ai markdown llm retrieval
1.0.0
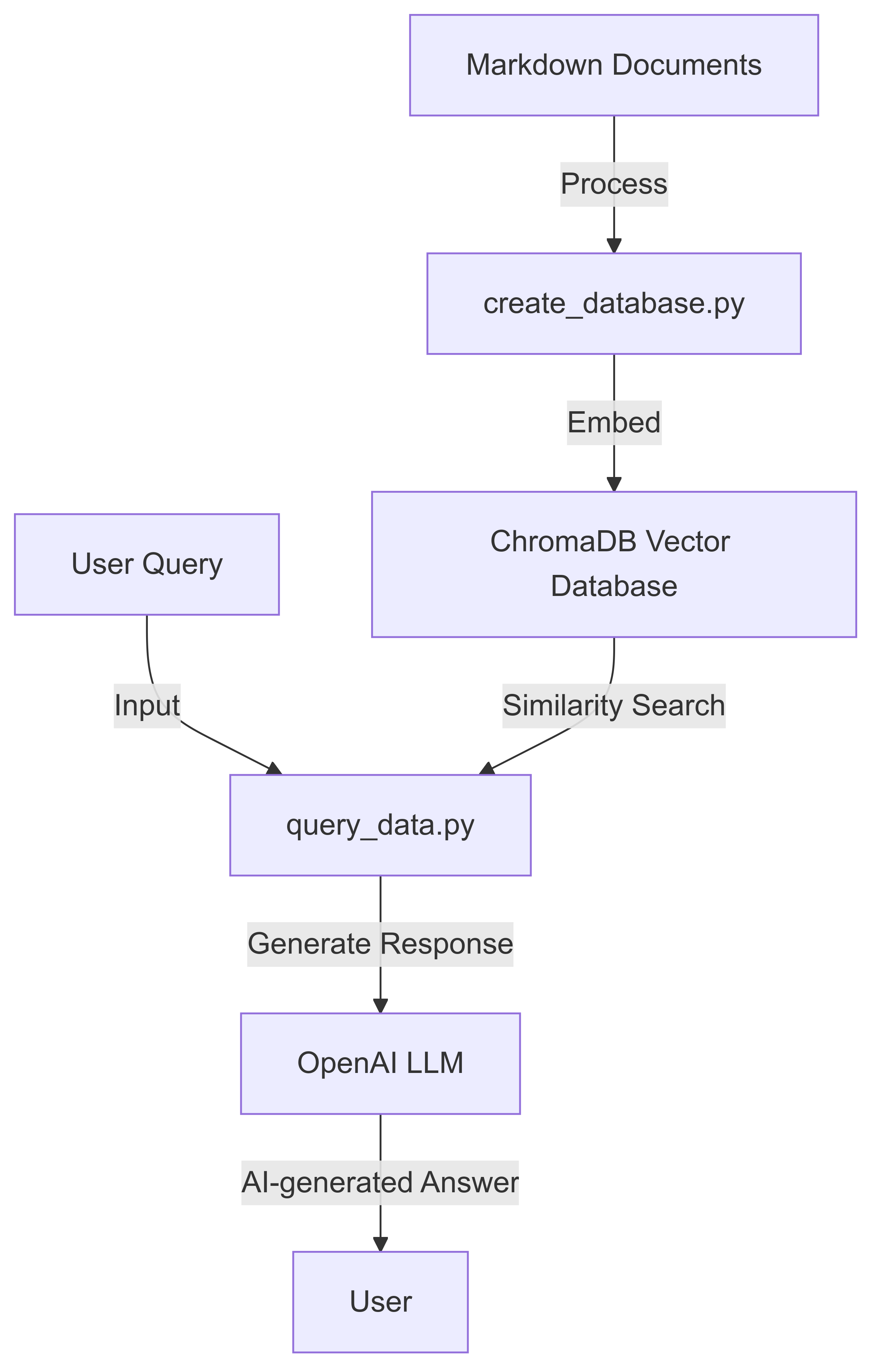
该项目使用Langchain,Chromadb和OpenAI的语言模型实现了AI驱动的文档查询系统。它使用户能够从Markdown文档创建可搜索的数据库,并使用自然语言查询。
requirements.txt中列出的依赖项.txt python -m venv .venv
source .venv/bin/activate # On Windows, use `.venvScriptsactivate`
pip install -r requirements.txt
.env文件中设置OpenAI API密钥: OPENAI_API_KEY=your_api_key_here
请按照以下步骤快速设置并使用基于RAG的VectordB-LLM查询引擎:
从您的Markdown文档创建数据库:
python create_database.py --data_folder data/go-docs --chroma_db_path chroma_go_docs/
此命令将在数据/ GO-DOCS目录中处理Markdown文件,并在Chroma_go_docs/文件夹中创建一个向量数据库。
用自然语言问题查询数据库:
python query_data.py --query_text "Explain goroutines in go in a sentence" --chroma_db_path chroma_go_docs/ --prompt_model gpt-3.5-turbo
查看AI生成的响应:
Goroutines are lightweight, concurrent functions or methods in Go that run independently, managed by the Go runtime, allowing for efficient parallel execution and easy implementation of concurrent programming patterns.
有关更详细的用法说明,请参阅以下各节:
创建数据库
python create_database.py --data_folder path/to/your/markdown/files --chroma_db_path path/to/save/database
查询数据库
python query_data.py --query_text "Your question here" --chroma_db_path path/to/database --prompt_model gpt-3.5-turbo
create_database.py :数据库创建脚本query_data.py :数据库查询脚本estimate_cost.py :成本估算模块get_token_count.py :代币计数实用程序data/ :Markdown Documents目录chroma/ :Chromadb数据库存储(Gitignored) text-embedding-3-small用于嵌入和gpt-3.5-turbodata/或指定自定义路径chroma/ (Gitignored)中该项目是根据MIT许可证的条款获得许可的。有关更多信息,请参阅许可证文件。
有关问题或问题,请在GitHub存储库上打开一个问题。


