3DDFA_V2
v0.12 Release Notes
Par Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei et Stan Z. Li. Le repo du code est détenu et entretenu par Jianzhu Guo .

[Mises à jour]
2021.7.10 : Exécutez 3DDFA_V2 en ligne sur Gradio.2021.1.15 : emprunter la mise en œuvre d'une estimation de la pose de tête dense pour le rendu de maillage plus rapide (accélérer environ 3x, 15 ms -> 4 ms), voir utils / render_ctypes.py pour plus de détails.2020.10.7 : Ajoutez l'évaluation de la latence du pipeline complet dans latence.py, juste exécuté par python3 latency.py --onnx , voir l'évaluation de latence pour plus de détails.2020.10.6 : Ajoutez une prise en charge onnxruntime pour FACEBOXES pour réduire la latence de détection de visage, ajoutez simplement l'action --onnx pour l'activer, voir faceboxes_onnx.py pour plus de détails.2020.10.2 : Ajoutez un support Onnxruntime pour réduire considérablement la latence d'inférence des paramètres 3DMM , ajoutez simplement l'action --onnx Lors de l'exécution demo.py , voir tddfa_onnx.py pour plus de détails.2020.9.20 : Ajouter des fonctionnalités, y compris l'estimation de la pose et les sérialisations à .ply et .obj, voir pose , ply , les options obj dans Demo.py.2020.9.19 : Ajouter PNCC (code de coordonnée normalisé projeté), fonctionnalités de mappage de texture UV, voir les options pncc , uv_tex dans Demo.py. Ce travail étend 3DDFA, nommé 3DDFA_V2 , intitulé vers l'alignement de la face 3D rapide, précis et stable, accepté par ECCV 2020. Le matériel supplémentaire est ici. Le GIF ci-dessus montre une démo webcam du résultat de suivi, dans le scénario de mon laboratoire. Ce dépôt est la mise en œuvre officielle de 3DDFA_V2.
Par rapport à la 3DDFA, 3DDFA_V2 atteint de meilleures performances et stabilité. En outre, 3DDFA_V2 intègre les boîtes face-face du détecteur de face rapide au lieu de DLIB. Un simple rendu 3D écrit par C ++ et Cython est également inclus. Ce repo prend en charge l'Onnxruntime, et la latence de la régression des paramètres 3DMM en utilisant la squelette par défaut est d'environ 1,35 ms / image sur CPU avec une seule image en entrée. Si vous êtes intéressé par ce dépôt, essayez-le simplement sur ce Google Colab ! Bienvenue pour des problèmes, des RP et des discussions précieux?
Voir exigences.txt, testé sur les plates-formes macOS et Linux. Les utilisateurs de Windows peuvent se référer à la FQA pour la création de problèmes. Notez que ce repo utilise Python3. Les principales dépendances sont Pytorch, Numpy, OpenCV-Python et ONNXRUNTime, etc. Si vous exécutez les démos avec un drapeau --onnx pour faire l'accélération, vous devrez peut-être installer libomp en premier, c'est-à-dire, brew install libomp sur MacOS.
git clone https://github.com/cleardusk/3DDFA_V2.git
cd 3DDFA_V2sh ./build.sh # 1. running on still image, the options include: 2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj
python3 demo.py -f examples/inputs/emma.jpg --onnx # -o [2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj]
# 2. running on videos
python3 demo_video.py -f examples/inputs/videos/214.avi --onnx
# 3. running on videos smoothly by looking ahead by `n_next` frames
python3 demo_video_smooth.py -f examples/inputs/videos/214.avi --onnx
# 4. running on webcam
python3 demo_webcam_smooth.py --onnxLa mise en œuvre du suivi est simplement par alignement. Si la tête pose> 90 ° ou si le mouvement est trop rapide, l'alignement peut échouer. Un seuil est utilisé pour vérifier trop l'état de suivi, mais il est instable.
Vous pouvez vous référer à Demo.ipynb ou Google Colab pour le tutoriel étape par étape de l'exécution sur l'image calme.
