simple effective text matching
1.0.0
Dies ist die ursprüngliche Tensorflow -Implementierung des ACL 2019 -Papiers einfachen und effektiven Textabgleich mit reicheren Ausrichtungsfunktionen. Pytorch-Implementierung: https://github.com/alibaba-edu/simple-effective-text-matching-pytorch.
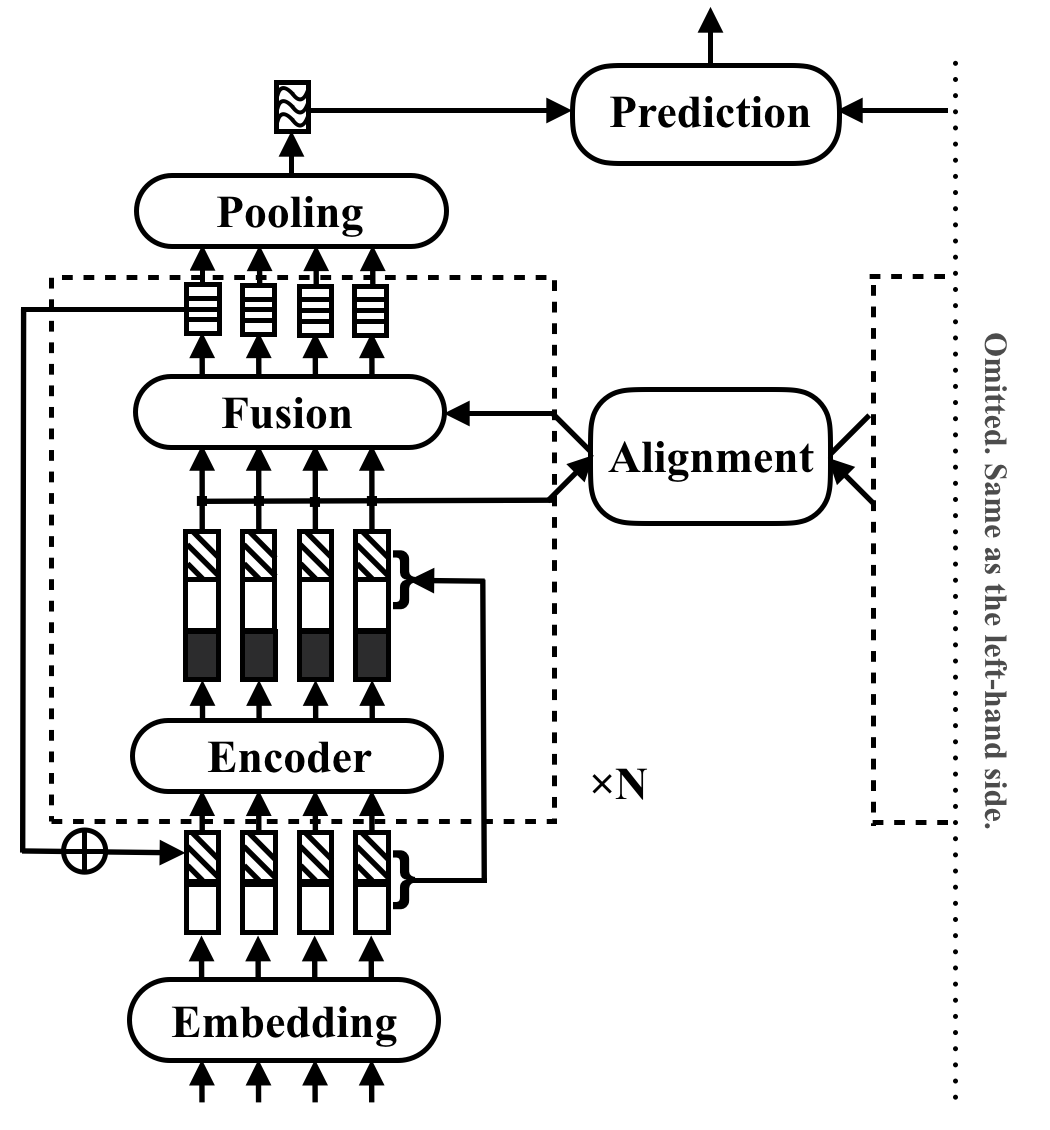
RE2 ist eine schnelle und starke neuronale Architektur für allgemeine Textanwendungen. In einer textübergreifenden Aufgabe nimmt ein Modell zwei Textsequenzen als Eingabe auf und prognostiziert ihre Beziehung. Diese Methode zielt darauf ab, zu untersuchen, was für eine starke Leistung bei diesen Aufgaben ausreicht. Es vereinfacht oder lässt viele langsame Komponenten, die zuvor als Kernbausteine im Textanpassung angesehen werden. Es erzielt seine Leistung durch eine einfache Idee, bei der drei wichtige Funktionen direkt für die Ausrichtung und Fusion von Sequence verfügbar sind: frühere ausgerichtete Merkmale ( residuelle Vektoren), ursprüngliche Punktfunktionen ( E- Mbedding-Vektoren) und Kontextfunktionen ( E -NCODER-Ausgabe).
