3DDFA_V2
v0.12 Release Notes
Von Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei und Stan Z. Li. Das Code -Repo gehört und wird von Jianzhu Guo geführt.

[Updates]
2021.7.10 : Führen Sie 3DDFA_V2 online auf Gradio aus.2021.1.15 : Leihen Sie sich die Implementierung einer Den-Head-Pose-Bewertung für das schnellere Mesh-Rendering aus (beschleunigen Sie etwa 3x, 15 ms-> 4 ms). Weitere Informationen finden Sie unter utils/render_ctypes.py.2020.10.7 : Fügen Sie die Latenzbewertung der python3 latency.py --onnx Pipeline in Latenz hinzu.2020.10.6 : Fügen Sie die Unterstützung für die Face -Erkennungslatenz hinzu. Fügen Sie einfach die Aktion --onnx -Aktion, um sie zu aktivieren, faceboxes_onnx.py hinzu.2020.10.2 : Fügen Sie die Unterstützung von Onnxruntime hinzu, um die 3DMM -Parameter -Inferenzlatenz erheblich zu reduzieren . Gehen Sie einfach die Aktion --onnx demo.py an, siehe tdddfa_onnx.py für Details.2020.9.20 : Fügen Sie Funktionen einschließlich Pose -Schätzung und Serialisierungen zu .PLY und .OBJ hinzu, siehe pose , ply , obj -Optionen in Demo.Py.2020.9.19 : Hinzufügen von PNCC (projizierter normalisierter Koordinatencode), UV -Texture -Mapping -Funktionen, siehe pncc , uv_tex -Optionen in Demo.Py. Diese Arbeit erweitert 3DDFA, mit dem Namen 3DDFA_V2 mit dem Titel Fast, Genau und stabiler 3D -dichtes Gesichtsausrichtung, das von ECCV 2020 akzeptiert wird. Das ergänzende Material ist hier. Das GIF oben zeigt eine Webcam -Demo des Tracking -Ergebniss im Szenario meines Labors. Dieses Repo ist die offizielle Implementierung von 3DDFA_V2.
Im Vergleich zu 3DDFA erzielt 3DDFA_V2 eine bessere Leistung und Stabilität. Außerdem enthält 3DDFA_V2 die Fast Face -Detektor -Gesichtsbehörden anstelle von DLIB. Ein einfaches 3D -Rendering von C ++ und Cython ist ebenfalls enthalten. Dieses Repo unterstützt die Onnxruntime, und die Latenz des Rückschritts von 3DMM -Parametern unter Verwendung des Standard -Backbone beträgt ca. 1,35 ms/Bild auf CPU mit einem einzelnen Bild als Eingabe. Wenn Sie an diesem Repo interessiert sind, probieren Sie es einfach in diesem Google Colab ! Willkommen für wertvolle Themen, PRs und Diskussionen?
Siehe Anforderungen.txt, getestet auf MacOS- und Linux -Plattformen. Die Windows -Benutzer können sich auf FQA beziehen, um Probleme zu erstellen. Beachten Sie, dass dieses Repo Python3 verwendet. Die wichtigsten Abhängigkeiten sind Pytorch, Numpy, OpenCV-Python und OnnxRuntime usw. Wenn Sie die Demos mit --onnx -Flag für Beschleunigung durchführen, müssen Sie möglicherweise zuerst libomp installieren, dh brew install libomp auf MacOS.
git clone https://github.com/cleardusk/3DDFA_V2.git
cd 3DDFA_V2sh ./build.sh # 1. running on still image, the options include: 2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj
python3 demo.py -f examples/inputs/emma.jpg --onnx # -o [2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj]
# 2. running on videos
python3 demo_video.py -f examples/inputs/videos/214.avi --onnx
# 3. running on videos smoothly by looking ahead by `n_next` frames
python3 demo_video_smooth.py -f examples/inputs/videos/214.avi --onnx
# 4. running on webcam
python3 demo_webcam_smooth.py --onnxDie Implementierung der Verfolgung erfolgt einfach durch Ausrichtung. Wenn der Kopf von> 90 ° oder die Bewegung zu schnell ist, kann die Ausrichtung möglicherweise fehlschlagen. Ein Schwellenwert wird verwendet, um den Tracking -Status neu zu überprüfen, ist jedoch instabil.
