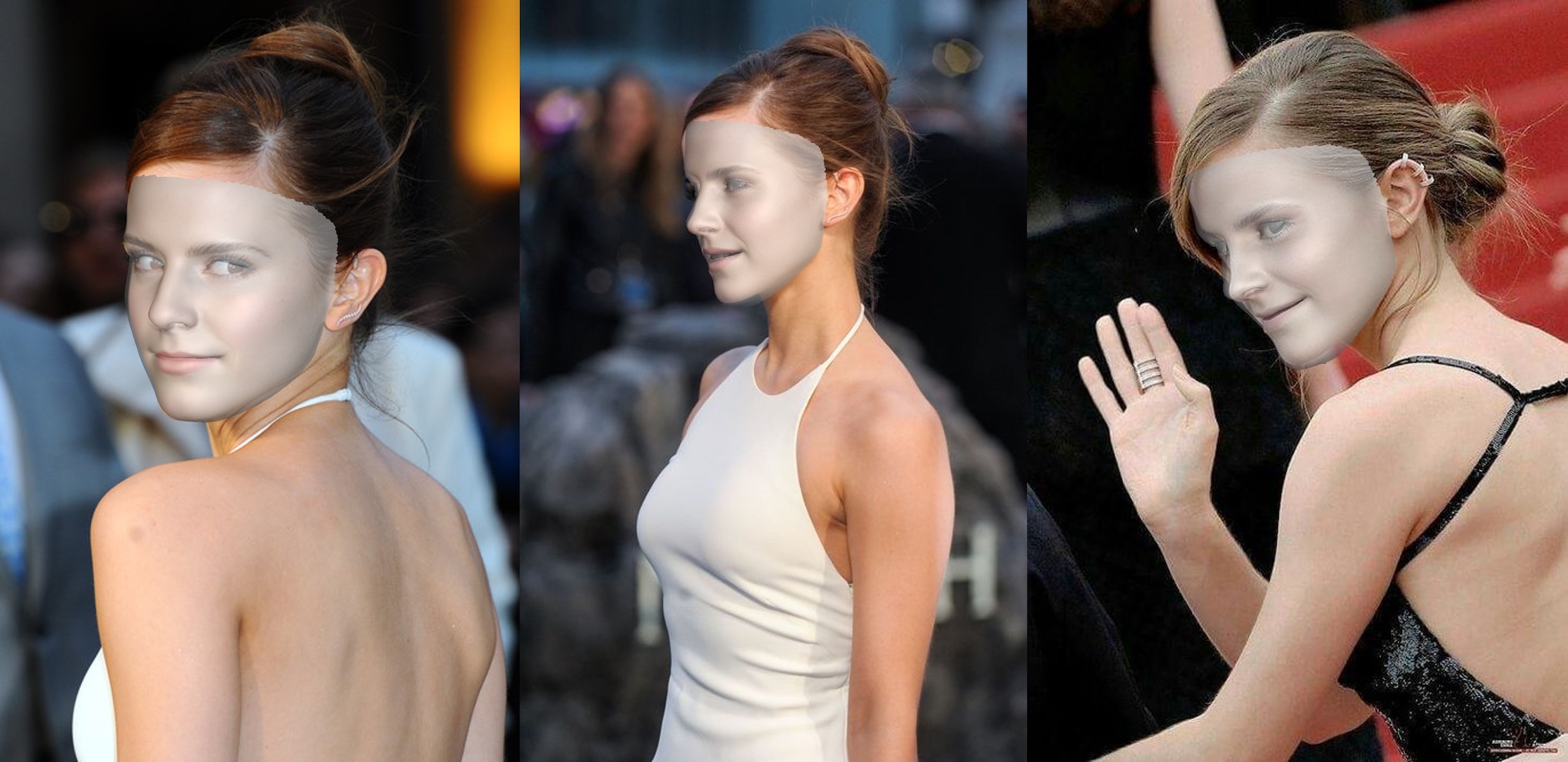
另一个例子:

在视频上运行将给出:

更多结果或演示可以看到:Hathaway。
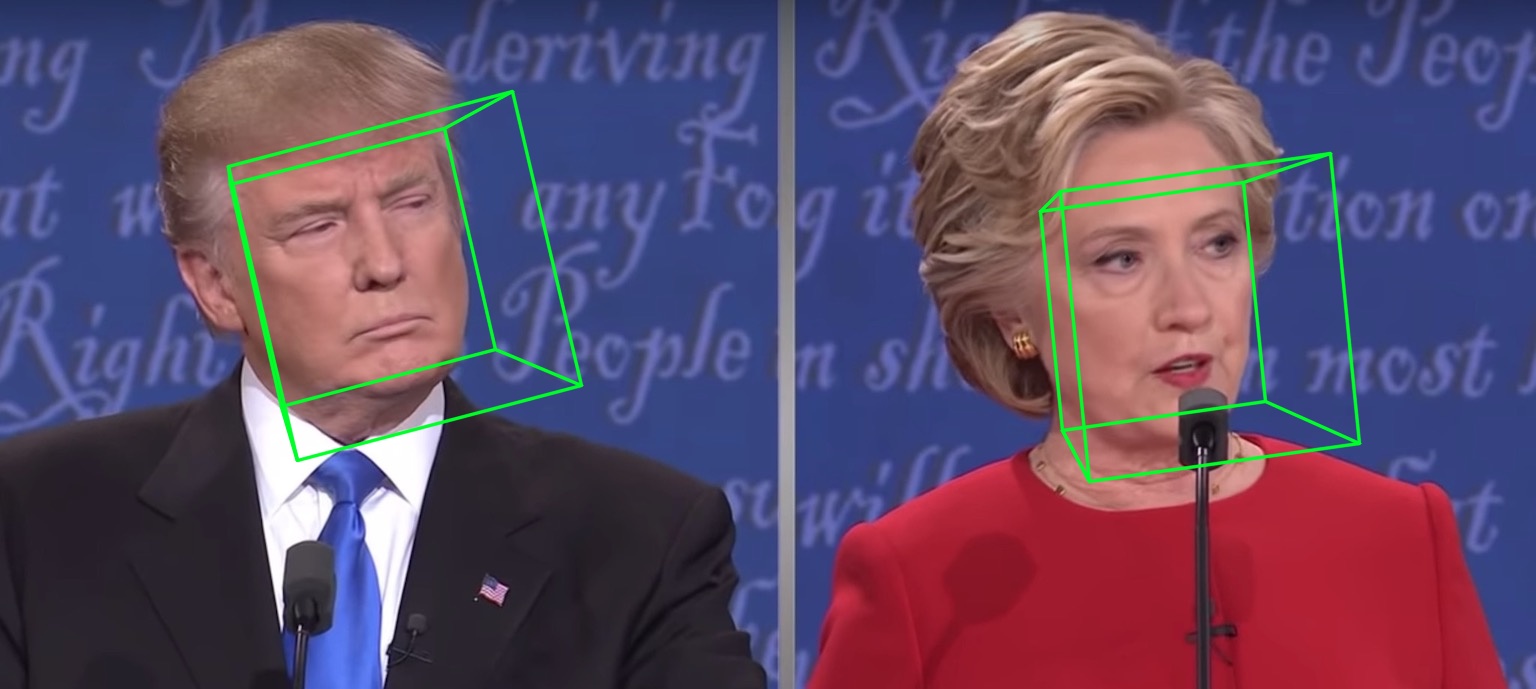
| 2D稀疏 | 2D密集 | 3D |
|---|---|---|
 |  |  |
| 深度 | PNCC | 紫外线纹理 |
 |  |  |
| 姿势 | 序列化为.ply | 序列化为.obj |
 |  | 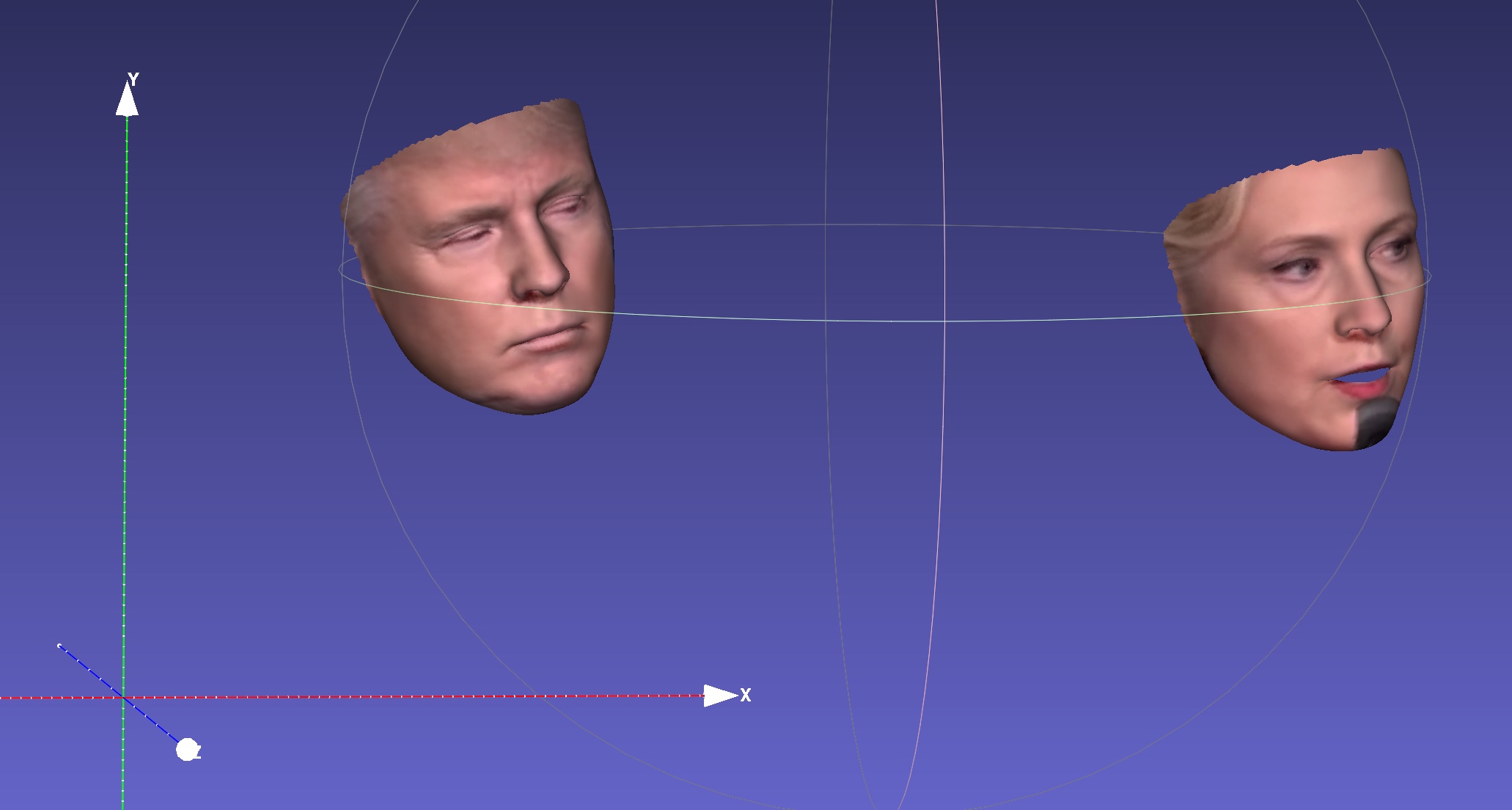 |
默认的主链是Mobilenet_v1,其输入尺寸为120x120,默认的预训练重量为weights/mb1_120x120.pth ,如configs/mb1_120x120.yml所示。该仓库在Configs/MB05_120X120.yml中提供了另一种配置,其0.5较宽,较小,更快。您可以通过-c或--config选项指定配置。发布的模型显示在下表中。请注意,使用TensorFlow评估CPU上CPU的推断时间。
| 模型 | 输入 | #params | #macs | 推理(TF) |
|---|---|---|---|---|
| Mobilenet | 120x120 | 327万 | 18350万 | 〜6.2ms |
