ai markdown llm retrieval
1.0.0
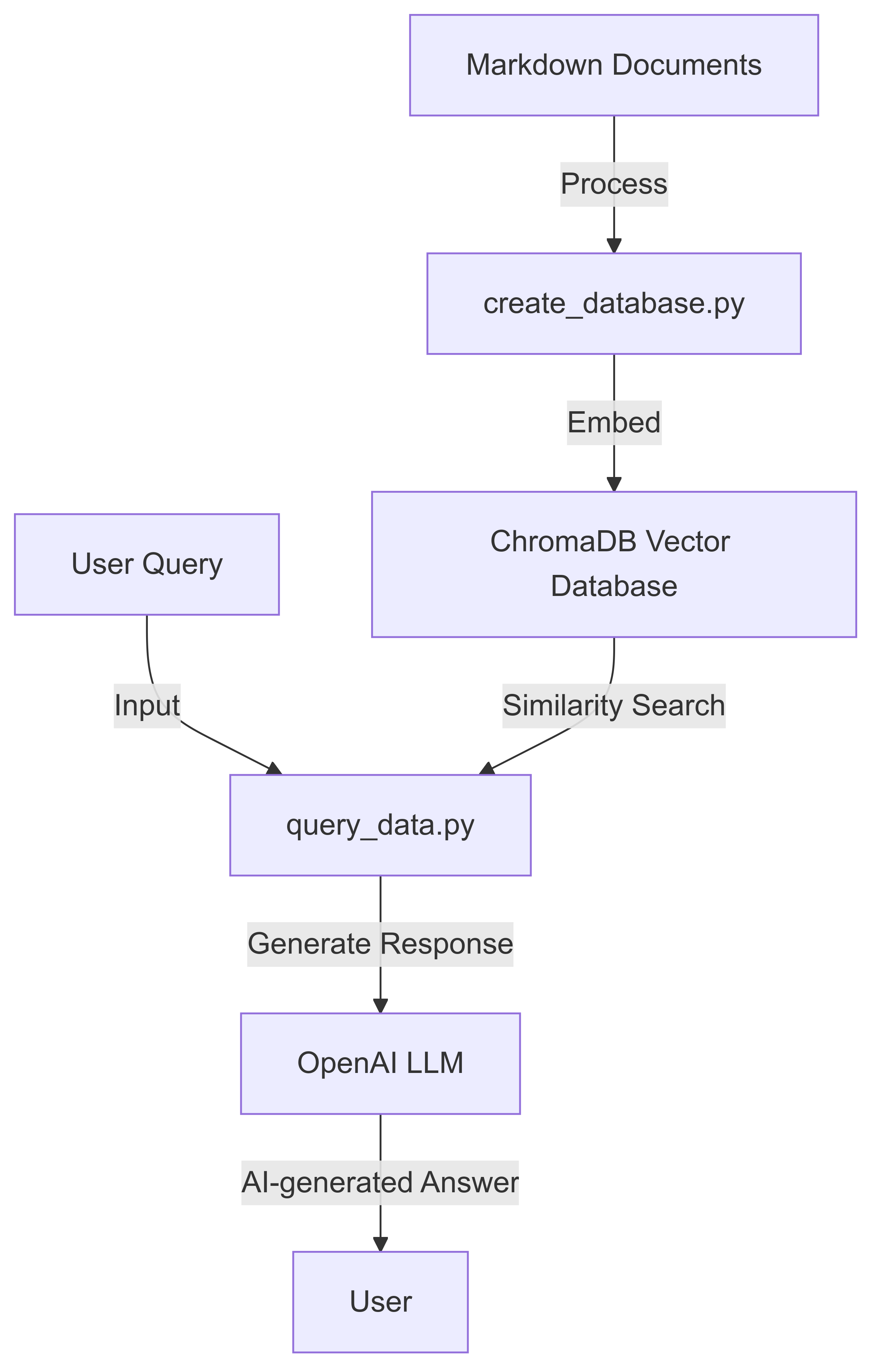
이 프로젝트는 Langchain, ChromADB 및 OpenAI의 언어 모델을 사용하여 AI 기반 문서 쿼리 시스템을 구현합니다. 이를 통해 사용자는 Markdown 문서에서 검색 가능한 데이터베이스를 만들고 자연어를 사용하여 쿼리 할 수 있습니다.
requirements.txt 에 나열된 종속성 .txt python -m venv .venv
source .venv/bin/activate # On Windows, use `.venvScriptsactivate`
pip install -r requirements.txt
.env 파일에서 OpenAI API 키를 설정하십시오. OPENAI_API_KEY=your_api_key_here
다음 단계에 따라 Rag 기반 VectorDB-LLM 쿼리 엔진을 신속하게 설정하고 사용하십시오.
Markdown 문서에서 데이터베이스를 작성하십시오.
python create_database.py --data_folder data/go-docs --chroma_db_path chroma_go_docs/
이 명령은 Data/ Go-Docs 디렉토리에서 Markdown 파일을 처리하고 Chroma_go_docs/ 폴더에서 벡터 데이터베이스를 만듭니다.
자연어 질문으로 데이터베이스를 쿼리하십시오.
python query_data.py --query_text "Explain goroutines in go in a sentence" --chroma_db_path chroma_go_docs/ --prompt_model gpt-3.5-turbo
AI 생성 응답보기 :
Goroutines are lightweight, concurrent functions or methods in Go that run independently, managed by the Go runtime, allowing for efficient parallel execution and easy implementation of concurrent programming patterns.
보다 자세한 사용 지침은 다음 섹션을 참조하십시오.
데이터베이스를 만듭니다
python create_database.py --data_folder path/to/your/markdown/files --chroma_db_path path/to/save/database
데이터베이스를 쿼리하십시오
python query_data.py --query_text "Your question here" --chroma_db_path path/to/database --prompt_model gpt-3.5-turbo
create_database.py : 데이터베이스 생성 스크립트query_data.py : 데이터베이스 쿼리 스크립트estimate_cost.py : 비용 추정 모듈get_token_count.py : 토큰 계산 유틸리티data/ : Markdown 문서 디렉토리chroma/ : ChromADB 데이터베이스 스토리지 (Gitignored) gpt-3.5-turbo 에 OpenAi의 text-embedding-3-small 사용합니다.data/ 또는 사용자 정의 경로 지정chroma/ (Gitignored)에 저장 이 프로젝트는 MIT 라이센스의 조건에 따라 라이센스가 부여됩니다. 자세한 내용은 라이센스 파일을 참조하십시오.
질문이나 문제는 Github 저장소에 문제를여십시오.