Sie können sich auf das schrittweise Tutorial für das Laufen auf dem Standbild beziehen.
Beispielsweise gibt es das Ergebnis unten, wenn python3 demo.py -f examples/inputs/emma.jpg -o 3d ausgeführt werden:
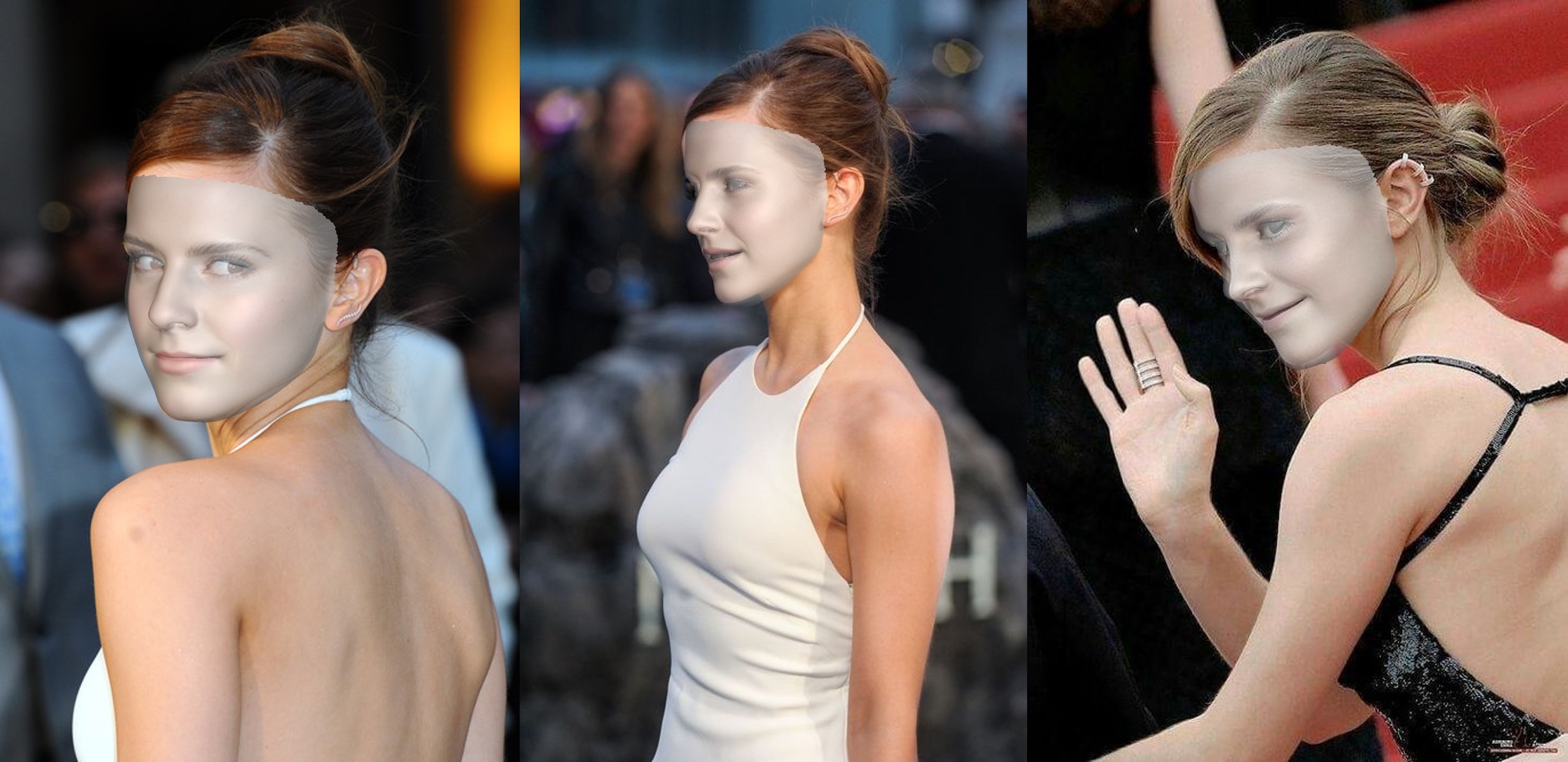
Ein weiteres Beispiel:

Wenn Sie auf einem Video laufen, erhalten Sie:

Weitere Ergebnisse oder Demos zu sehen: Hathaway.
