simple effective text matching
1.0.0
这是ACL 2019纸张简单有效的文本匹配以及更丰富的对齐功能的原始张量实现。 Pytorch实施:https://github.com/alibaba-edu/simple-effective-text-matching-pytorch。
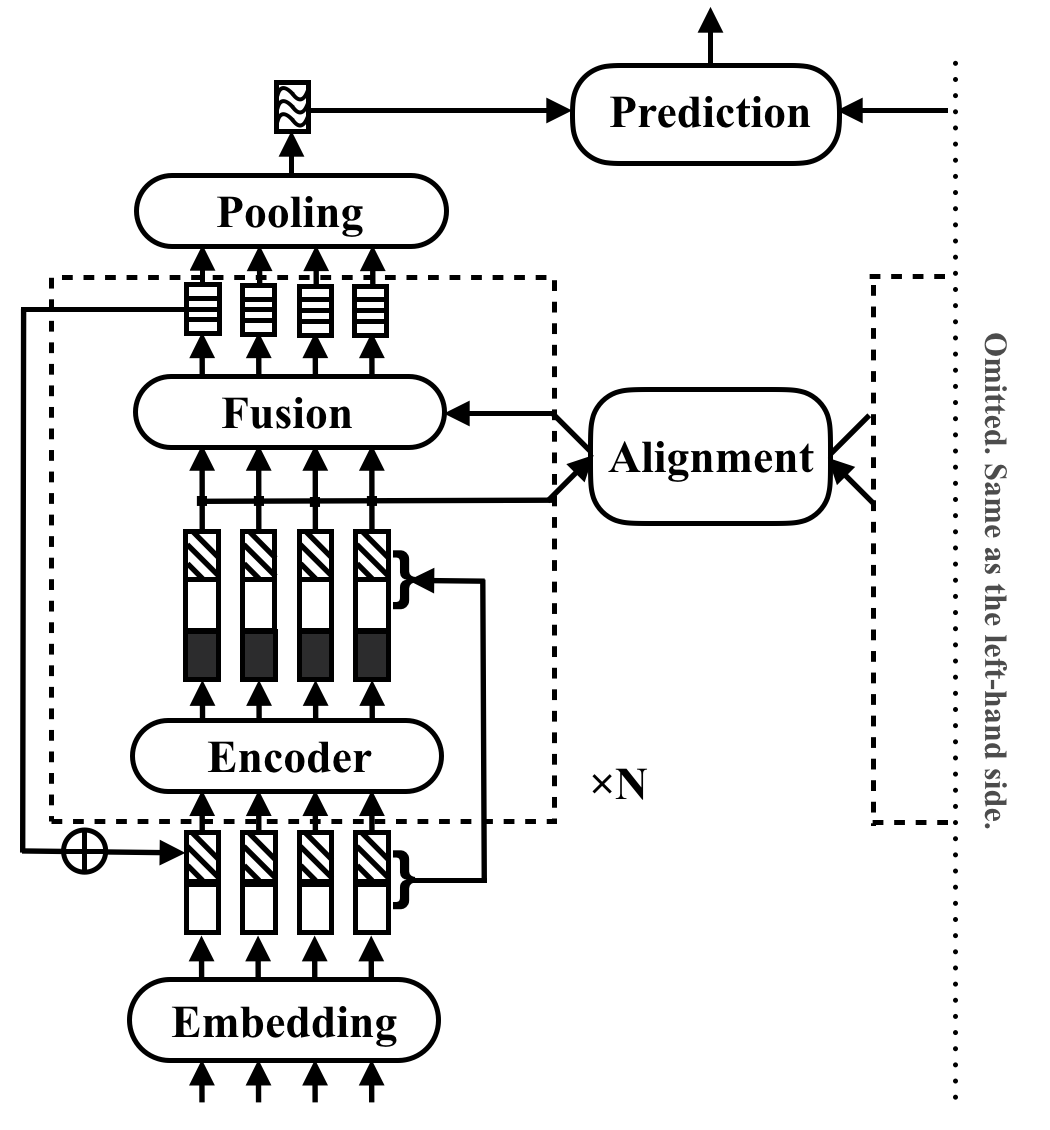
RE2是通用文本匹配应用程序的快速而强大的神经体系结构。在文本匹配任务中,模型将两个文本序列作为输入并预测其关系。该方法旨在探索在这些任务中出现强大绩效的足够的方法。它简化或省略了许多以前被视为文本匹配中的核心构建块的慢速组件。它通过一个简单的想法来实现其性能,该想法使三个关键功能直接可用于相互对齐和融合:以前的对齐功能( r esidual矢量),原始点的特征( e mbedding矢量)和上下文功能( e ncoder output)。
RE2在四个基准数据集上与最先进的状态(SNLI,SCITAIL,QUORA和WIKIQA)在自然语言推理,释义识别和答案选择的情况下,没有或几个任务特定于特定于任务的适应性。与类似执行的模型相比,它的推理速度至少要快6倍。
下表列出了主要实验结果。本文报告了10次运行的平均值和标准偏差,结果很容易再现。推理时间(以秒为单位)是通过处理英特尔i7 CPU上的8对长度20的批次来测量的。不包括CSRAN和DIIN使用的POS功能的计算时间。
| 模型 | snli | Scitail | Quora | Wikiqa | 推理时间 |
|---|---|---|---|---|---|
| Bimpm | 86.9 | - | 88.2 | 0.731 | 0.05 |
| Esim | 88.0 | 70.6 | - | - | - |
| 迪恩 | 88.0 | - | 89.1 | - | 1.79 |
| 克里斯兰人 | 88.7 | 86.7 | 89.2 | - | 0.28 |
| RE2 | 88.9±0.1 | 86.0±0.6 | 89.2±0.2 | 0.7618±0.0040 | 0.03〜0.05 |
有关组件和实验结果的更多详细信息,请参阅本文。
pip install -r requirements.txtresources/本文中使用的数据如下:
data/orig 。cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig 。cd data && python prepare_scitail.pydata/orig 。cd data && python prepare_quora.pydata/orig 。cd data && python prepare_wikiqa.pymake -B命令在qg-emnlp07-data/eval/trec_eval-8.0中编译源文件。将二进制文件“ TREC_EVAL”移至resources/ 。 要训练新的文本匹配模型,请运行以下命令:
python train.py $config_file .json5示例配置文件以configs/ :::
configs/main.json5 :在论文中复制主实验结果。configs/robustness.json5 :鲁棒性检查configs/ablation.json5 :消融研究编写您自己的配置文件的说明:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]要仅检查配置,请使用
python train.py $config_file .json5 --dry如果您在工作中使用RE2,请引用ACL纸:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
RE2在Apache许可证2.0下。


