ai markdown llm retrieval
1.0.0
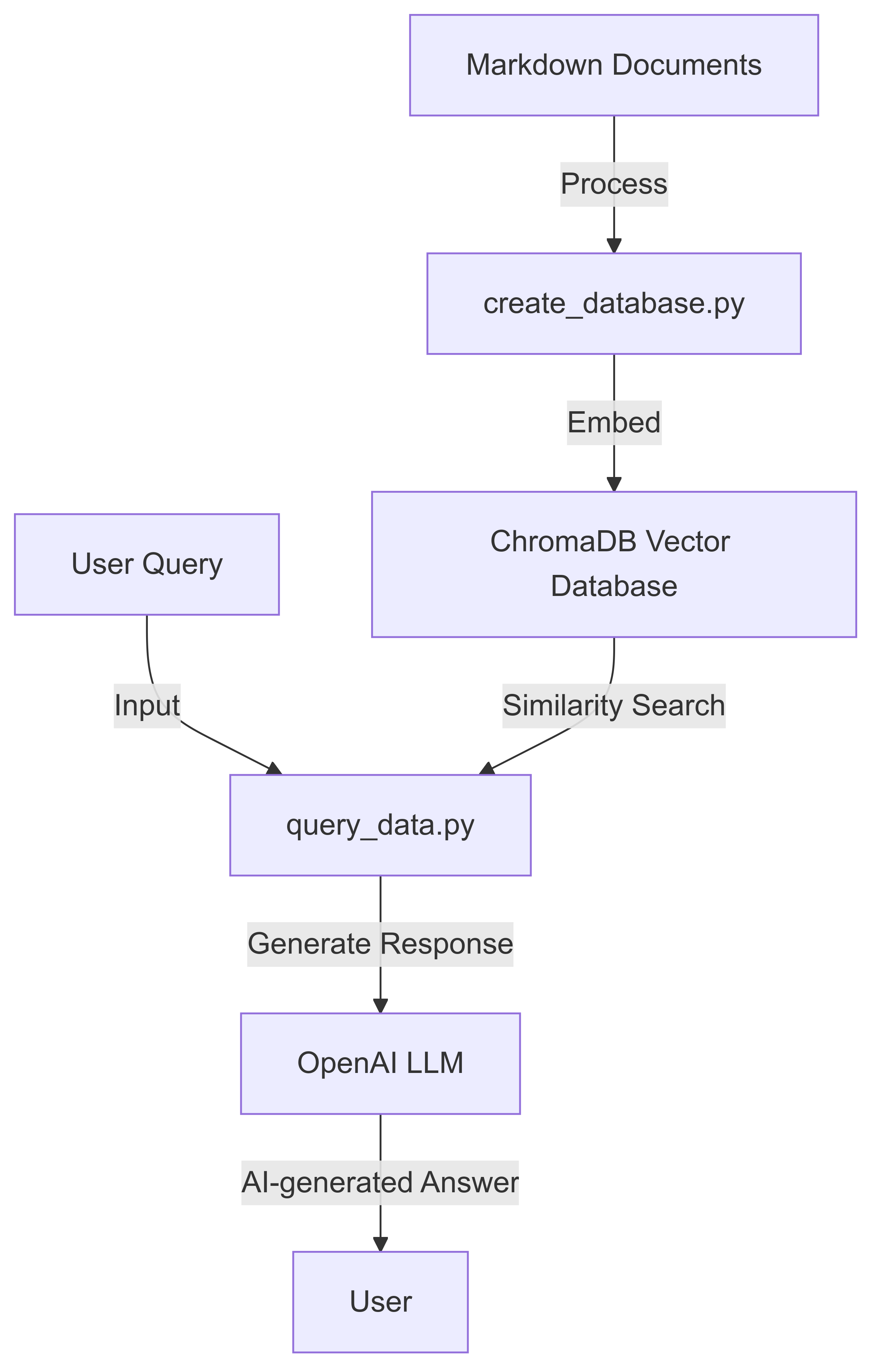
このプロジェクトは、Langchain、Chromadb、およびOpenaiの言語モデルを使用して、AIを搭載したドキュメントクエリシステムを実装しています。ユーザーは、Markdownドキュメントから検索可能なデータベースを作成し、自然言語を使用して照会することができます。
requirements.txtにリストされている依存関係。txt python -m venv .venv
source .venv/bin/activate # On Windows, use `.venvScriptsactivate`
pip install -r requirements.txt
.envファイルにOpenAI APIキーを設定します。 OPENAI_API_KEY=your_api_key_here
これらの手順に従って、ragベースのVectordb-llmクエリエンジンをすばやくセットアップして使用します。
マークダウンドキュメントからデータベースを作成します。
python create_database.py --data_folder data/go-docs --chroma_db_path chroma_go_docs/
このコマンドは、データ/ go-Docsディレクトリ内のマークダウンファイルを処理し、chroma_go_docs/フォルダーにベクトルデータベースを作成します。
自然言語の質問でデータベースをクエリします:
python query_data.py --query_text "Explain goroutines in go in a sentence" --chroma_db_path chroma_go_docs/ --prompt_model gpt-3.5-turbo
AIに生成された応答を表示します。
Goroutines are lightweight, concurrent functions or methods in Go that run independently, managed by the Go runtime, allowing for efficient parallel execution and easy implementation of concurrent programming patterns.
より詳細な使用手順については、次のセクションを参照してください。
データベースを作成します
python create_database.py --data_folder path/to/your/markdown/files --chroma_db_path path/to/save/database
データベースをクエリします
python query_data.py --query_text "Your question here" --chroma_db_path path/to/database --prompt_model gpt-3.5-turbo
create_database.py :データベース作成スクリプトquery_data.py :データベースクエリスクリプトestimate_cost.py :コスト見積もりモジュールget_token_count.py :トークンカウントユーティリティdata/ :マークダウンドキュメントディレクトリchroma/ :Chromadbデータベースストレージ(Gitignored) text-embedding-3-smallを使用し、デフォルトで応答にgpt-3.5-turbo使用しますdata/またはカスタムパスを指定するchroma/ (gitignored)に保存されているChromaDBデータベースこのプロジェクトは、MITライセンスの条件に基づいてライセンスされています。詳細については、ライセンスファイルを参照してください。
質問や問題については、GitHubリポジトリで問題を開いてください。


