3DDFA_V2
v0.12 Release Notes
Oleh Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei dan Stan Z. Li. Repo kode dimiliki dan dikelola oleh Jianzhu Guo .

[Pembaruan]
2021.7.10 : Jalankan 3DDFA_V2 secara online di gradio.2021.1.15 : Pinjam implementasi estimasi pose-head-head untuk rendering mesh yang lebih cepat (speedup sekitar 3x, 15ms-> 4ms), lihat utils/render_ctypes.py untuk detailnya.2020.10.7 python3 latency.py --onnx2020.10.6 --onnx2020.10.2 . --onnx demo.py2020.9.20 : Tambahkan fitur termasuk estimasi pose dan serialisasi ke .ply dan .obj, lihat pose , ply , opsi obj di demo.py.2020.9.19 : Tambahkan PNCC (proyeksi kode koordinat yang dinormalisasi), fitur pemetaan tekstur UV, lihat pncc , opsi uv_tex di demo.py. Karya ini memperluas 3DDFA, bernama 3DDFA_V2 , berjudul menuju penyelarasan wajah 3D padat 3D yang cepat, akurat dan stabil, diterima oleh ECCV 2020. Bahan tambahan ada di sini. GIF di atas menunjukkan demo webcam dari hasil pelacakan, dalam skenario lab saya. Repo ini adalah implementasi resmi 3DDFA_V2.
Dibandingkan dengan 3DDFA, 3DDFA_V2 mencapai kinerja dan stabilitas yang lebih baik. Selain itu, 3DDFA_V2 menggabungkan facebox detektor wajah cepat alih -alih dlib. Render 3D sederhana yang ditulis oleh C ++ dan Cython juga disertakan. Repo ini mendukung onnxruntime, dan latensi regresi parameter 3DMM menggunakan tulang punggung default adalah sekitar 1,35ms/gambar pada CPU dengan satu gambar sebagai input. Jika Anda tertarik dengan repo ini, coba saja di Google Colab ini! Selamat datang untuk masalah, PRS, dan diskusi yang berharga?
Lihat persyaratan.txt, diuji pada platform macOS dan Linux. Pengguna Windows dapat merujuk ke FQA untuk membangun masalah. Perhatikan bahwa repo ini menggunakan Python3. Ketergantungan utama adalah Pytorch, Numpy, OpenCV-Python dan Onnxruntime, dll. Jika Anda menjalankan demo dengan --onnx FLAG untuk melakukan akselerasi, Anda mungkin perlu menginstal libomp terlebih dahulu, yaitu, brew install libomp pada macOS.
git clone https://github.com/cleardusk/3DDFA_V2.git
cd 3DDFA_V2sh ./build.sh # 1. running on still image, the options include: 2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj
python3 demo.py -f examples/inputs/emma.jpg --onnx # -o [2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj]
# 2. running on videos
python3 demo_video.py -f examples/inputs/videos/214.avi --onnx
# 3. running on videos smoothly by looking ahead by `n_next` frames
python3 demo_video_smooth.py -f examples/inputs/videos/214.avi --onnx
# 4. running on webcam
python3 demo_webcam_smooth.py --onnxImplementasi pelacakan hanya dengan penyelarasan. Jika kepala berpose> 90 ° atau gerakannya terlalu cepat, penyelarasan mungkin gagal. Ambang batas digunakan untuk dengan tegas memeriksa keadaan pelacakan, tetapi tidak stabil.
Anda dapat merujuk ke demo.ipynb atau Google Colab untuk tutorial langkah demi langkah berjalan pada gambar diam.
