3DDFA_V2
v0.12 Release Notes
Jianzhu Guo、Xiangyu Zhu、Yang Yang、Fan Yang、Zhen Lei、Stan Z. Li。コードリポジトリは、 Jianzhu Guoが所有および維持しています。

[更新]
2021.7.10 :グレードで3DDFA_V2をオンラインで実行します。2021.1.15 :詳細については、より高速なメッシュレンダリング(スピードアップ約3x、15ms-> 4ms)のために、密集したヘッドポーズ推定の実装を借りて、utils/render_ctypes.pyを参照してください。2020.10.7 :Latency.pyの完全なパイプラインのレイテンシ評価を追加し、 python3 latency.py --onnxで実行するだけで、詳細についてはLatency評価を参照してください。2020.10.6 :フェイスボックスのonnxruntimeサポートを追加して、フェイス検出レイテンシを減らし、 --onnxアクションを追加してアクティブ化するだけで、詳細についてはfaceboxes_onnx.pyを参照してください。2020.10.2 : onnxruntimeサポートを追加して、3DMMパラメーターの推論レイテンシを大幅に削減します。詳細については、 demo.pyを実行するときに--onnxアクションを追加します。2020.9.20 :ポーズの推定とシリアル化などの機能を.ply and .objに追加し、demo.pyのpose 、 ply 、 objオプションを参照してください。2020.9.19 :PNCC(投影された正規化された座標コード)、UVテクスチャマッピング機能、demo.pyのpncc 、 uv_texオプションを参照してください。 この作業は、 3DDFA_V2という名前の3DDFAを拡張し、ECCV 2020に受け入れられている高速で正確で安定した3D密度の高い面アライメントにタイトルを付けています。補足資料はこちらです。上記のGIFは、ラボのシナリオで、追跡結果のウェブカメラデモを示しています。このレポは、3DDFA_V2の公式実装です。
