3DDFA_V2
v0.12 Release Notes
بقلم Jianzhu Guo و Xiangyu Zhu و Yang Yang و Fan Yang و Zhen Lei و Stan Z. Li. رمز ريبو مملوك وصيانته من قبل Jianzhu Guo .

[تحديثات]
2021.7.10 : تشغيل 3DDFA_V2 عبر الإنترنت على Gradio.2021.1.15 .2020.10.7 : أضف تقييم الكمون لخط الأنابيب الكامل في الكمون python3 latency.py --onnx2020.10.6 : أضف دعم OnNxRuntime لـ Faceboxes لتقليل زمن انتقال الكشف عن الوجه ، فقط قم بإلحاق الإجراء --onnx لتنشيطه ، راجع Faceboxes_onnx.py للحصول على التفاصيل.2020.10.2 : أضف دعم onnxruntime لتقليل زمن استناد الاستدلال 3DMM بشكل كبير ، ما عليك سوى إلحاق الإجراء --onnx عند تشغيل demo.py ، راجع tddfa_onnx.py للحصول على التفاصيل.2020.9.20 : أضف ميزات بما في ذلك التقديرات الوضعية والتسلسل إلى .ply و .oBJ ، انظر pose ، ply ، obj Options in Demo.py.2020.9.19 : أضف PNCC (رمز الإحداثيات المعتادة المتوقعة) ، وميزات رسم الخرائط للأشعة فوق البنفسجية ، راجع خيارات pncc ، uv_tex في demo.py. يمتد هذا العمل 3DDFA ، المسمى 3DDFA_V2 ، الذي يحمل عنوان FAST و DICATION و DECTION 3D Cense Face محاذاة ، مقبولة بواسطة ECCV 2020. المادة التكميلية موجودة هنا. يعرض GIF أعلاه عرضًا تجريبيًا على كاميرا الويب لنتيجة التتبع ، في سيناريو مختبري. هذا الريبو هو التنفيذ الرسمي لـ 3DDFA_V2.
بالمقارنة مع 3DDFA ، يحقق 3DDFA_V2 أداءً أفضل واستقرارًا. إلى جانب ذلك ، يتضمن 3DDFA_V2 صناديق الوجه السريع للوجه بدلاً من DLIB. يتم تضمين عرض ثلاثي الأبعاد بسيط كتبه C ++ و Cython. يدعم هذا الريبو OnNxruntime ، ومواصلة تراجع معلمات 3DMM باستخدام العمود الفقري الافتراضي حوالي 1.35 مللي ثانية/صورة على وحدة المعالجة المركزية مع صورة واحدة كمدخل. إذا كنت مهتمًا بهذا الريبو ، فما عليك سوى جربه على Google Colab ! مرحبًا بك في القضايا القيمة ، PRS والمناقشات؟
راجع المتطلبات. txt ، تم اختباره على منصات MacOS و Linux. قد يشير مستخدمو Windows إلى FQA لبناء المشكلات. لاحظ أن هذا الريبو يستخدم Python3. التبعيات الرئيسية هي Pytorch و Numpy و Opencv-Python و Onnxruntime ، وما إلى ذلك. إذا قمت بتشغيل العروض التوضيحية مع --onnx علامة التوصيل للقيام بالتسارع ، فقد تحتاج إلى تثبيت libomp أولاً ، أي ، brew install libomp على macos.
git clone https://github.com/cleardusk/3DDFA_V2.git
cd 3DDFA_V2sh ./build.sh # 1. running on still image, the options include: 2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj
python3 demo.py -f examples/inputs/emma.jpg --onnx # -o [2d_sparse, 2d_dense, 3d, depth, pncc, pose, uv_tex, ply, obj]
# 2. running on videos
python3 demo_video.py -f examples/inputs/videos/214.avi --onnx
# 3. running on videos smoothly by looking ahead by `n_next` frames
python3 demo_video_smooth.py -f examples/inputs/videos/214.avi --onnx
# 4. running on webcam
python3 demo_webcam_smooth.py --onnxتنفيذ التتبع هو ببساطة عن طريق المحاذاة. إذا كان الرأس يضع> 90 درجة أو الحركة سريعة جدًا ، فقد تفشل المحاذاة. يتم استخدام العتبة للتحقق من حالة التتبع بشكل صعب ، لكنها غير مستقرة.