Misalnya, menjalankan python3 demo.py -f examples/inputs/emma.jpg -o 3d akan memberikan hasil di bawah ini:
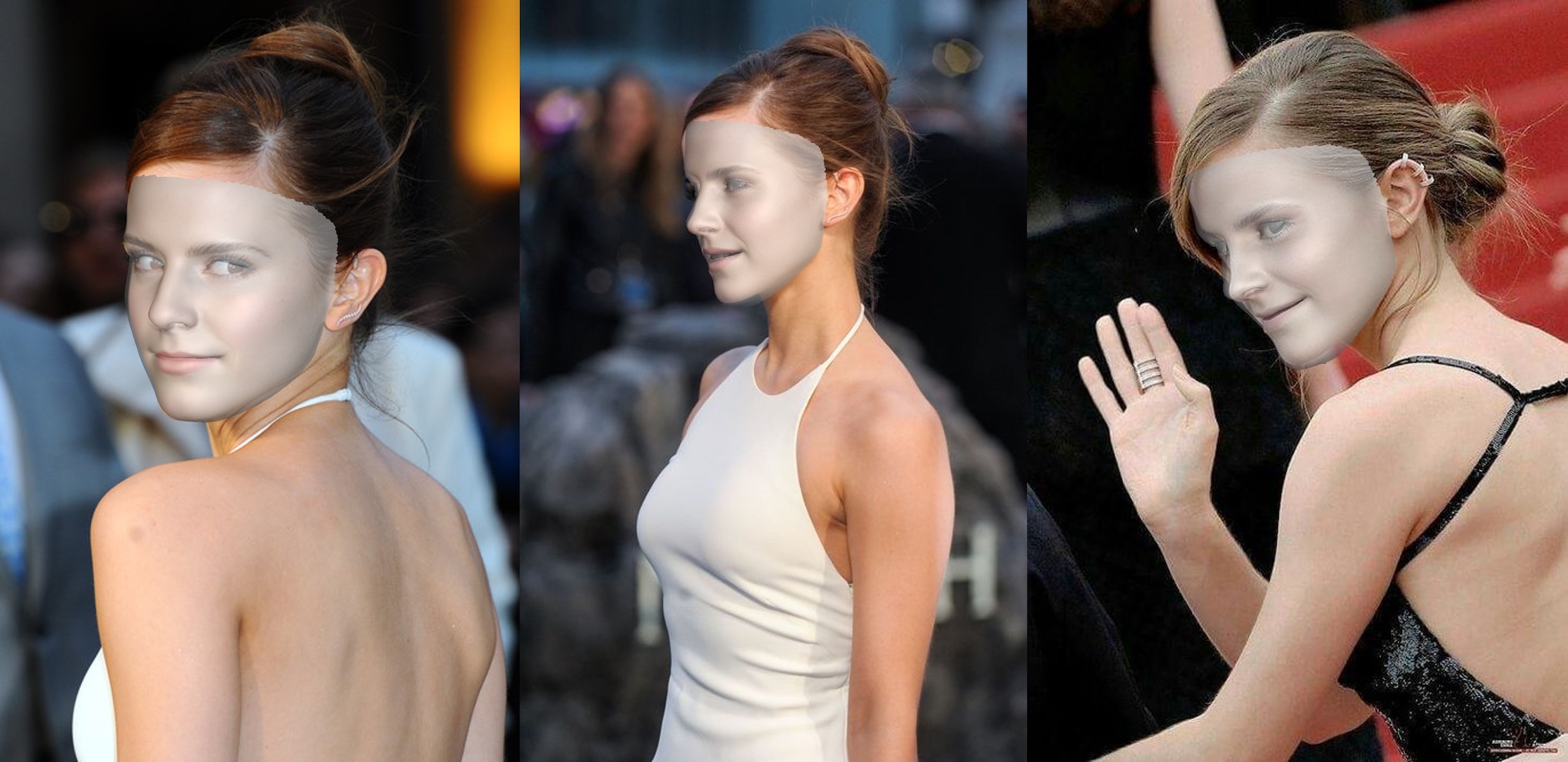
Contoh lain:

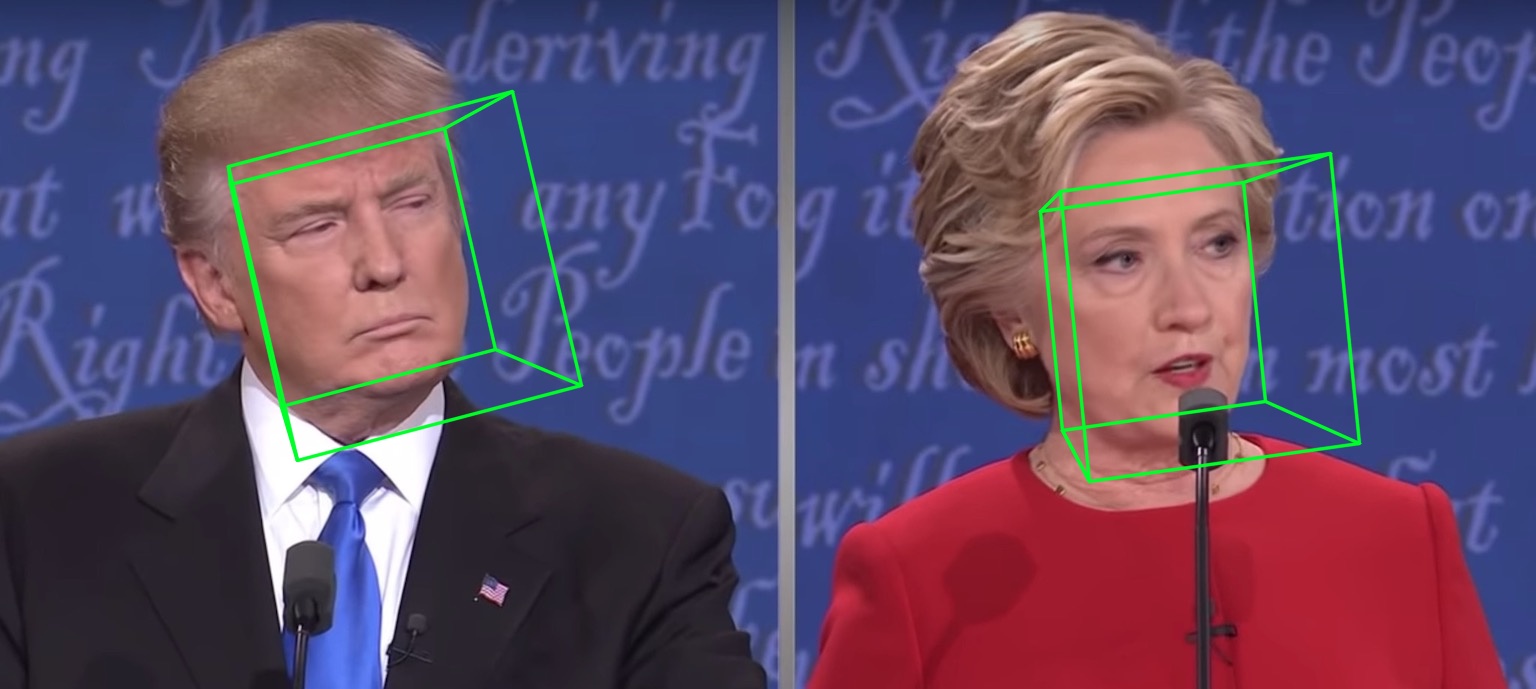
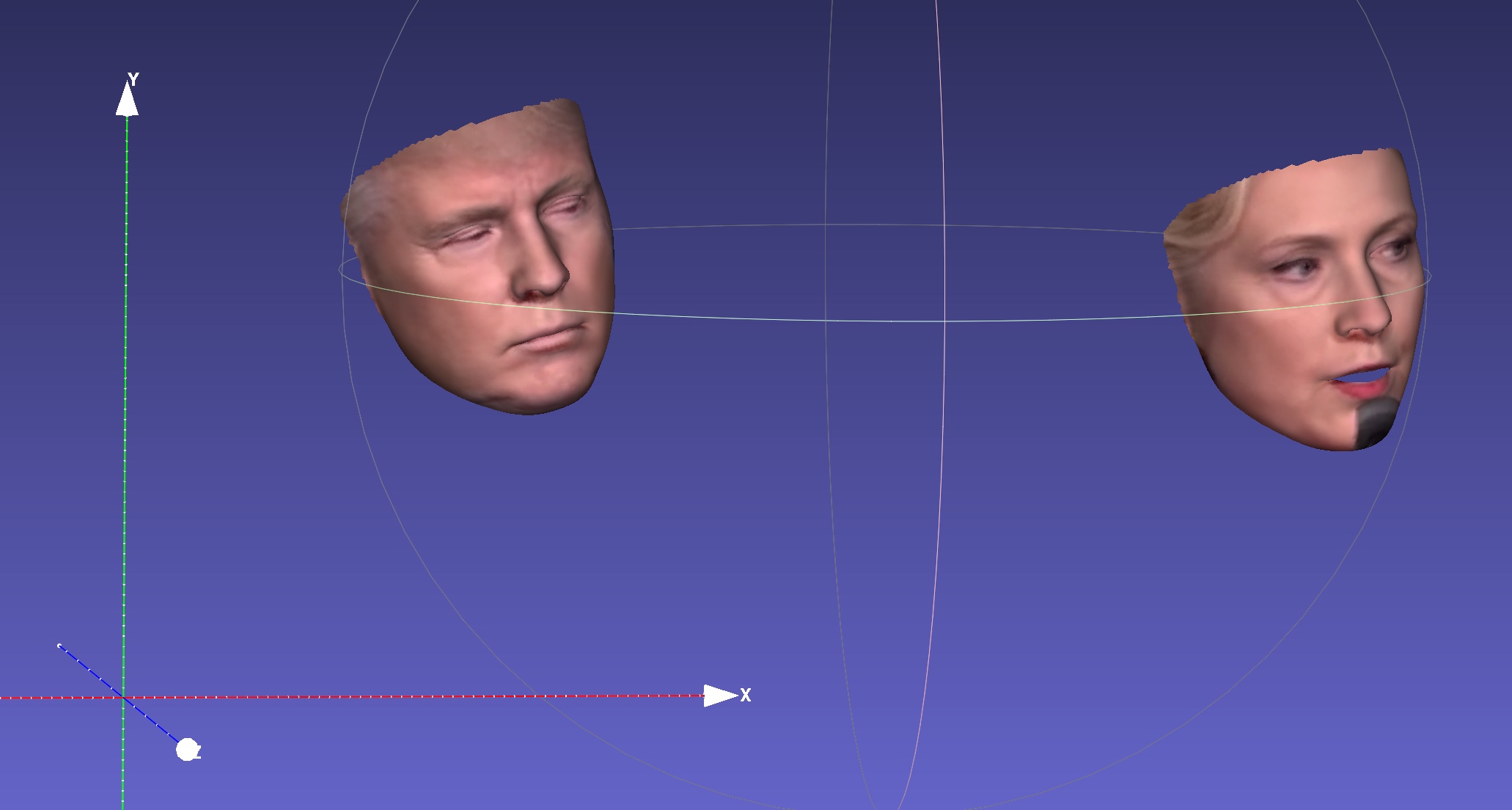
Berjalan di video akan memberi:

Lebih banyak hasil atau demo untuk dilihat: Hathaway.
