simple effective text matching
1.0.0
هذا هو تنفيذ TensorFlow الأصلي لورقة ACL 2019 التي تتطابق مع نص النص البسيط والفعال مع ميزات المحاذاة الأكثر ثراءً. تطبيق Pytorch: https://github.com/alibaba-edu/simple-effective-text-matching-pytorch.
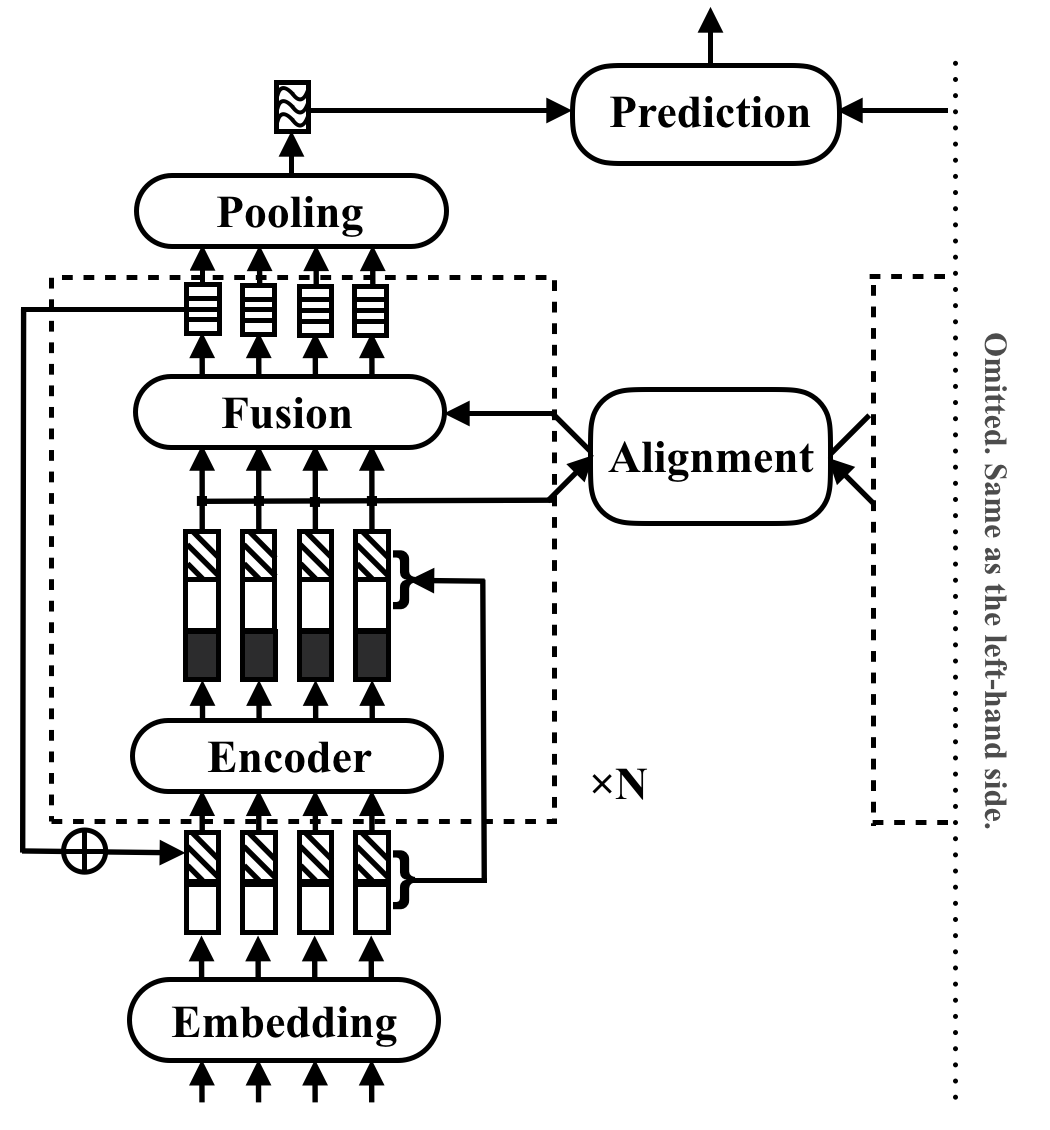
RE2 هي بنية عصبية سريعة وقوية لتطبيقات المطابقة للأغراض العامة. في مهمة مطابقة النص ، يأخذ النموذج تسلسل نصين كمدخلين ويتوقع علاقتهما. تهدف هذه الطريقة إلى استكشاف ما هو كافٍ للأداء القوي في هذه المهام. إنه يبسط أو يحذف العديد من المكونات البطيئة التي تعتبر سابقًا كتلًا أساسيًا في مطابقة النص. إنه يحقق أدائها من خلال فكرة بسيطة ، والتي تحافظ على ثلاث ميزات رئيسية متاحة مباشرة لمحاذاة وتسلسل التسجيل: الميزات المحاذاة السابقة (متجهات الإزيائية ) ، والميزات الأصلية النقطية (ناقلات e mbedding) ، والميزات السياقية (إخراج e ncoder).
يحقق RE2 الأداء على قدم المساواة مع أحدث مجموعات البيانات القياسية: SNLI و Scitail و Quora و Wikiqa ، عبر مهام استنتاج اللغة الطبيعية ، وتحديد التعيينات واختيار الإجابة مع عدم وجود تعديلات خاصة بالمهمة. لديها ما لا يقل عن 6 مرات سرعة الاستدلال مقارنة مع النماذج التي يتم تنفيذها بالمثل.
يسرد الجدول التالي نتائج التجربة الرئيسية. تشير الورقة إلى أن المتوسط والانحراف المعياري لـ 10 أشواط ويمكن استنساخ النتائج بسهولة. يتم قياس وقت الاستدلال (بالثواني) عن طريق معالجة مجموعة من 8 أزواج من الطول 20 على وحدة المعالجة المركزية Intel i7. لم يتم تضمين وقت حساب ميزات POS المستخدمة من قبل CSRAN و DIIN.
