ai markdown llm retrieval
1.0.0
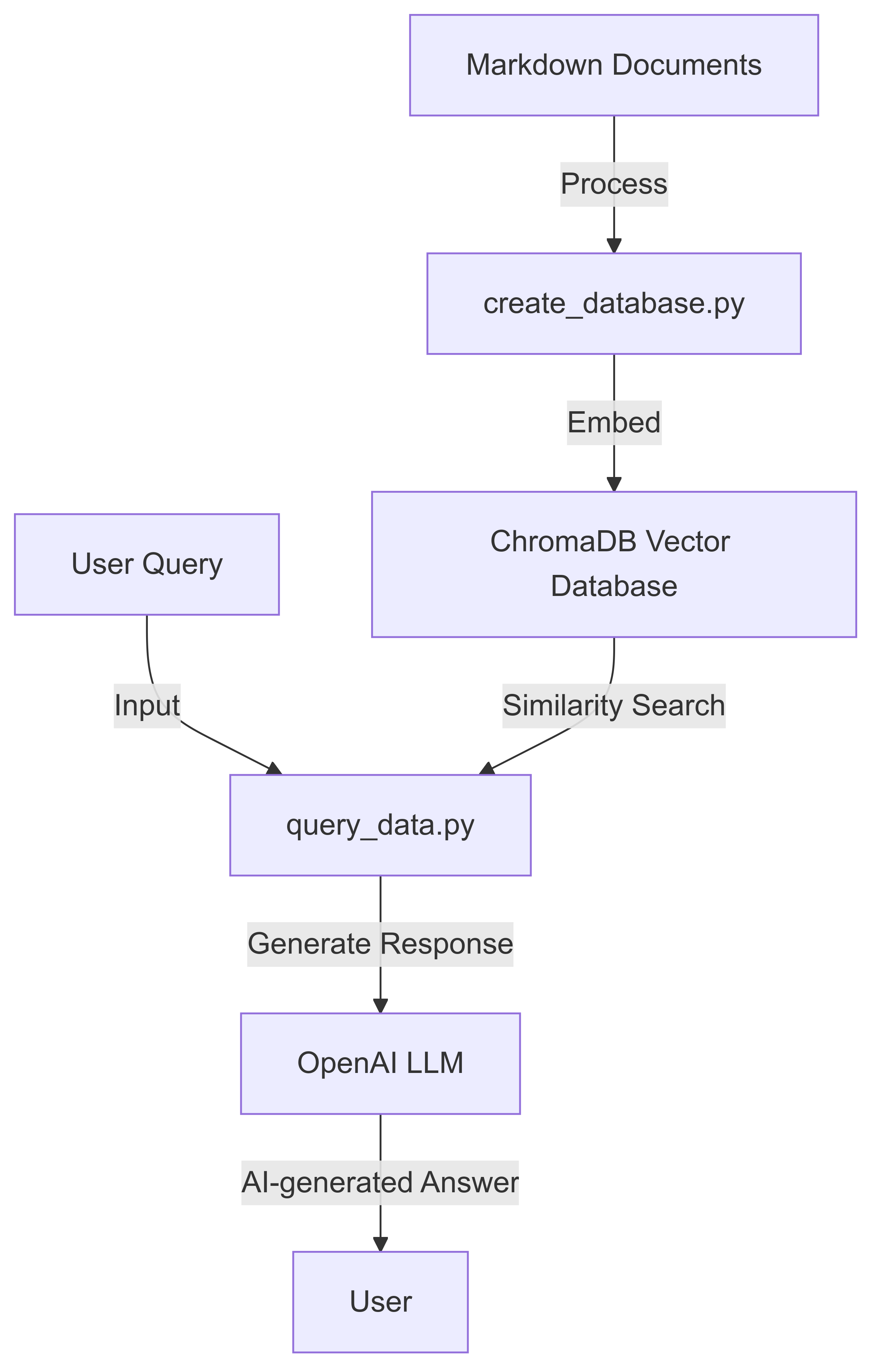
โครงการนี้ใช้ระบบการสืบค้นเอกสารที่ใช้ AI โดยใช้ Langchain, Chromadb และโมเดลภาษาของ Openai ช่วยให้ผู้ใช้สามารถสร้างฐานข้อมูลที่ค้นหาได้จากเอกสาร Markdown และสอบถามโดยใช้ภาษาธรรมชาติ
requirements.txt python -m venv .venv
source .venv/bin/activate # On Windows, use `.venvScriptsactivate`
pip install -r requirements.txt
.env : OPENAI_API_KEY=your_api_key_here
ทำตามขั้นตอนเหล่านี้เพื่อตั้งค่าอย่างรวดเร็วและใช้เครื่องมือค้นหา vectordb-llm ที่ใช้ RAG:
สร้างฐานข้อมูลจากเอกสาร Markdown ของคุณ:
python create_database.py --data_folder data/go-docs --chroma_db_path chroma_go_docs/
คำสั่งนี้จะประมวลผลไฟล์ Markdown ในไดเรกทอรี Data/ Go-Docs และสร้างฐานข้อมูลเวกเตอร์ในโฟลเดอร์ chroma_go_docs/
สอบถามฐานข้อมูลด้วยคำถามภาษาธรรมชาติ:
python query_data.py --query_text "Explain goroutines in go in a sentence" --chroma_db_path chroma_go_docs/ --prompt_model gpt-3.5-turbo
ดูการตอบสนองที่สร้างขึ้นโดย AI:
Goroutines are lightweight, concurrent functions or methods in Go that run independently, managed by the Go runtime, allowing for efficient parallel execution and easy implementation of concurrent programming patterns.
สำหรับคำแนะนำการใช้งานโดยละเอียดเพิ่มเติมโปรดดูส่วนต่อไปนี้:
สร้างฐานข้อมูล
python create_database.py --data_folder path/to/your/markdown/files --chroma_db_path path/to/save/database
สอบถามฐานข้อมูล
python query_data.py --query_text "Your question here" --chroma_db_path path/to/database --prompt_model gpt-3.5-turbo
create_database.py : สคริปต์การสร้างฐานข้อมูลquery_data.py : สคริปต์การสืบค้นฐานข้อมูลestimate_cost.py : โมดูลการประมาณราคาget_token_count.py : ยูทิลิตี้การนับโทเค็นdata/ : DIRECUMENTS MARKDOWN Documentchroma/ : การจัดเก็บฐานข้อมูล Chromadb (Gitignored) text-embedding-3-small ของ OpenAI สำหรับ Embeddings และ gpt-3.5-turbo สำหรับการตอบกลับโดยค่าเริ่มต้นdata/ หรือระบุเส้นทางที่กำหนดเองchroma/ (Gitignored) โครงการนี้ได้รับใบอนุญาตภายใต้ข้อกำหนดของใบอนุญาต MIT สำหรับข้อมูลเพิ่มเติมโปรดดูไฟล์ใบอนุญาต
สำหรับคำถามหรือปัญหาโปรดเปิดปัญหาเกี่ยวกับที่เก็บ GitHub