| 2d jarang | 2d padat | 3d |
|---|---|---|
 |  |  |
| Kedalaman | PNCC | Tekstur UV |
 |  |  |
| Pose | Serialisasi ke .ply | Serialisasi ke .OBJ |
 |  |  |
Backbone default adalah MobileNet_V1 dengan ukuran input 120x120 dan bobot pra-terlatih default adalah weights/mb1_120x120.pth , ditunjukkan dalam configs/mb1_120x120.yml. Repo ini menyediakan konfigurasi lain di konfigurasi/MB05_120x120.yml, dengan faktor lebar 0,5, menjadi lebih kecil dan lebih cepat. Anda dapat menentukan opsi konfigurasi dengan -c atau --config . Model yang dilepaskan ditampilkan pada tabel di bawah ini. Perhatikan bahwa waktu inferensi pada CPU dalam kertas dievaluasi menggunakan TensorFlow.
| Model | Masukan | #Params | #Macs | Inferensi (TF) |
|---|---|---|---|---|
| Mobilenet | 120x120 | 3.27m | 183.5m | ~ 6.2ms |
| MobileNet x0.5 | 120x120 | 0.85m | 49.5m | ~ 2.9ms |
Anehnya , latensi onnxruntime jauh lebih kecil. Waktu inferensi pada CPU dengan utas yang berbeda ditunjukkan di bawah ini. Hasilnya diuji pada MBP saya (I5-8259U CPU @ 2.30GHz pada MacBook Pro 13-inci), dengan versi 1.5.1 Onnxruntime. Nomor utas diatur oleh os.environ["OMP_NUM_THREADS"] , lihat speed_cpu.py untuk detail lebih lanjut.
| Model | Thread = 1 | Thread = 2 | Thread = 4 |
|---|---|---|---|
| Mobilenet | 4.4ms | 2,25ms | 1,35ms |
| MobileNet x0.5 | 1,37ms | 0.7ms | 0,5 ms |
Opsi onnx sangat mengurangi latensi CPU keseluruhan, tetapi deteksi wajah masih memakan sebagian besar waktu latensi, misalnya, 15ms untuk gambar 720p. Regresi parameter 3DMM membutuhkan waktu sekitar 1 ~ 2ms untuk satu wajah, dan rekonstruksi padat (lebih dari 30.000 poin, yaitu 38.365) adalah sekitar 1 ms untuk satu wajah. Aplikasi pelacakan dapat mengambil manfaat dari kecepatan regresi 3DMM cepat, karena deteksi tidak diperlukan untuk setiap bingkai. Latensi diuji menggunakan MacBook Pro 13 inci saya (I5-8259U CPU @ 2.30GHz).
OMP_NUM_THREADS default adalah set 4, Anda dapat menentukannya dengan mengatur os.environ['OMP_NUM_THREADS'] = '$NUM' atau memasukkan export OMP_NUM_THREADS=$NUM sebelum menjalankan skrip python.
Apa data pelatihannya?
Kami menggunakan 300W-LP untuk pelatihan. Anda dapat merujuk ke makalah kami untuk detail lebih lanjut tentang pelatihan. Karena beberapa gambar adalah mata tertutup dalam data pelatihan 300W-LP, landmark mata tidak akurat saat ditutup. Bagian mata dari demo webcam juga tidak baik.
Berjalan di windows.
Anda dapat merujuk komentar ini untuk membangun NMS di Windows.
Jika pekerjaan atau penelitian Anda mendapat manfaat dari repo ini, silakan kutip dua oto di bawah ini :) dan? repo ini.
@inproceedings{guo2020towards,
title = {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author = {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
Jianzhu Guo (郭建珠) [Beranda, Google Cendekia]: [email protected] atau [email protected] atau [email protected] (email ini akan segera tidak valid).