يمكنك الرجوع إلى Demo.ipynb أو Google Colab للحصول على تعليمي خطوة بخطوة للتشغيل على الصورة الثابتة.
على سبيل المثال ، سيعطي تشغيل python3 demo.py -f examples/inputs/emma.jpg -o 3d النتيجة أدناه:
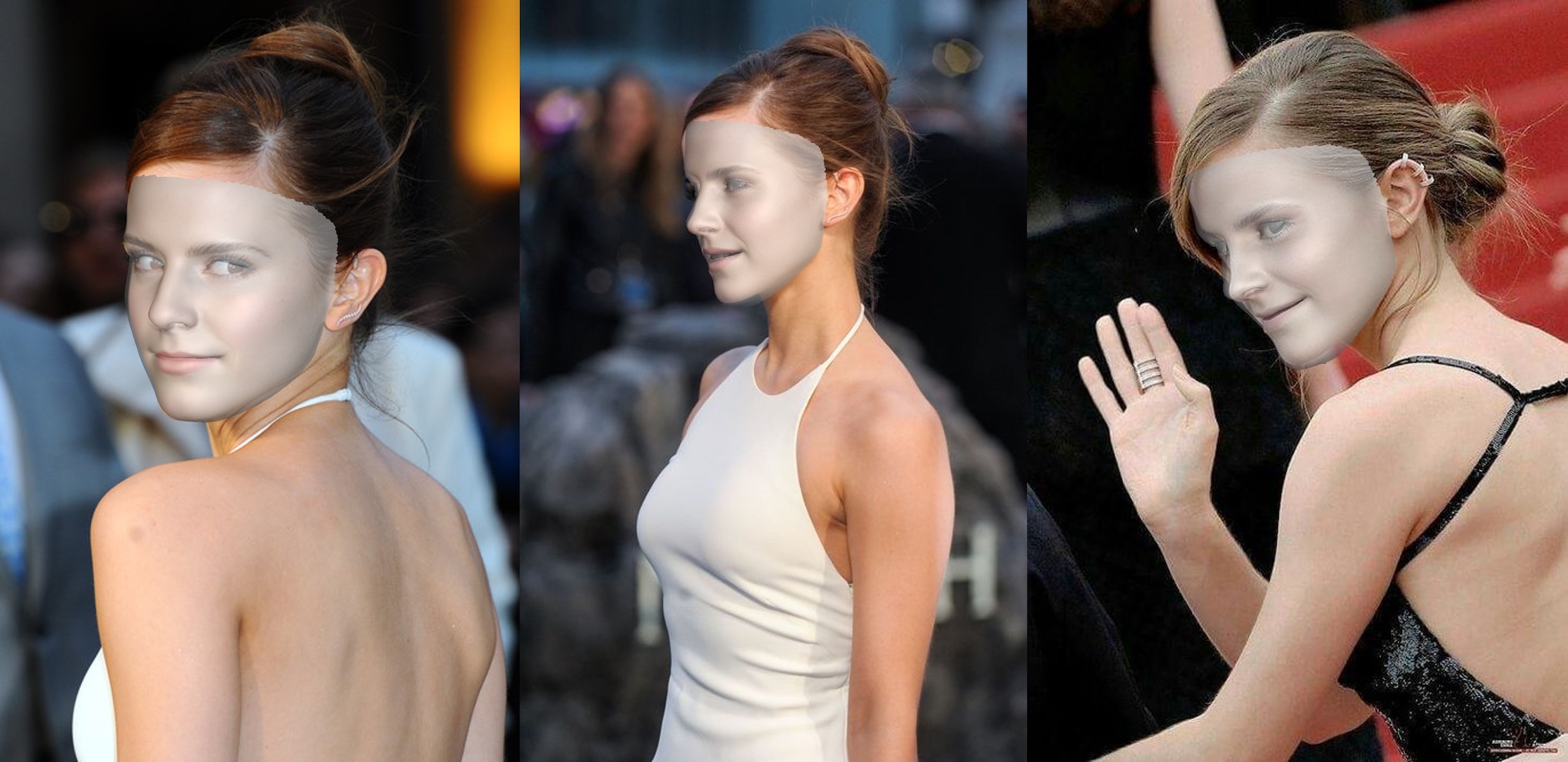
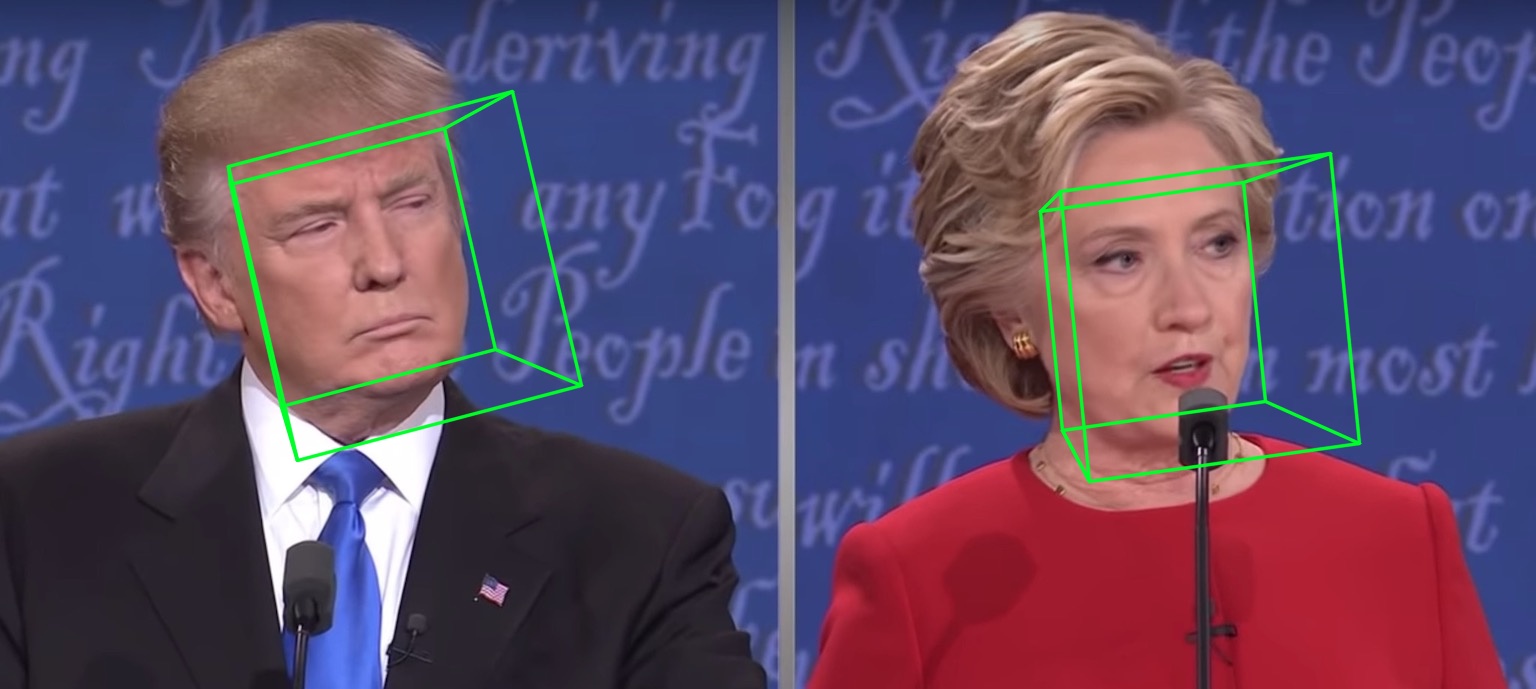
مثال آخر:

سيعطي الجري على مقطع فيديو:

المزيد من النتائج أو العروض التوضيحية لترى: هاثاواي.