| نموذج | سنلي | Scitail | Quora | ويكيكا | وقت الاستنتاج |
|---|---|---|---|---|---|
| bimpm | 86.9 | - | 88.2 | 0.731 | 0.05 |
| esim | 88.0 | 70.6 | - | - | - |
| ديين | 88.0 | - | 89.1 | - | 1.79 |
| CSRAN | 88.7 | 86.7 | 89.2 | - | 0.28 |
| RE2 | 88.9 ± 0.1 | 86.0 ± 0.6 | 89.2 ± 0.2 | 0.7618 ± 0.0040 | 0.03 ~ 0.05 |
ارجع إلى الورقة لمزيد من التفاصيل عن المكونات ونتائج التجربة.
pip install -r requirements.txtresources/يتم إعداد البيانات المستخدمة في الورقة على النحو التالي:
data/orig .cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig .cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig .cd data && python prepare_wikiqa.pymake -B لتجميع الملفات المصدر في qg-emnlp07-data/eval/trec_eval-8.0 . انقل الملف الثنائي "TREC_EVAL" إلى resources/ . لتدريب نموذج جديد لمطابقة النص ، قم بتشغيل الأمر التالي:
python train.py $config_file .json5 يتم توفير مثال ملفات التكوين في configs/ :
configs/main.json5 : تكرار التجربة الرئيسية نتيجة الورقة.configs/robustness.json5 : فحوصات المتانةconfigs/ablation.json5 : دراسة الاجتثاثالتعليمات لكتابة ملفات التكوين الخاصة بك:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]للتحقق من التكوينات فقط ، استخدم
python train.py $config_file .json5 --dryيرجى استشهاد ورقة ACL إذا كنت تستخدم RE2 في عملك:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
RE2 تحت رخصة Apache 2.0.