3DDFAと比較して、3DDFA_V2はパフォーマンスと安定性が向上します。さらに、3DDFA_V2には、DLIBの代わりに高速フェイス検出器フェイスボックスが組み込まれています。 C ++とCythonによって書かれた単純な3Dレンダリングも含まれています。このレポは、onnxruntimeをサポートし、デフォルトのバックボーンを使用して3DMMパラメーターを回帰する遅延は、入力として単一の画像を使用してCPU上の約1.35ms/画像です。このリポジトリに興味がある場合は、このGoogle Colabで試してみてください!貴重な問題、PRS、ディスカッションへようこそ?
macOSおよびLinuxプラットフォームでテストされたrequincement.txtを参照してください。 Windowsユーザーは、構築の問題についてFQAを参照する場合があります。このレポはPython3を使用していることに注意してください。主要な依存関係は、Pytorch、Numpy、Opencv-Python、onnxruntimeなどです。 --onnxフラグを使用して加速を行うには、 libompを最初にbrew install libomp必要がある場合があります。
git clone https://github.com/cleardusk/3DDFA_V2.git
cd 3DDFA_V2sh ./build.sh # 1. running on still image, the options include: 2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj
python3 demo.py -f examples/inputs/emma.jpg --onnx # -o [2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj]
# 2. running on videos
python3 demo_video.py -f examples/inputs/videos/214.avi --onnx
# 3. running on videos smoothly by looking ahead by `n_next` frames
python3 demo_video_smooth.py -f examples/inputs/videos/214.avi --onnx
# 4. running on webcam
python3 demo_webcam_smooth.py --onnx追跡の実装は、単にアライメントによるものです。ヘッドが90°を超えるか、動きが速すぎる場合、アライメントが失敗する可能性があります。しきい値は、追跡状態をトリックチェックするために使用されますが、不安定です。