Par exemple, l'exécution python3 demo.py -f examples/inputs/emma.jpg -o 3d donnera le résultat ci-dessous:
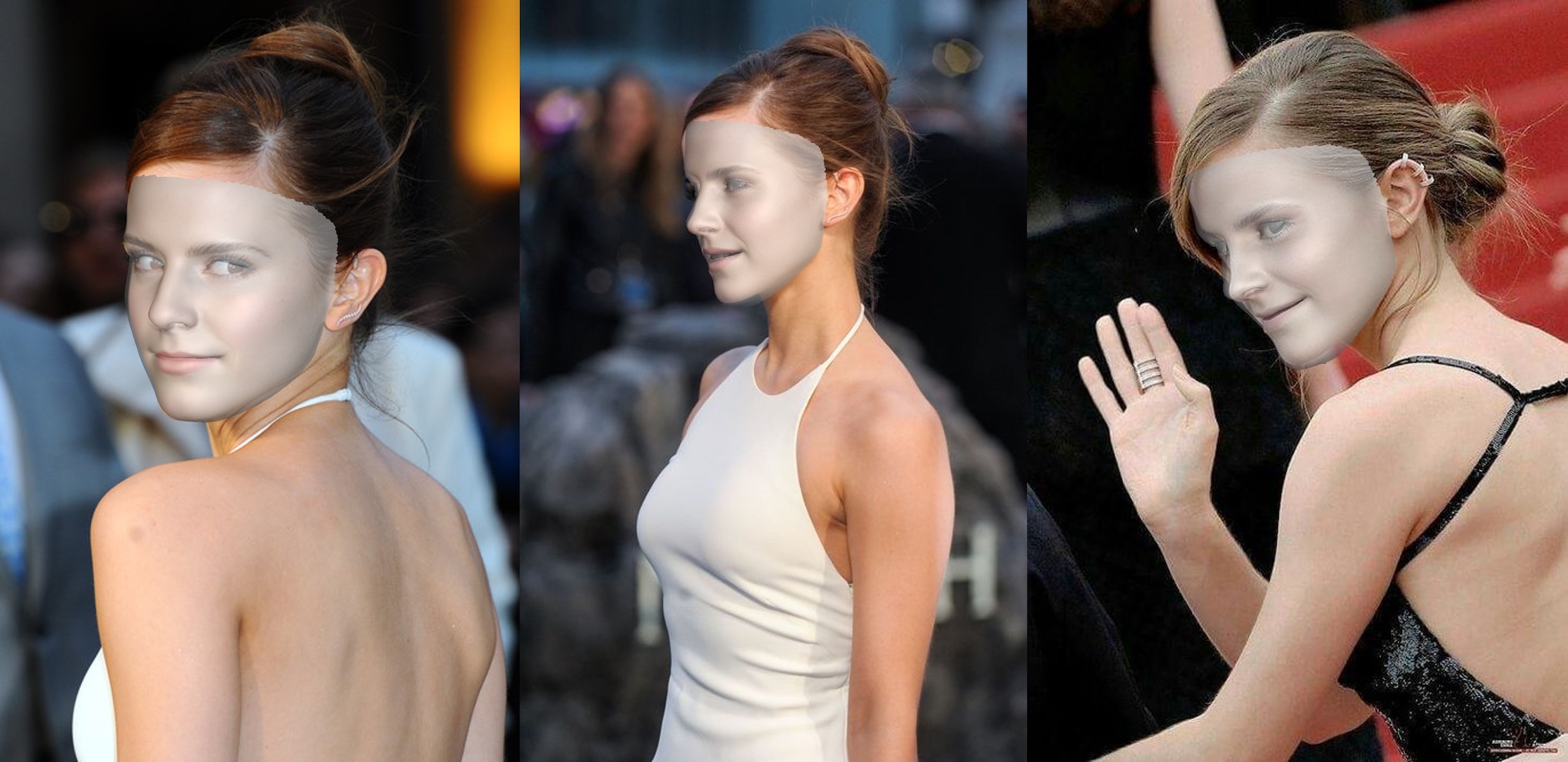
Un autre exemple:

Courir sur une vidéo donnera:

Plus de résultats ou de démos à voir: Hathaway.