| Mobilenet X0.5 | 120x120 | 0.85m | 49.5m | 〜2.9ms |
令人惊讶的是,OnnxRuntime的延迟要小得多。带有不同线程的CPU上的推理时间如下所示。结果在我的MBP(I5-8259U CPU @ 2.30GHz上的13英寸MacBook Pro)上进行了测试,并使用1.5.1版本的OnnXruntime进行了测试。线程号由os.environ["OMP_NUM_THREADS"]设置,有关更多详细信息,请参见speed_cpu.py。
| 模型 | 线程= 1 | 线程= 2 | 线程= 4 |
|---|---|---|---|
| Mobilenet | 4.4ms | 2.25ms | 1.35ms |
| Mobilenet X0.5 | 1.37ms | 0.7ms | 0.5ms |
onnx选项大大降低了整体CPU延迟,但面部检测仍然占用大部分延迟时间,例如15毫秒,用于720p图像。 3DMM参数回归需要一张面的大约1〜2ms,而密集的重建(超过30,000点,即38,365)约为1ms。跟踪应用程序可能会受益于快速3DMM回归速度,因为每个帧都不需要检测。使用我的13英寸MacBook Pro(i5-8259U CPU @ 2.30GHz)对延迟进行测试。
默认的OMP_NUM_THREADS设置为4,您可以通过设置os.environ['OMP_NUM_THREADS'] = '$NUM'或在运行Python脚本之前插入export OMP_NUM_THREADS=$NUM 。
什么是培训数据?
我们使用300W-LP进行培训。您可以参考我们的论文以获取有关培训的更多详细信息。由于训练数据300W-LP中很少有图像是闭合眼睛,因此关闭时的眼睛标志不准确。网络摄像头演示的一部分也不好。
在Windows上运行。
您可以参考此评论以在Windows上构建NMS。
如果您的工作或研究受益于此存储库,请在下面引用两个围兜:)和?这个存储库。
@inproceedings{guo2020towards,
title = {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author = {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
Jianzhu guo(郭建珠) [Homepage,Google Scholar]: [email protected]或[email protected]或[email protected] (此电子邮件很快就会无效)。


