simple effective text matching
1.0.0
Ini adalah implementasi TensorFlow asli dari kertas ACL 2019 yang cocok dengan teks sederhana dan efektif dengan fitur perataan yang lebih kaya. Implementasi PyTorch: https://github.com/alibaba-edu/simple-Effective-text-matching-pytorch.
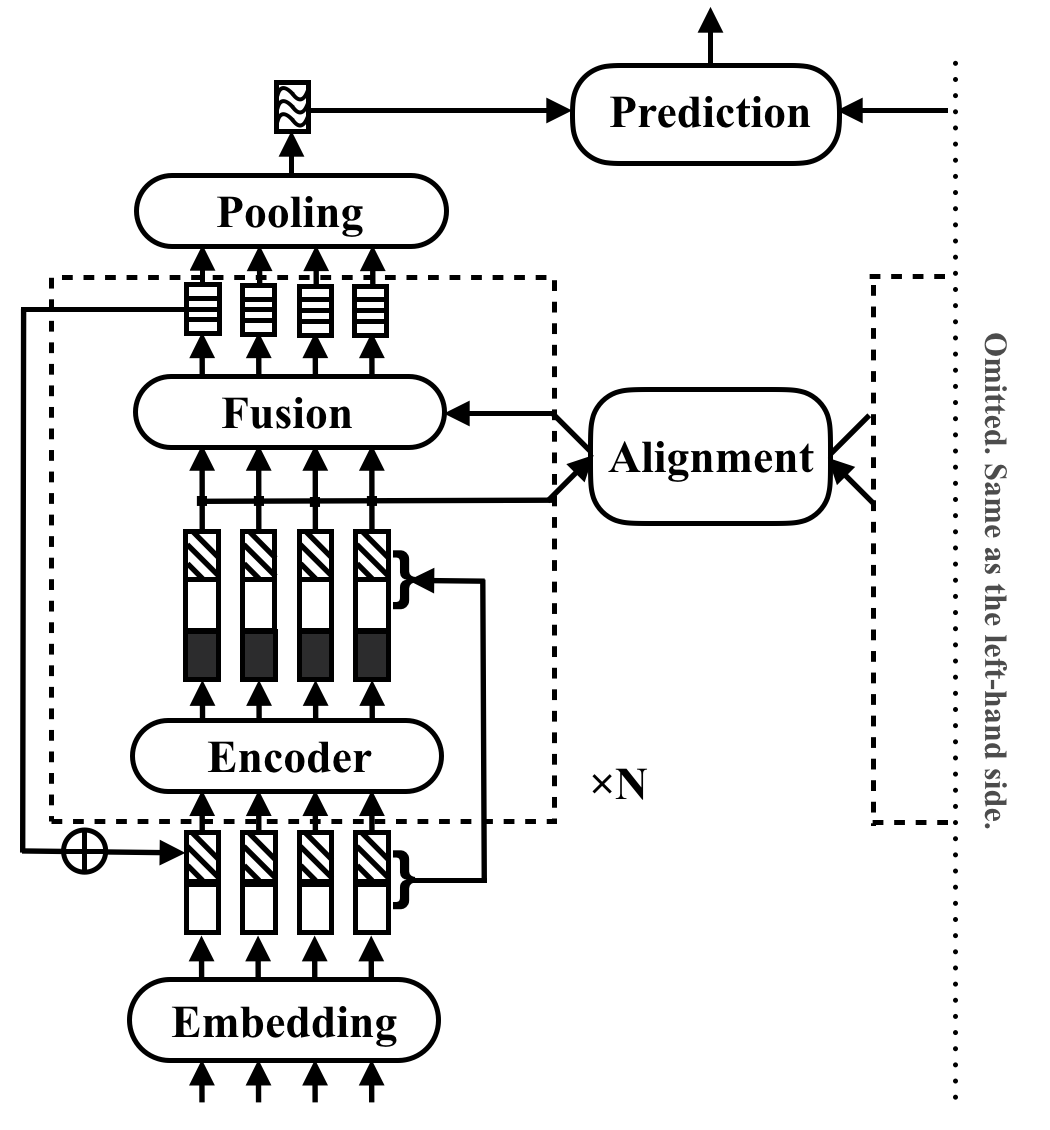
RE2 adalah arsitektur saraf yang cepat dan kuat untuk aplikasi pencocokan teks tujuan umum. Dalam tugas pencocokan teks, model mengambil dua urutan teks sebagai input dan memprediksi hubungan mereka. Metode ini bertujuan untuk mengeksplorasi apa yang cukup untuk kinerja yang kuat dalam tugas -tugas ini. Ini menyederhanakan atau menghilangkan banyak komponen lambat yang sebelumnya dianggap sebagai blok bangunan inti dalam pencocokan teks. Ini mencapai kinerjanya dengan ide sederhana, yang menjaga tiga fitur utama tersedia secara langsung untuk penyelarasan dan fusi inter-urutan: fitur yang disejajarkan sebelumnya (vektor r esidual), fitur point-wise asli (vektor e mbedding), dan fitur kontekstual ( e ncoder output).
RE2 mencapai kinerja yang setara dengan canggih pada empat dataset benchmark: SNLI, Scitail, Quora dan Wikiqa, di seluruh tugas inferensi bahasa alami, identifikasi parafrase dan seleksi jawaban tanpa atau sedikit adaptasi khusus tugas. Ini memiliki setidaknya 6 kali kecepatan inferensi lebih cepat dibandingkan dengan model yang dilakukan dengan cara yang sama.
Tabel berikut mencantumkan hasil percobaan utama. Makalah ini melaporkan rata -rata dan standar deviasi 10 run dan hasilnya dapat dengan mudah direproduksi. Waktu inferensi (dalam detik) diukur dengan memproses batch 8 pasang panjang 20 pada CPU Intel I7. Waktu perhitungan fitur POS yang digunakan oleh CSRAN dan DIIN tidak termasuk.
| Model | Snli | Scitail | Quora | Wikiqa | Waktu kesimpulan |
|---|---|---|---|---|---|
| Bimpm | 86.9 | - | 88.2 | 0.731 | 0,05 |
| Esim | 88.0 | 70.6 | - | - | - |
| Diin | 88.0 | - | 89.1 | - | 1.79 |
| Csran | 88.7 | 86.7 | 89.2 | - | 0.28 |
| RE2 | 88,9 ± 0,1 | 86,0 ± 0,6 | 89,2 ± 0,2 | 0,7618 ± 0,0040 | 0,03 ~ 0,05 |
Lihat makalah untuk lebih detail komponen dan hasil percobaan.
pip install -r requirements.txtresources/Data yang digunakan dalam makalah disiapkan sebagai berikut:
data/orig .cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig .cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig .cd data && python prepare_wikiqa.pymake -B untuk mengkompilasi file sumber di qg-emnlp07-data/eval/trec_eval-8.0 . Pindahkan file biner "trec_eval" ke resources/ . Untuk melatih model pencocokan teks baru, jalankan perintah berikut:
python train.py $config_file .json5 Contoh file konfigurasi disediakan di configs/ :
configs/main.json5 : Replikasi hasil percobaan utama di kertas.configs/robustness.json5 : Pemeriksaan Kokohconfigs/ablation.json5 : studi ablasiInstruksi untuk menulis file konfigurasi Anda sendiri:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]Untuk memeriksa konfigurasi saja, gunakan
python train.py $config_file .json5 --dryHarap kutip kertas ACL jika Anda menggunakan RE2 dalam pekerjaan Anda:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
RE2 berada di bawah Lisensi Apache 2.0.