| 2d clairsemé | 2d dense | 3D |
|---|---|---|
 |  |  |
| Profondeur | Pncc | Texture UV |
 |  |  |
| Pose | Sérialisation à .ply | Sérialisation à .obj |
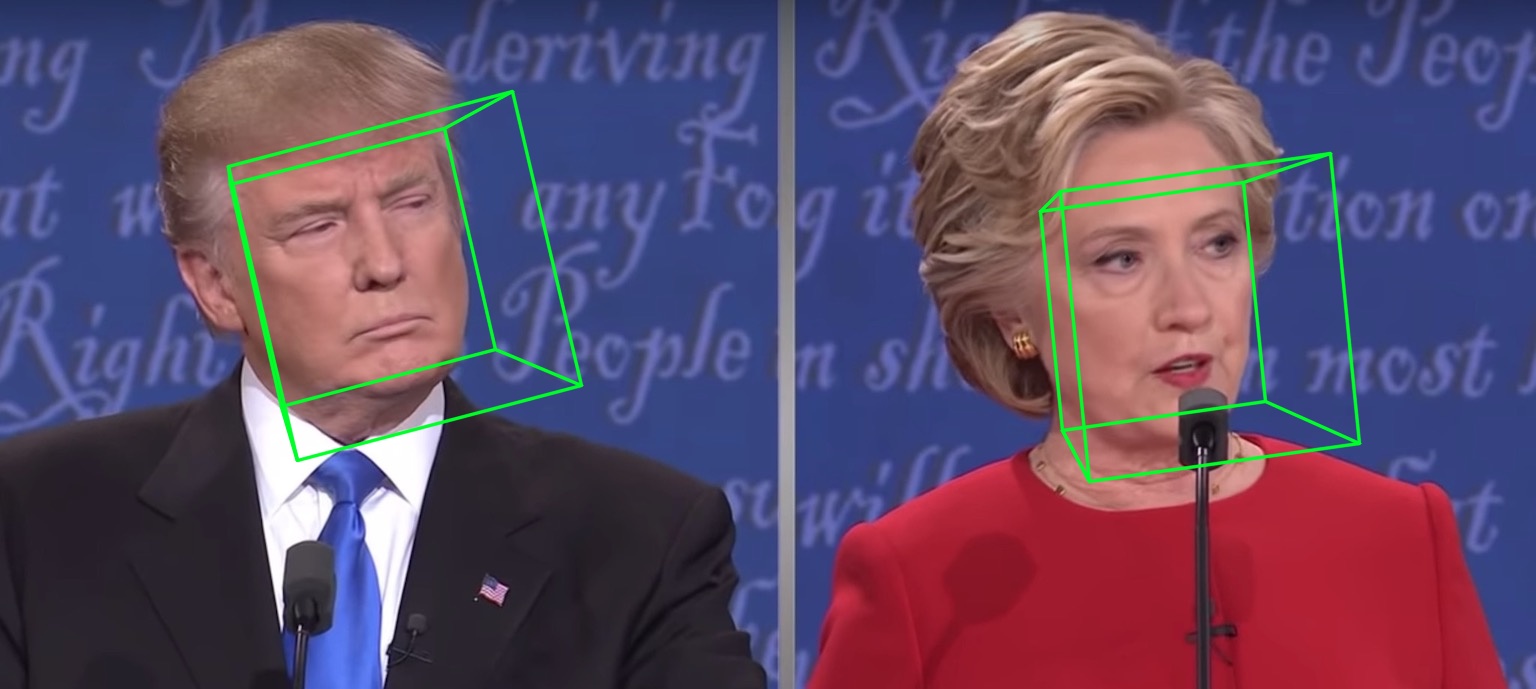 |  | 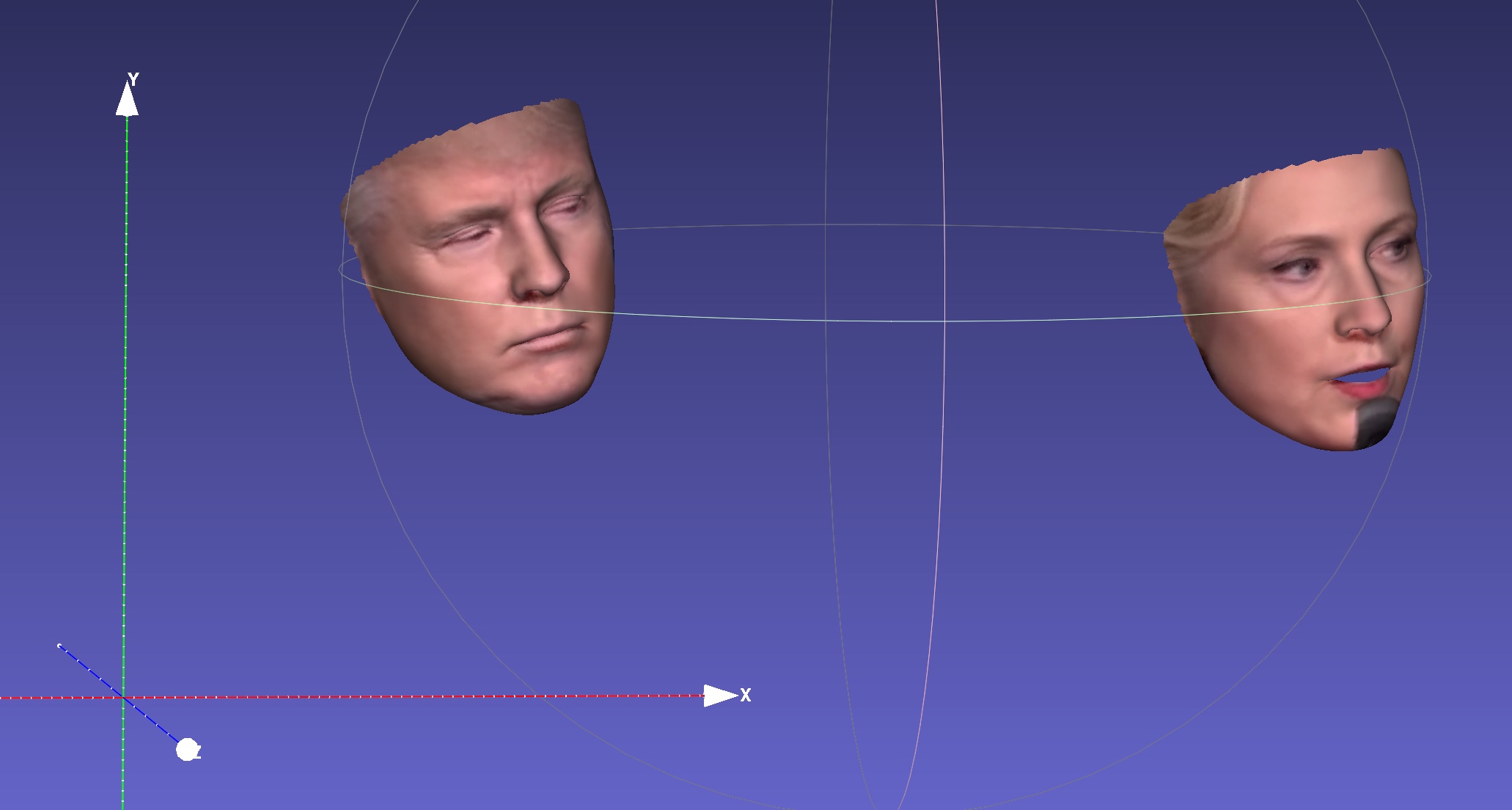 |
L'écran par défaut est MobileNet_V1 avec la taille de l'entrée 120x120 et le poids pré-formé par défaut est weights/mb1_120x120.pth , illustré dans les configts / MB1_120X120.yml. Ce repo fournit une autre configuration dans les configts / MB05_120x120.yml, avec le facteur élargi 0,5, étant plus petit et plus rapide. Vous pouvez spécifier l'option config by -c ou --config . Les modèles publiés sont affichés dans le tableau ci-dessous. Notez que le temps d'inférence sur CPU dans le papier est évalué à l'aide de TensorFlow.
| Modèle | Saisir | #Params | #Macs | Inférence (TF) |
|---|---|---|---|---|
| Mobilenet | 120x120 | 3,27 m | 183,5 m | ~ 6,2 ms |
| Mobilenet x0.5 | 120x120 | 0,85 m | 49,5 m | ~ 2,9 ms |
Étonnamment , la latence d'Onnxruntime est beaucoup plus petite. Le temps d'inférence sur CPU avec différents threads est illustré ci-dessous. Les résultats sont testés sur mon MBP (CPU i5-8259U @ 2,30 GHz sur MacBook Pro 13 pouces), avec la version 1.5.1 d'Onnxruntime. Le numéro de thread est défini par os.environ["OMP_NUM_THREADS"] , voir speed_cpu.py pour plus de détails.
| Modèle | Thread = 1 | Thread = 2 | Thread = 4 |
|---|---|---|---|
| Mobilenet | 4,4 ms | 2,25 ms | 1,35 ms |
| Mobilenet x0.5 | 1,37 ms | 0,7 ms | 0,5 ms |