| 2d spärlich | 2d dicht | 3d |
|---|---|---|
 |  |  |
| Tiefe | PNCC | UV -Textur |
 |  |  |
| Pose | Serialisierung zu .PLY | Serialisierung nach .obj |
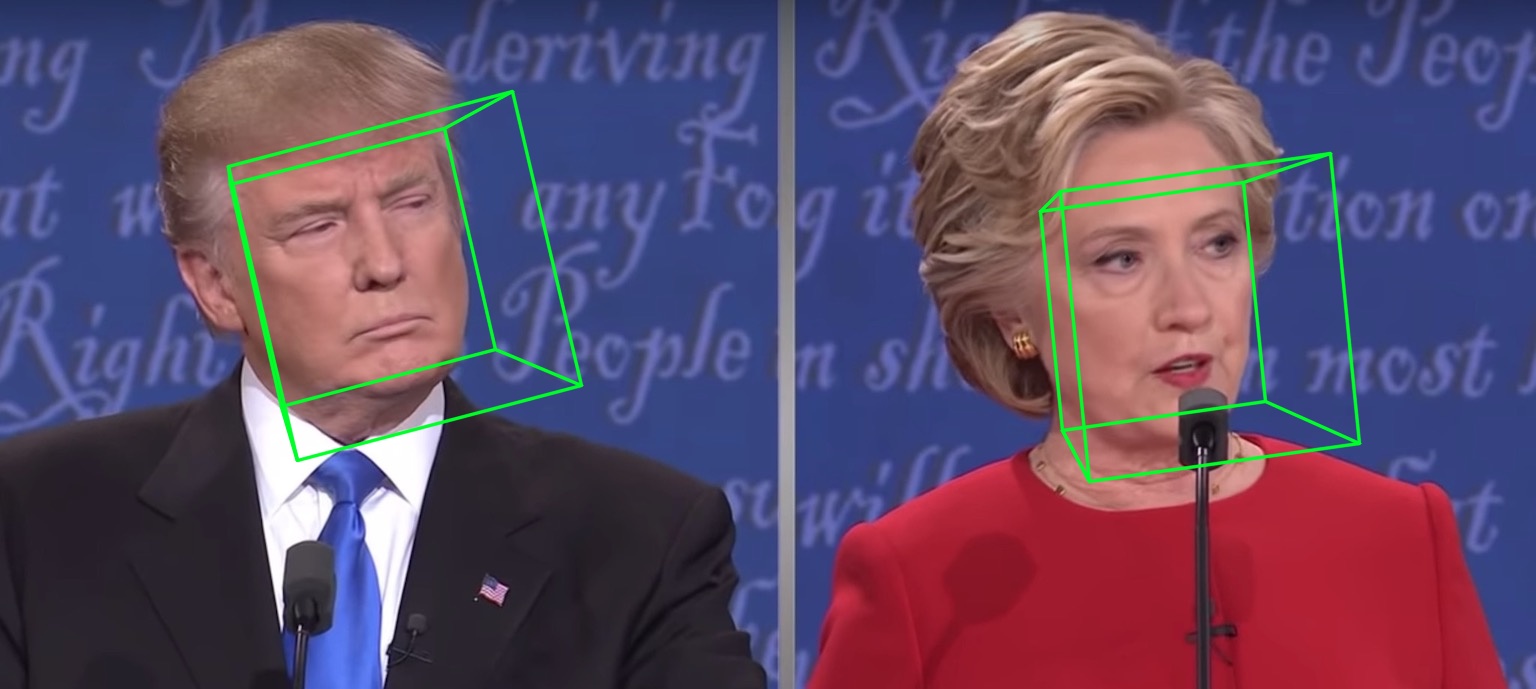 |  | 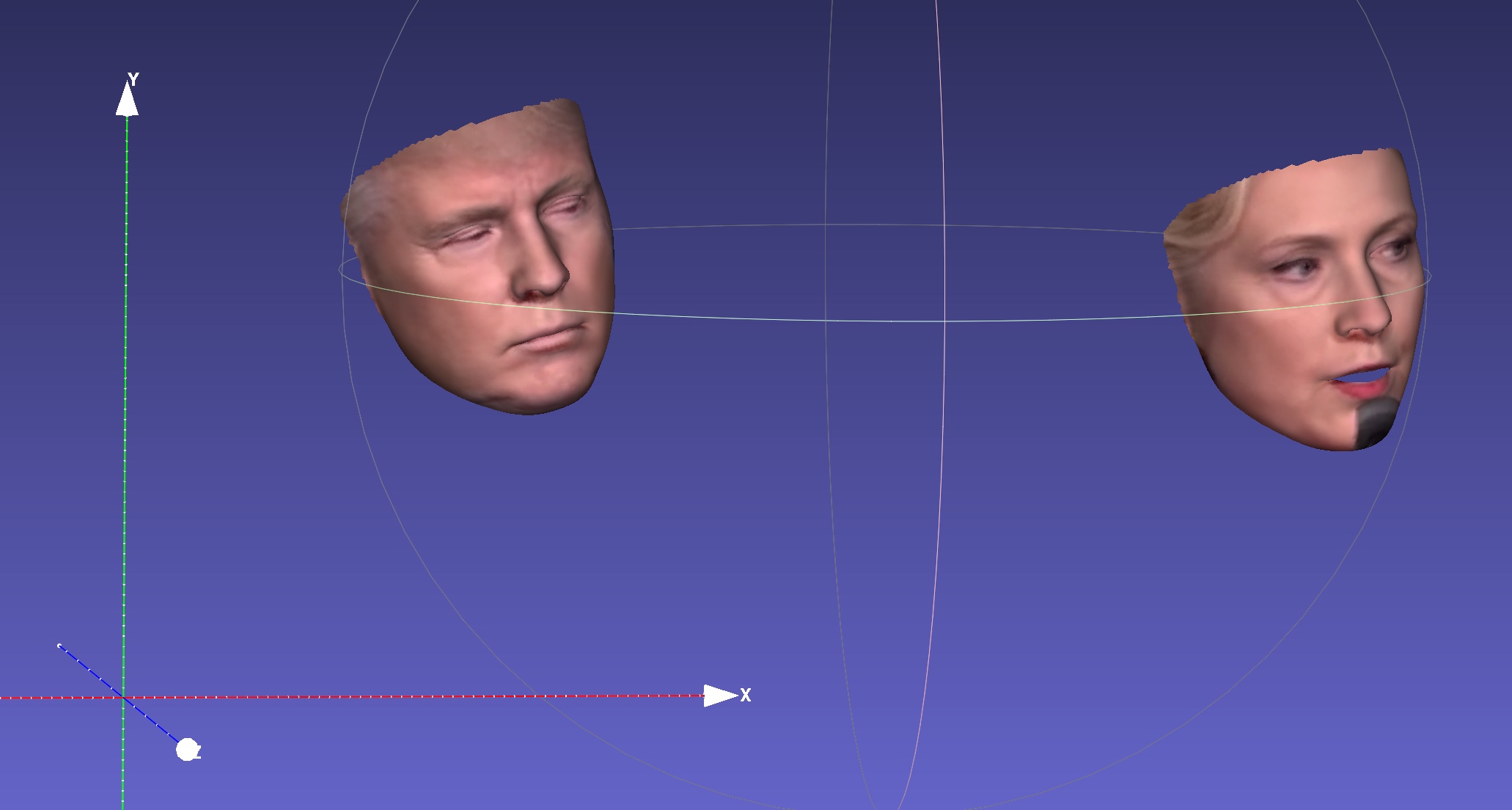 |
Das Standard-Backbone ist mobilenet_v1 mit Eingangsgröße 120x120, und das Standardgewicht ist weights/mb1_120x120.pth , gezeigt in configs/mb1_120x120.yml. Dieses Repo bietet eine weitere Konfiguration in configs/mb05_120x120.yml, wobei der Widden -Faktor 0,5 kleiner und schneller ist. Sie können die Konfiguration nach -c oder --config -Option angeben. Die freigegebenen Modelle sind in der folgenden Tabelle angezeigt. Beachten Sie, dass die Inferenzzeit auf der CPU im Papier unter Verwendung von Tensorflow bewertet wird.