Still Imageで実行されるステップバイステップのチュートリアルについては、demo.ipynbまたはGoogle Colabを参照できます。
たとえば、 python3 demo.py -f examples/inputs/emma.jpg -o 3dを実行すると、以下の結果が得られます。
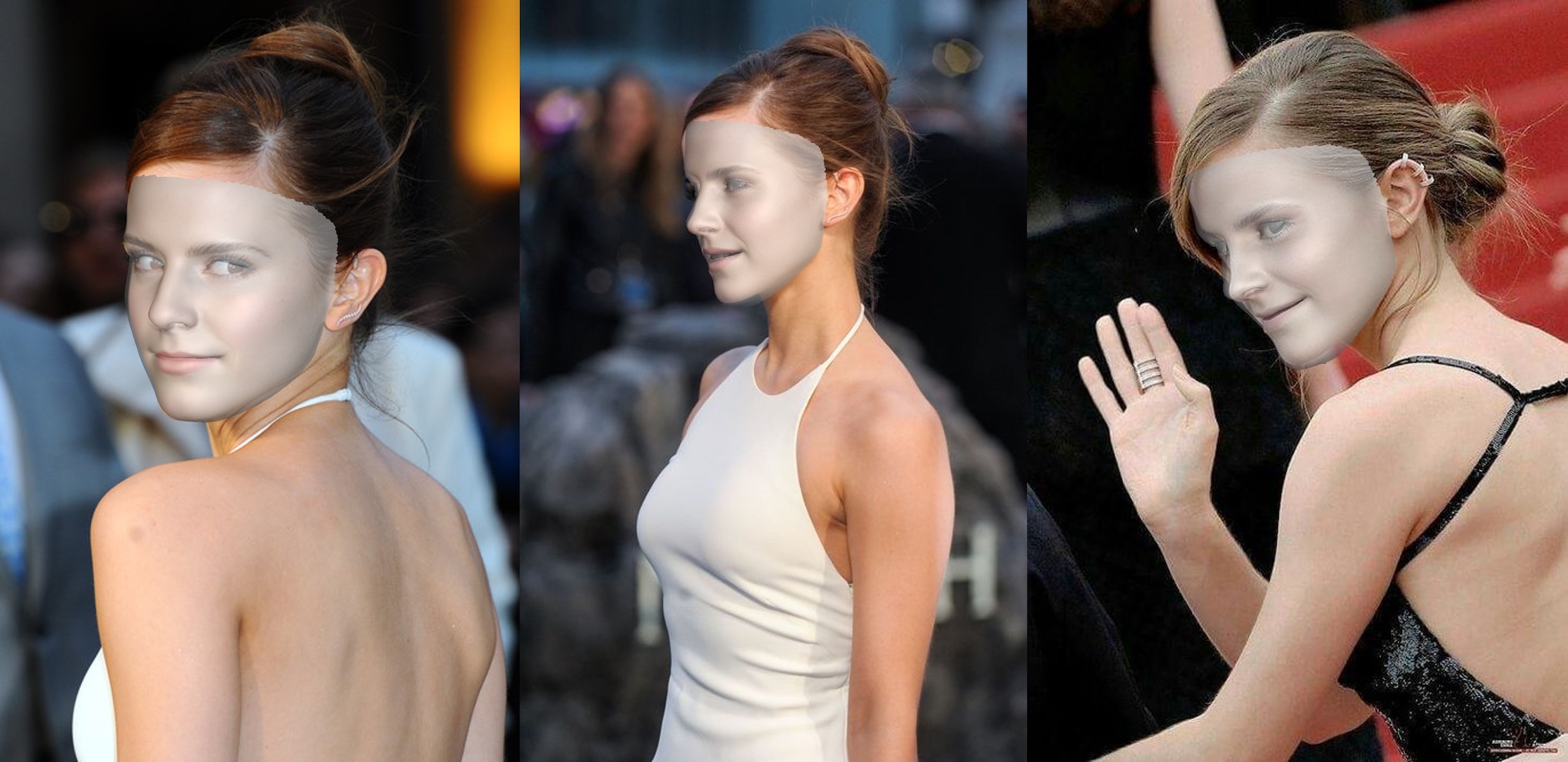
別の例:

ビデオで実行すると:

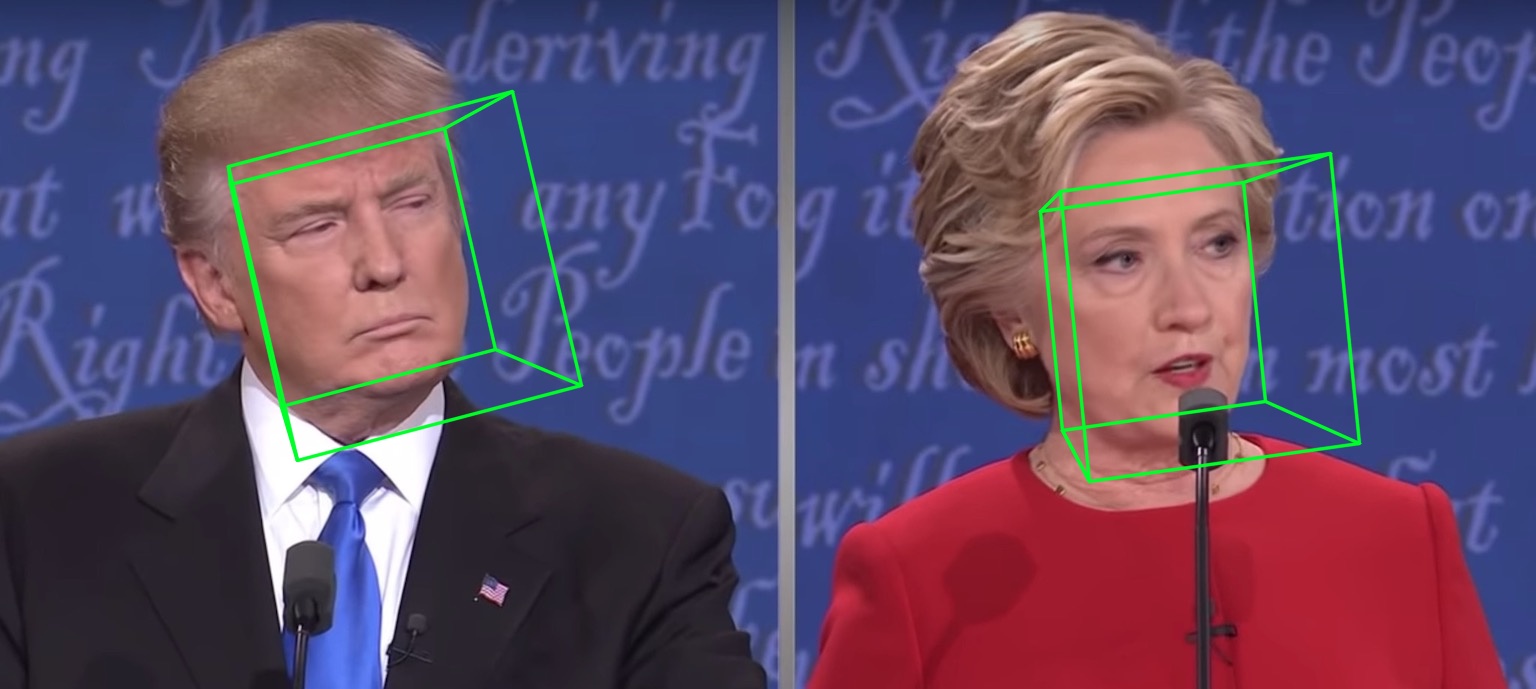
より多くの結果またはデモを見る:ハサウェイ。
| 2Dスパース | 2D密度 | 3D |
|---|---|---|
 |  |  |
| 深さ | PNCC | UVテクスチャ |
 |  |  |
| ポーズ | .plyへのシリアル化 | .objへのシリアル化 |
 |  | 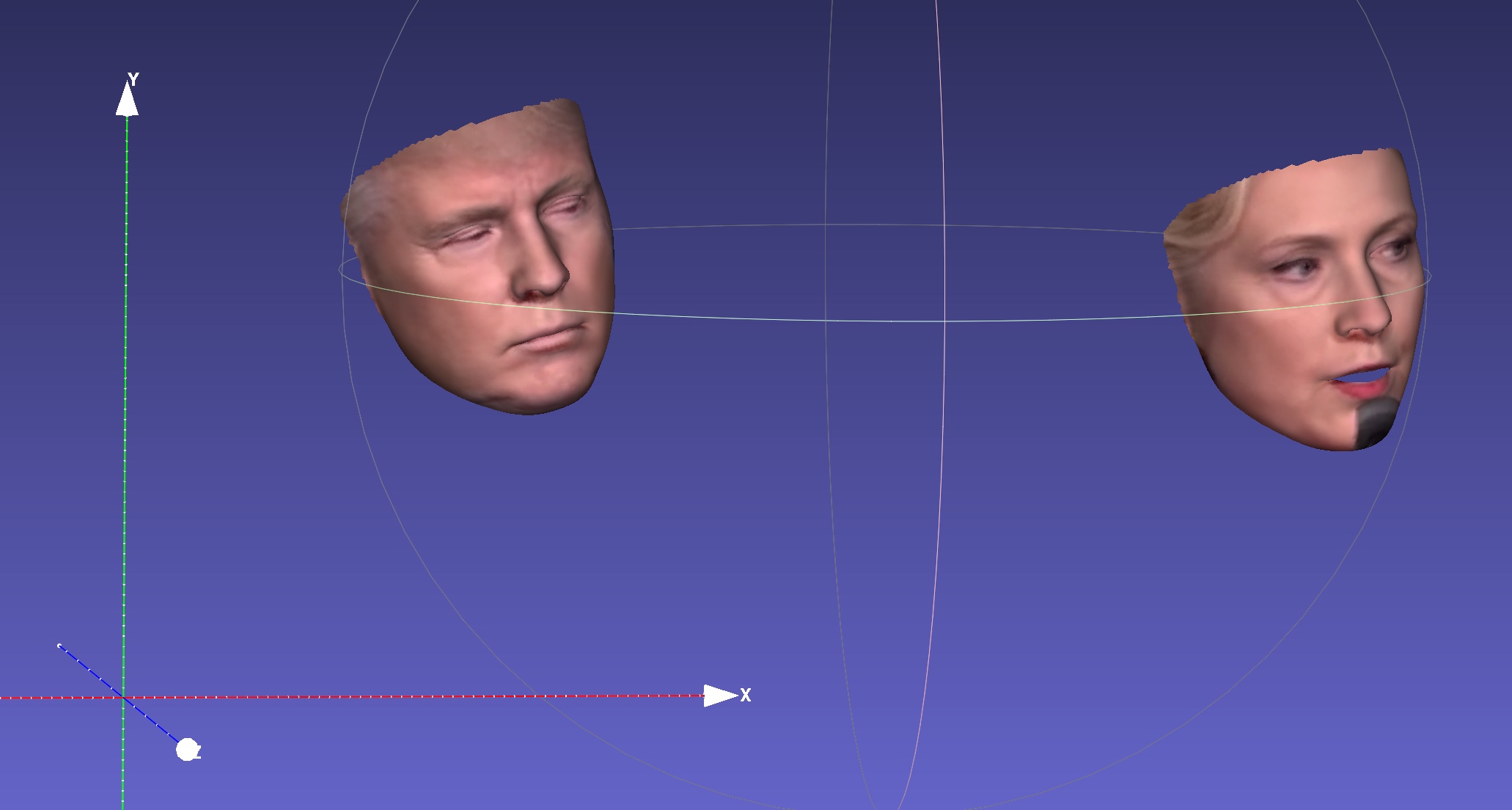 |
デフォルトのバックボーンは、入力サイズ120x120のMobileNet_v1であり、デフォルトの事前訓練の重量はweights/mb1_120x120.pthです。このレポは、configs/mb05_120x120.ymlで別の構成を提供し、拡張係数0.5が小さく、より速いです。 -cまたは-config by --configオプションを指定できます。リリースされたモデルは、以下の表に示されています。論文のCPUの推論時間はTensorflowを使用して評価されることに注意してください。
| モデル | 入力 | #params | #macs | 推論(TF) |
|---|---|---|---|---|
| Mobilenet | 120x120 | 3.27m | 183.5m | 〜6.2ms |
| Mobilenet x0.5 | 120x120 | 0.85m | 49.5m | 約2.9ms |
驚くべきことに、onnxruntimeの遅延ははるかに小さくなっています。異なるスレッドを使用したCPUの推論時間を以下に示します。結果は、OnnxRuntimeの1.5.1バージョンで、MBP(13インチMacBook ProでI5-8259U CPU @ 2.30GHz)でテストされています。スレッド番号はos.environ["OMP_NUM_THREADS"]によって設定されています。詳細については、speed_cpu.pyを参照してください。