L'option onnx réduit considérablement la latence globale du processeur , mais la détection du visage occupe toujours la majeure partie du temps de latence, par exemple, 15 ms pour une image 720p. La régression des paramètres 3DMM prend environ 1 ~ 2 ms pour une face, et la reconstruction dense (plus de 30 000 points, soit 38 365) est d'environ 1 ms pour une face. Les applications de suivi peuvent bénéficier de la vitesse de régression 3DMM rapide, car la détection n'est pas nécessaire pour chaque trame. La latence est testée à l'aide de mon MacBook Pro de 13 pouces (CPU i5-8259U @ 2,30 GHz).
Le par défaut OMP_NUM_THREADS est défini 4, vous pouvez le spécifier en définissant os.environ['OMP_NUM_THREADS'] = '$NUM' ou en insertant export OMP_NUM_THREADS=$NUM avant d'exécuter le script Python.
Quelles sont les données de formation?
Nous utilisons 300W-LP pour la formation. Vous pouvez vous référer à notre article pour plus de détails sur la formation. Étant donné que peu d'images sont des yeux fermés dans les données d'entraînement 300W-LP, les repères des yeux ne sont pas précis lors de la fermeture. La partie des yeux de la démonstration de webcam n'est pas non plus bonne.
Exécution sur Windows.
Vous pouvez vous référer à ce commentaire pour la construction de NMS sur Windows.
Si votre travail ou votre recherche profite de ce dépôt, veuillez citer deux dossiers ci-dessous :) et? Ce repo.
@inproceedings{guo2020towards,
title = {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author = {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
Jianzhu Guo (郭建珠) [page d'accueil, Google Scholar]: [email protected] ou [email protected] ou [email protected] (cet e-mail sera bientôt invalide).


