ai markdown llm retrieval
1.0.0
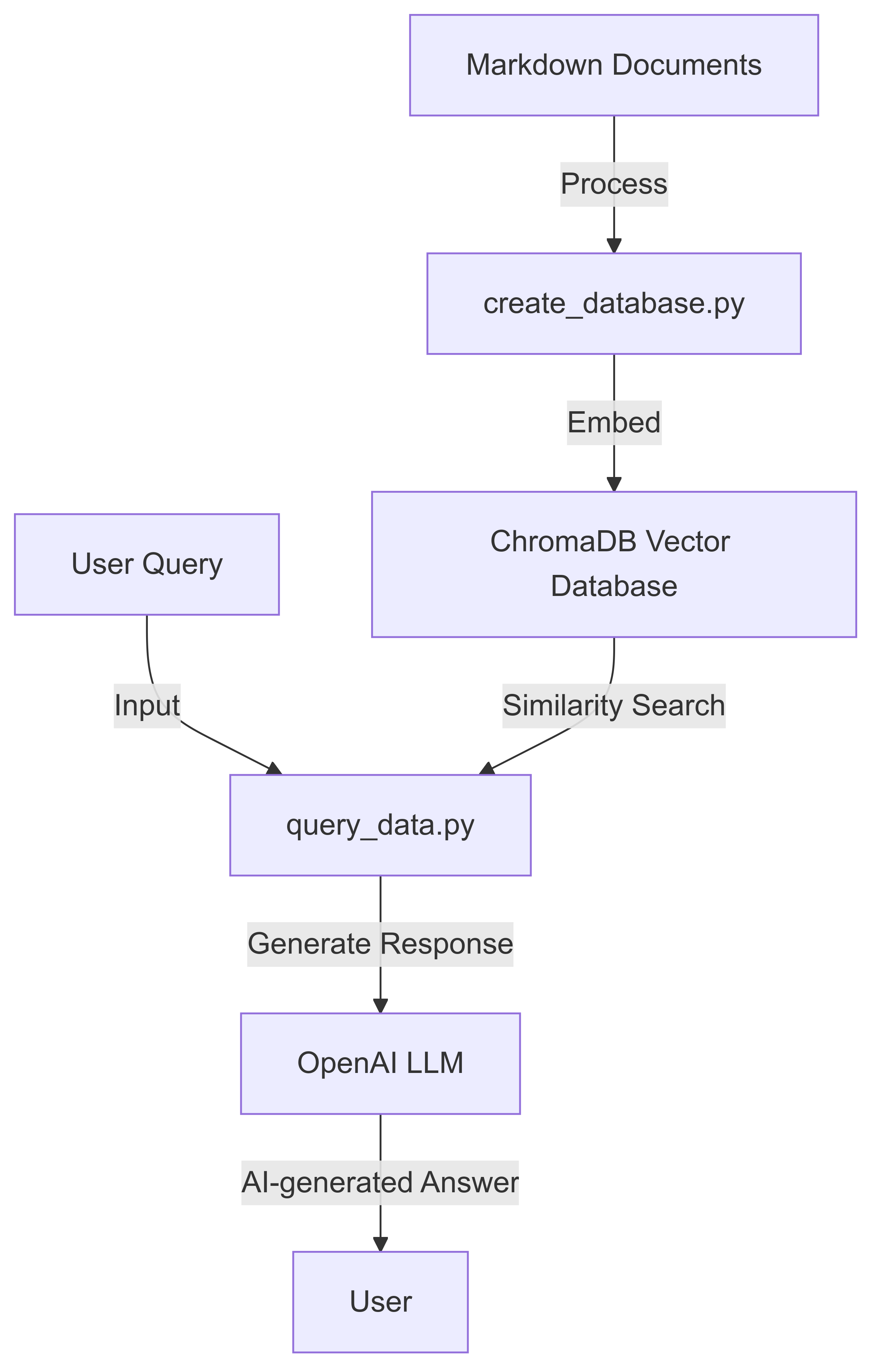
ينفذ هذا المشروع نظام استعلام المستندات الذي يعمل بمنظمة العفو الدولية باستخدام نماذج لغة Langchain و ChromadB و Openai. يمكّن المستخدمين من إنشاء قاعدة بيانات قابلة للبحث من مستندات Markdown والاستعلام عنها باستخدام اللغة الطبيعية.
requirements.txt python -m venv .venv
source .venv/bin/activate # On Windows, use `.venvScriptsactivate`
pip install -r requirements.txt
.env : OPENAI_API_KEY=your_api_key_here
اتبع هذه الخطوات لإعداد واستخدام محرك استعلام Vectordb-Llm المستند إلى Rag:
قم بإنشاء قاعدة بيانات من مستندات Markdown:
python create_database.py --data_folder data/go-docs --chroma_db_path chroma_go_docs/
سيقوم هذا الأمر بمعالجة ملفات Markdown في دليل البيانات/ GO-DOCS وإنشاء قاعدة بيانات متجه في CHROMA_GO_DOCS/ FOLDER.
الاستعلام عن قاعدة البيانات بسؤال لغة طبيعي:
python query_data.py --query_text "Explain goroutines in go in a sentence" --chroma_db_path chroma_go_docs/ --prompt_model gpt-3.5-turbo
عرض الاستجابة التي أنشأها الذكاء الاصطناعي:
Goroutines are lightweight, concurrent functions or methods in Go that run independently, managed by the Go runtime, allowing for efficient parallel execution and easy implementation of concurrent programming patterns.
لمزيد من تعليمات الاستخدام التفصيلية ، راجع الأقسام التالية:
إنشاء قاعدة البيانات
python create_database.py --data_folder path/to/your/markdown/files --chroma_db_path path/to/save/database
الاستعلام عن قاعدة البيانات
python query_data.py --query_text "Your question here" --chroma_db_path path/to/database --prompt_model gpt-3.5-turbo
create_database.py : برنامج إنشاء قاعدة البياناتquery_data.py : نصوص الاستعلام عن قاعدة البياناتestimate_cost.py : وحدة تقدير التكلفةget_token_count.py : أداة العد الرمزيةdata/ : دليل مستندات Markdownchroma/ : تخزين قاعدة بيانات Chromadb (gitignored) text-embedding-3-small للتضمينات و gpt-3.5-turbo للاستجابات افتراضيًاdata/ أو حدد مسار مخصصchroma/ (gitignored) هذا المشروع مرخص بموجب شروط ترخيص معهد ماساتشوستس للتكنولوجيا. لمزيد من المعلومات ، يرجى الرجوع إلى ملف الترخيص.
للأسئلة أو القضايا ، يرجى فتح مشكلة على مستودع GitHub.