| モデル | スレッド= 1 | スレッド= 2 | スレッド= 4 |
|---|---|---|---|
| Mobilenet | 4.4ms | 2.25ms | 1.35ms |
| Mobilenet x0.5 | 1.37ms | 0.7ms | 0.5ms |
onnxオプションはCPUの全体的な遅延を大幅に削減しますが、顔の検出は、720p画像の場合、たとえば15msなどのレイテンシ時間のほとんどを引き起こします。 3DMMパラメーター回帰は、1つの面で約1〜2msの時間がかかり、密な再建(30,000ポイント以上、つまり38,365)は1つの面で約1msです。追跡アプリケーションは、すべてのフレームで検出が必要ないため、高速3DMM回帰速度の恩恵を受ける場合があります。レイテンシは、13インチのMacBook Pro(I5-8259U CPU @ 2.30GHz)を使用してテストされています。
デフォルトのOMP_NUM_THREADSは設定されていますos.environ['OMP_NUM_THREADS'] = '$NUM'を設定するか、Pythonスクリプトを実行する前にexport OMP_NUM_THREADS=$NUMを挿入するか、指定できます。
トレーニングデータは何ですか?
トレーニングには300W-LPを使用しています。トレーニングの詳細については、私たちの論文を参照できます。トレーニングデータ300W-LPの閉じた目はほとんどないため、閉じるときは目のランドマークは正確ではありません。ウェブカメラのデモの目の一部も良くありません。
Windowsで実行されます。
WindowsにNMを構築するためのこのコメントを参照できます。
あなたの仕事や研究がこのリポジトリから利益を得るなら、以下の2つのビブを引用してください:)そして?このレポ。
@inproceedings{guo2020towards,
title = {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author = {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
jianzhu guo(郭建珠) [Homepage、Google Scholar]: [email protected]または[email protected]または[email protected] (このメールはすぐに無効になります)。


