simple effective text matching
1.0.0
นี่คือการใช้งาน Tensorflow ดั้งเดิมของ ACL 2019 Paper ที่ง่ายและมีประสิทธิภาพการจับคู่ข้อความที่มีประสิทธิภาพกับคุณสมบัติการจัดตำแหน่งที่สมบูรณ์ยิ่งขึ้น การใช้งาน Pytorch: https://github.com/alibaba-edu/simple-effective-ext-matching-pytorch
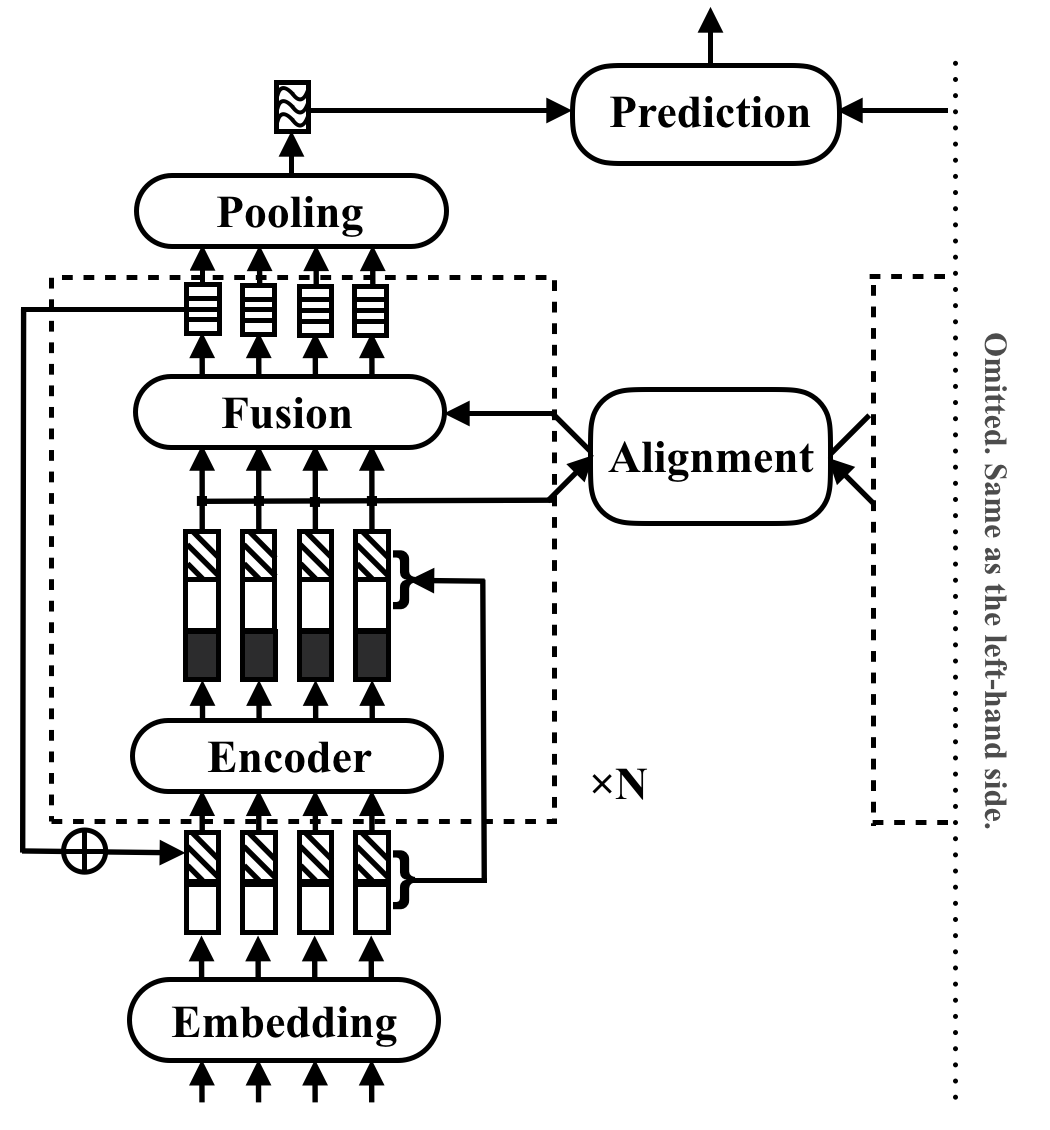
RE2 เป็นสถาปัตยกรรมประสาทที่รวดเร็วและแข็งแกร่งสำหรับแอพพลิเคชั่นการจับคู่ข้อความวัตถุประสงค์ทั่วไป ในงานการจับคู่ข้อความโมเดลจะใช้ลำดับข้อความสองลำดับเป็นอินพุตและทำนายความสัมพันธ์ของพวกเขา วิธีนี้มีจุดมุ่งหมายเพื่อสำรวจสิ่งที่เพียงพอสำหรับประสิทธิภาพที่แข็งแกร่งในงานเหล่านี้ มันง่ายขึ้นหรือละเว้นส่วนประกอบช้าจำนวนมากซึ่งก่อนหน้านี้ถือว่าเป็นหน่วยการสร้างหลักในการจับคู่ข้อความ มันประสบความสำเร็จในการปฏิบัติงานโดยแนวคิดง่ายๆซึ่งเป็นคุณสมบัติที่สำคัญสามประการที่มีอยู่โดยตรงสำหรับการจัดตำแหน่งระหว่างลำดับและฟิวชั่น: คุณสมบัติที่จัดเรียงก่อนหน้านี้ (เวกเตอร์ esidual ), คุณสมบัติจุดที่ชาญฉลาด ดั้งเดิม (เวกเตอร์ mbedding ) และคุณสมบัติตามบริบท
RE2 ประสบความสำเร็จในการแสดงเทียบกับสถานะของศิลปะในชุดข้อมูลมาตรฐานสี่ชุด: SNLI, Scitail, Quora และ Wikiqa ข้ามงานการอนุมานภาษาธรรมชาติการระบุตัวตนและการเลือกคำตอบโดยไม่มีการปรับเฉพาะงานเฉพาะ มันมีความเร็วการอนุมานเร็วขึ้นอย่างน้อย 6 เท่าเมื่อเทียบกับรุ่นที่ดำเนินการในทำนองเดียวกัน
ตารางต่อไปนี้แสดงผลการทดลองที่สำคัญ กระดาษรายงานค่าเฉลี่ยและค่าเบี่ยงเบนมาตรฐานของ 10 การรันและผลลัพธ์สามารถทำซ้ำได้ง่าย เวลาอนุมาน (ในไม่กี่วินาที) วัดโดยการประมวลผลชุดความยาว 8 คู่ 20 บนซีพียู Intel i7 ไม่รวมเวลาการคำนวณของคุณสมบัติ POS ที่ใช้โดย CSRAN และ DIIN