RE2 erreicht die Leistung mit dem Stand der Technik auf vier Benchmark-Datensätzen: SNLI, Scitail, Quora und Wikiqa über Aufgaben der Inferenz für natürliche Sprache, die Identifizierung und die Beantwortung der Auswahl ohne oder nur wenige aufgabenspezifische Anpassungen. Es hat mindestens 6 -mal schneller Inferenzgeschwindigkeit im Vergleich zu ähnlich durchgeführten Modellen.
In der folgenden Tabelle werden wichtige Experimentergebnisse aufgeführt. Das Papier berichtet über die Durchschnitts- und Standardabweichung von 10 Läufen und die Ergebnisse können leicht reproduziert werden. Die Inferenzzeit (in Sekunden) wird durch Verarbeitung einer Stapel von 8 Längepaaren 20 auf Intel i7 -CPUs gemessen. Die Berechnungszeit von POS -Funktionen, die von CSRAN und Diin verwendet werden, ist nicht enthalten.
| Modell | Snli | Scitail | Quora | Wikiqa | Inferenzzeit |
|---|---|---|---|---|---|
| Bimpm | 86,9 | - - | 88.2 | 0,731 | 0,05 |
| Essim | 88.0 | 70,6 | - - | - - | - - |
| Diin | 88.0 | - - | 89.1 | - - | 1.79 |
| CSRAN | 88.7 | 86,7 | 89,2 | - - | 0,28 |
| Re2 | 88,9 ± 0,1 | 86,0 ± 0,6 | 89,2 ± 0,2 | 0,7618 ± 0,0040 | 0,03 ~ 0,05 |
Weitere Informationen zu den Komponenten und Versuchsergebnissen finden Sie in der Arbeit.
pip install -r requirements.txtresources/Die im Papier verwendeten Daten werden wie folgt erstellt:
data/orig .cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig .cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig .cd data && python prepare_wikiqa.pymake -B , um die Quelldateien in qg-emnlp07-data/eval/trec_eval-8.0 zu kompilieren. Verschieben Sie die Binärdatei "Trec_eval" in resources/ . Führen Sie den folgenden Befehl aus, um ein neues Text -Matching -Modell zu trainieren:
python train.py $config_file .json5 Beispielkonfigurationsdateien finden Sie in configs/ :
configs/main.json5 : replizieren Sie das Hauptexperiment resultieren im Papier.configs/robustness.json5 : Robustheitprüfungenconfigs/ablation.json5 : AblationsstudieDie Anweisungen zum Schreiben Ihrer eigenen Konfigurationsdateien:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]Verwenden Sie nur die Konfigurationen, um nur die Konfigurationen zu überprüfen
python train.py $config_file .json5 --dryBitte zitieren Sie das ACL -Papier, wenn Sie RE2 in Ihrer Arbeit verwenden:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
RE2 befindet sich unter Apache -Lizenz 2.0.