| Modell | Eingang | #Params | #MACS | Inferenz (TF) |
|---|---|---|---|---|
| Mobilenet | 120x120 | 3,27 m | 183,5 m | ~ 6,2 ms |
| Mobilenet X0.5 | 120x120 | 0,85 m | 49,5 m | ~ 2,9 ms |
Überraschenderweise ist die Latenz von Onnxruntime viel kleiner. Die Inferenzzeit auf der CPU mit unterschiedlichen Threads ist unten dargestellt. Die Ergebnisse werden auf meinem MBP (i5-8259U CPU @ 2.30 GHz auf 13-Zoll-MacBook Pro) mit der 1.5.1 Version von OnnxRuntime getestet. Die Threadnummer wird von os.environ["OMP_NUM_THREADS"] festgelegt, siehe Speed_CPU.py für weitere Details.
| Modell | Thread = 1 | Thread = 2 | Thread = 4 |
|---|---|---|---|
| Mobilenet | 4.4 ms | 2,25 ms | 1,35 ms |
| Mobilenet X0.5 | 1,37 ms | 0,7 ms | 0,5 ms |
Die onnx -Option reduziert die gesamte CPU -Latenz erheblich, aber die Gesichtserkennung nimmt immer noch den größten Teil der Latenzzeit, z. B. 15 ms für ein 720p -Bild. Die Regression von 3DMM -Parametern dauert ungefähr 1 ~ 2 ms für ein Gesicht, und die dichte Rekonstruktion (mehr als 30.000 Punkte, dh 38.365) beträgt etwa 1 ms für ein Gesicht. Die Verfolgung von Anträgen kann von der schnellen 3DMM -Regressionsgeschwindigkeit profitieren, da für jeden Frame nicht die Erkennung erforderlich ist. Die Latenz wird mit meinem 13-Zoll-MacBook Pro (i5-8259U CPU @ 2.30 GHz) getestet.
export OMP_NUM_THREADS=$NUM Standard OMP_NUM_THREADS ist festgelegt os.environ['OMP_NUM_THREADS'] = '$NUM'
Was sind die Trainingsdaten?
Wir verwenden 300 W-LP für das Training. Weitere Informationen zum Training finden Sie in unserem Artikel. Da in den Trainingsdaten nur wenige Bilder geschlossen sind, sind die Sehenswürdigkeiten der Augen beim Schließen nicht genau. Der Teil der Webcam -Demo ist auch nicht gut.
Ausführen unter Windows.
Sie können auf diesen Kommentar zum Erstellen von NMS unter Windows verweisen.
Wenn Ihre Arbeit oder Forschung von diesem Repo profitiert, zitieren Sie bitte zwei Lätzchen unten :) und? Dieses Repo.
@inproceedings{guo2020towards,
title = {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author = {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
Jianzhu Guo (郭建珠) [Homepage, Google Scholar]: [email protected] oder [email protected] oder [email protected] (diese E -Mail wird in Kürze ungültig sein).