| แบบอย่าง | snli | เค็ม | quora | วิกิ | เวลาอนุมาน |
|---|---|---|---|---|---|
| bimpm | 86.9 | - | 88.2 | 0.731 | 0.05 |
| esim | 88.0 | 70.6 | - | - | - |
| diin | 88.0 | - | 89.1 | - | 1.79 |
| CSRAN | 88.7 | 86.7 | 89.2 | - | 0.28 |
| RE2 | 88.9 ± 0.1 | 86.0 ± 0.6 | 89.2 ± 0.2 | 0.7618 ± 0.0040 | 0.03 ~ 0.05 |
อ้างถึงกระดาษสำหรับรายละเอียดเพิ่มเติมของส่วนประกอบและผลการทดลอง
pip install -r requirements.txtresources/ข้อมูลที่ใช้ในกระดาษจัดทำขึ้นดังนี้:
data/origcd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/origcd data && python prepare_scitail.pydata/origcd data && python prepare_quora.pydata/origcd data && python prepare_wikiqa.pymake -B เพื่อรวบรวมไฟล์ต้นฉบับใน qg-emnlp07-data/eval/trec_eval-8.0 ย้ายไฟล์ไบนารี "trec_eval" ไปยัง resources/ ในการฝึกอบรมรูปแบบการจับคู่ข้อความใหม่ให้เรียกใช้คำสั่งต่อไปนี้:
python train.py $config_file .json5 ตัวอย่างไฟล์การกำหนดค่ามีอยู่ใน configs/ :
configs/main.json5 : ทำซ้ำผลการทดลองหลักในกระดาษconfigs/robustness.json5 : การตรวจสอบความทนทานconfigs/ablation.json5 : การศึกษาการระเหยคำแนะนำในการเขียนไฟล์การกำหนดค่าของคุณเอง:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]หากต้องการตรวจสอบการกำหนดค่าเท่านั้นให้ใช้
python train.py $config_file .json5 --dryโปรดอ้างอิงกระดาษ ACL หากคุณใช้ RE2 ในงานของคุณ:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
RE2 อยู่ภายใต้ Apache License 2.0


