simple effective text matching
1.0.0
Это оригинальная реализация TensorFlow бумаги ACL 2019 Простых и эффективных текста, сопоставляющих текст с более богатыми функциями выравнивания. Реализация Pytorch: https://github.com/alibaba-edu/simple-effective-text-matching-pytorch.
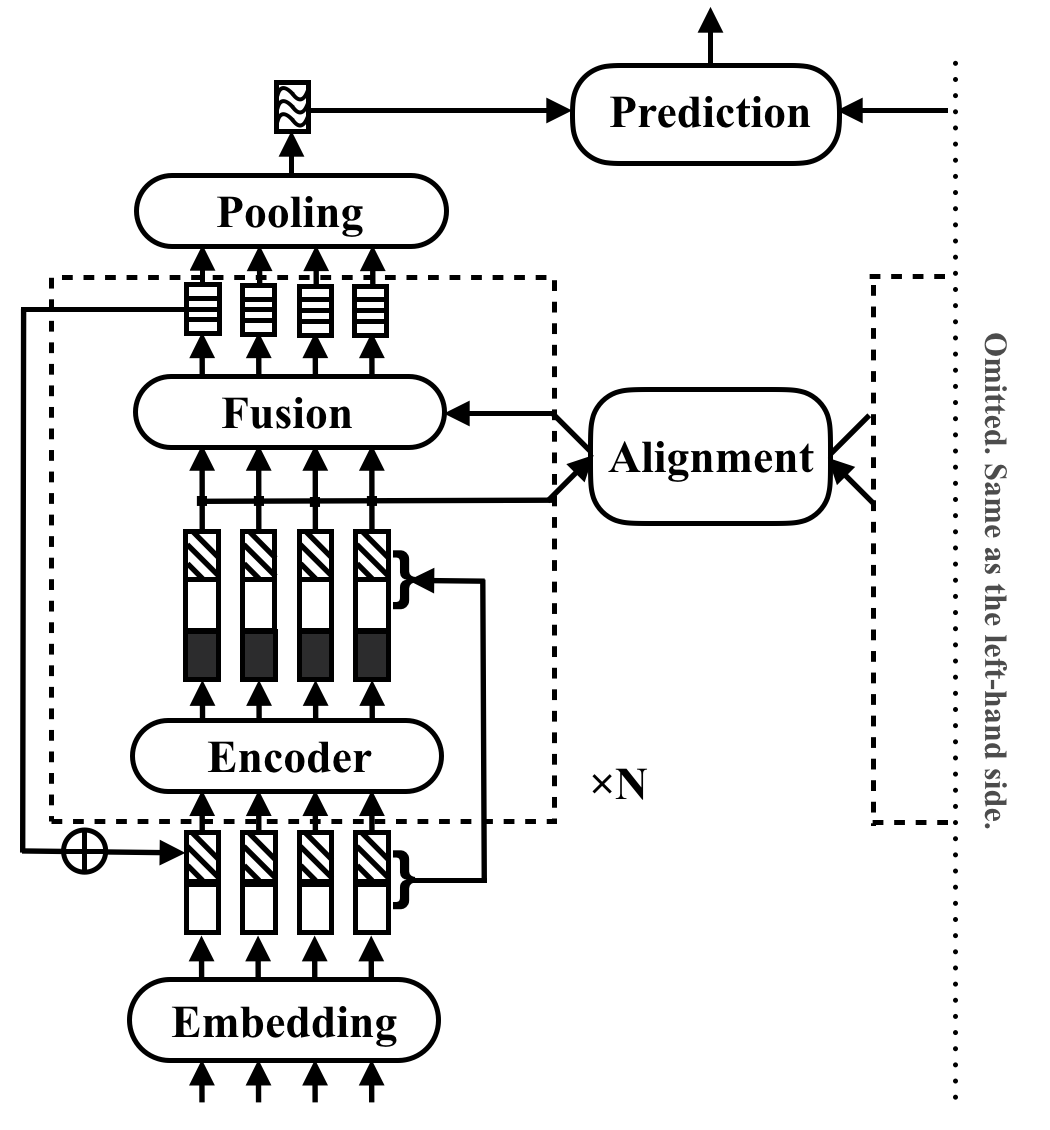
RE2 - быстрая и сильная нейронная архитектура для приложений для сопоставления текста общего назначения. В задаче сопоставления текста модель принимает две текстовые последовательности в качестве ввода и предсказывает их отношения. Этот метод направлен на изучение того, что достаточно для сильной работы в этих задачах. Он упрощает или пропускает много медленных компонентов, которые ранее рассматриваются как основные строительные блоки в соответствии с текстами. Он достигает своей производительности с помощью простой идеи, которая сохраняет три ключевые функции, непосредственно доступные для выравнивания и слияния между последовательностью: предыдущие выравниваемые функции ( Residual Vectors), исходные точечные функции ( E Mbedding Vectors) и контекстные функции ( Encoder Вывод).
RE2 достигает производительности на норме с состоянием искусства на четырех наборах данных: SNLI, Scitail, Quora и Wikiqa, по задачам вывода естественного языка, перефразировать идентификацию и выбор ответов без каких-либо или небольших специфических для задачи адаптации. Он имеет по меньшей мере в 6 раз быстрее скорость вывода по сравнению с аналогичными моделями.
В следующей таблице перечислены основные результаты эксперимента. В статье сообщается о среднем и стандартном отклонении 10 прогонов, и результаты могут быть легко воспроизведены. Время вывода (в секундах) измеряется путем обработки партии из 8 пар длины 20 на процессорах Intel I7. Время вычисления функций POS, используемых CSRAN и DIIN, не включено.
| Модель | Snli | Scitail | Quora | Викика | Время вывода |
|---|---|---|---|---|---|
| Бимпм | 86.9 | - | 88.2 | 0,731 | 0,05 |
| Эсим | 88.0 | 70.6 | - | - | - |
| Диин | 88.0 | - | 89.1 | - | 1.79 |
| CSRAN | 88.7 | 86.7 | 89,2 | - | 0,28 |
| Re2 | 88,9 ± 0,1 | 86,0 ± 0,6 | 89,2 ± 0,2 | 0,7618 ± 0,0040 | 0,03 ~ 0,05 |
Обратитесь к статье для получения более подробной информации о компонентах и результатах эксперимента.
pip install -r requirements.txtresources/Данные, используемые в статье, подготовлены следующим образом:
data/orig .cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig .cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig .cd data && python prepare_wikiqa.pymake -B , чтобы скомпилировать исходные файлы в qg-emnlp07-data/eval/trec_eval-8.0 . Переместите двоичный файл «trec_eval» в resources/ . Чтобы обучить новую модель соответствия текста, запустите следующую команду:
python train.py $config_file .json5 Примеры файлов конфигурации приведены в configs/ :
configs/main.json5 : повторите основной эксперимент результат в статье.configs/robustness.json5 : проверки надежностиconfigs/ablation.json5 : исследование абляцииИнструкции по написанию собственных файлов конфигурации:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]Чтобы проверить только конфигурации, используйте
python train.py $config_file .json5 --dryПожалуйста, цитируйте бумагу ACL, если вы используете RE2 в своей работе:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
RE2 находится под лицензией Apache 2.0.