| 2D تفرق | 2D كثيف | 3D |
|---|---|---|
 |  |  |
| عمق | PNCC | نسيج الأشعة فوق البنفسجية |
 |  |  |
| أَثَار | التسلسل إلى .ply | التسلسل إلى .OBJ |
 |  | 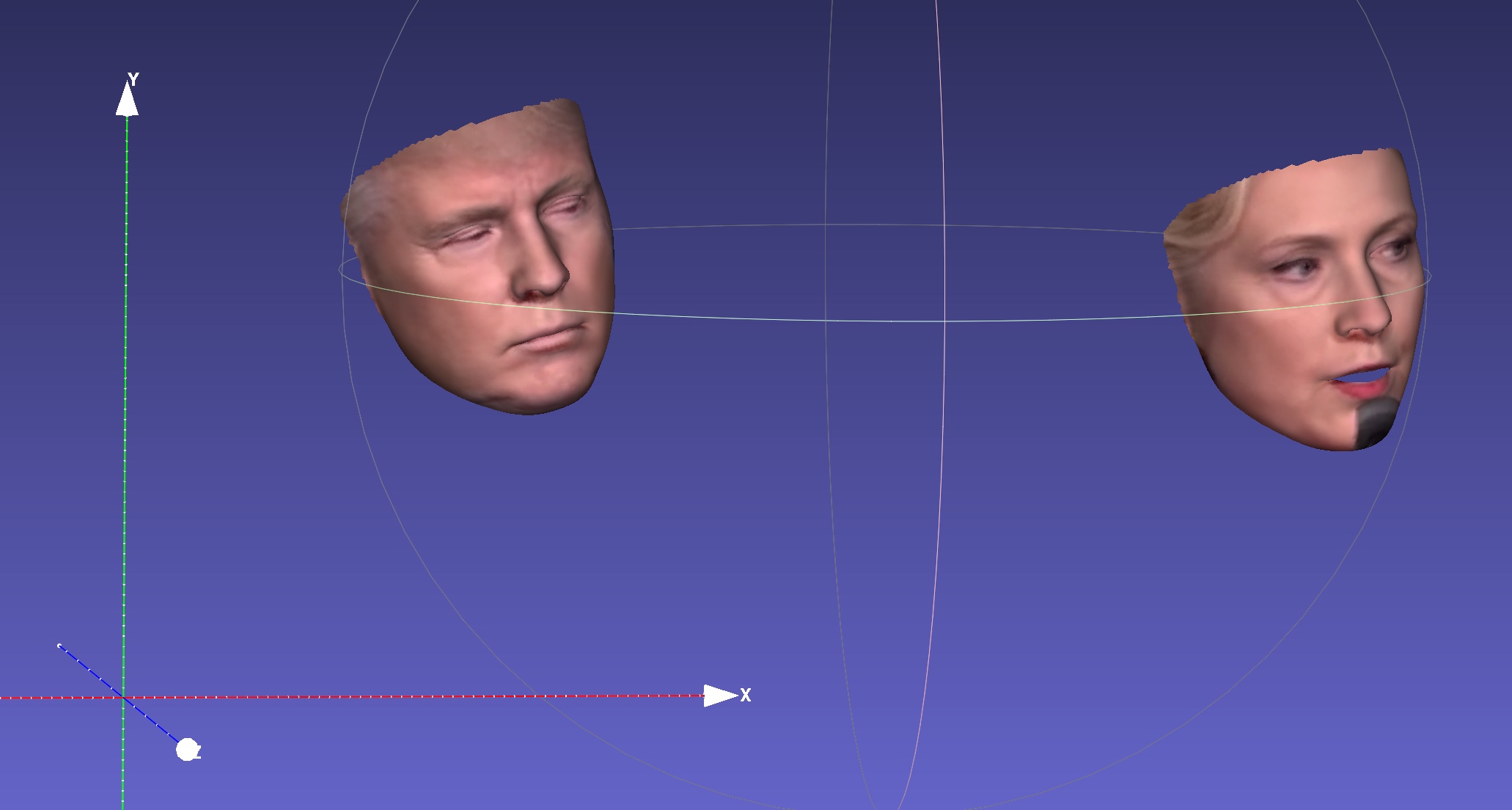 |
العمود الفقري الافتراضي هو mobilenet_v1 مع حجم الإدخال 120x120 والوزن الافتراضي قبل التدريب هو weights/mb1_120x120.pth ، الموضحة في configs/mb1_120x120.yml. يوفر هذا الريبو تكوينًا آخر في التكوينات/mb05_120x120.yml ، مع عامل التوسيع 0.5 ، حيث يكون أصغر وأسرع. يمكنك تحديد خيار التكوين بواسطة -c أو --config . يتم عرض النماذج التي تم إصدارها في الجدول أدناه. لاحظ أنه يتم تقييم وقت الاستدلال على وحدة المعالجة المركزية في الورقة باستخدام TensorFlow.
| نموذج | مدخل | #Params | #MACS | الاستدلال (TF) |
|---|---|---|---|---|
| Mobilenet | 120x120 | 3.27m | 183.5m | ~ 6.2ms |
| Mobilenet x0.5 | 120x120 | 0.85m | 49.5m | ~ 2.9ms |
والمثير للدهشة أن زمن انتقال onnxruntime أصغر بكثير. يظهر وقت الاستدلال على وحدة المعالجة المركزية مع مؤشرات ترابط مختلفة أدناه. يتم اختبار النتائج على MBP (I5-8259U CPU @ 2.30GHz على MacBook Pro 13 بوصة) ، مع إصدار 1.5.1 من OnNxRuntime. يتم تعيين رقم الموضوع بواسطة os.environ["OMP_NUM_THREADS"] ، راجع speed_cpu.py لمزيد من التفاصيل.
| نموذج | الموضوع = 1 | الموضوع = 2 | الموضوع = 4 |
|---|---|---|---|
| Mobilenet | 4.4ms | 2.25ms | 1.35ms |
| Mobilenet x0.5 | 1.37ms | 0.7ms | 0.5ms |
يقلل خيار onnx بشكل كبير من زمن انتقال وحدة المعالجة المركزية بشكل كبير ، لكن اكتشاف الوجه لا يزال يستغرق معظم وقت الكمون ، على سبيل المثال ، 15 مللي ثانية لصورة 720p. يستغرق الانحدار 3DMM للمعلمات حوالي 1 ~ 2 مللي ثانية للوجه الواحد ، وإعادة الإعمار الكثيف (أكثر من 30،000 نقطة ، أي 38365) حوالي 1 مللي ثانية للوجه واحد. قد تستفيد تطبيقات التتبع من سرعة الانحدار 3DMM السريعة ، نظرًا لأن الكشف غير ضروري لكل إطار. يتم اختبار الكمون باستخدام MacBook Pro مقاس 13 بوصة (I5-8259U CPU @ 2.30GHz).
تم تعيين OMP_NUM_THREADS الافتراضي 4 ، يمكنك تحديده عن طريق تعيين os.environ['OMP_NUM_THREADS'] = '$NUM' أو إدراج export OMP_NUM_THREADS=$NUM قبل تشغيل البرنامج النصي python.
ما هي بيانات التدريب؟
نستخدم 300W-LP للتدريب. يمكنك الرجوع إلى ورقتنا لمزيد من التفاصيل حول التدريب. نظرًا لأن القليل من الصور مغلقة في بيانات التدريب 300W-LP ، فإن معالم العيون ليست دقيقة عند الإغلاق. جزء العيون من عرض كاميرا الويب ليست جيدة أيضًا.
تشغيل على Windows.
يمكنك الرجوع إلى هذا التعليق لبناء NMS على Windows.
إذا كان عملك أو بحثك يستفيد من هذا الريبو ، فيرجى الاستشهاد بالمرايل أدناه :) و؟ هذا الريبو.
@inproceedings{guo2020towards,
title = {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author = {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
Jianzhu Guo (郭建珠) [الصفحة الرئيسية ، الباحث العلمي من Google]: [email protected] أو [email protected] أو [email protected] (سيتم ذلك هذا البريد الإلكتروني قريبًا).


