linked list good taste
1.0.0
在2016年的TED采访(14:10)中,Linus Torvalds谈到了他认为编码的良好品味。例如,他在单链接列表中提出了两个项目删除的实现(以下复制)。为了从列表中删除第一个项目,其中一个实现需要特殊情况,另一个实施情况不需要。显然,Linus更喜欢后者。
他的评论是:
[...]我不想让您理解为什么它没有if语句。但是我希望您理解,有时您可以以不同的方式看到一个问题并重写它,以使特殊情况消失并成为正常情况,这是很好的代码。 [...] - L. Torvalds
他提供的代码片段是C风格的伪代码,并且足够简单。但是,正如Linus在评论中提到的那样,片段缺乏概念上的解释,并且尚不明显更优雅的解决方案的实际运作方式。
接下来的两个部分详细介绍了技术方法,并演示了间接寻址方法的方式以及为什么如此整洁。最后一节将解决方案从项目删除到插入。
整数列表的基本数据结构如图1所示。

图1 :整数列表。
数字是任意选择的整数值和箭头指示指示器。 head是类型list_item *的指针,每个框都是list_item struct的实例,每个框都带有构件变量(在代码中称为next )type list_item * ,指向下一个项目。
数据结构的C实施是:
struct list_item {
int value ;
struct list_item * next ;
};
typedef struct list_item list_item ;
struct list {
struct list_item * head ;
};
typedef struct list list ;我们还包括(最小)API:
/* The textbook version */
void remove_cs101 ( list * l , list_item * target );
/* A more elegant solution */
void remove_elegant ( list * l , list_item * target );将其实现,让我们看一下remove_cs101()和remove_elegant()的实现。这些示例的代码符合Linus示例中的伪代码以及编译和运行。
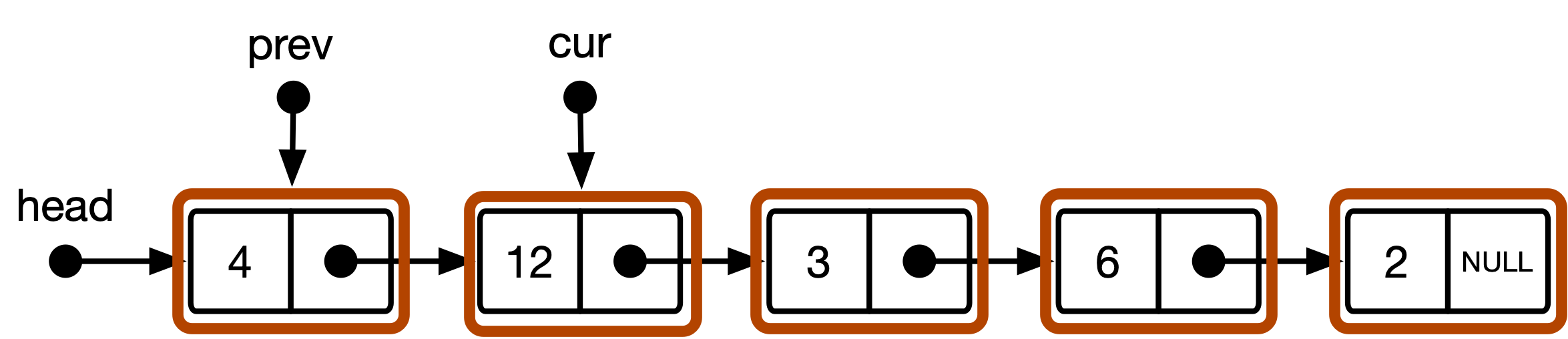
图2 :CS101算法中列表数据结构的概念模型。
void remove_cs101 ( list * l , list_item * target )
{
list_item * cur = l -> head , * prev = NULL ;
while ( cur != target ) {
prev = cur ;
cur = cur -> next ;
}
if ( prev )
prev -> next = cur -> next ;
else
l -> head = cur -> next ;
}标准的CS101方法利用了两个遍历指针cur和prev ,分别标记了列表中的当前和先前的遍历位置。 cur始于列表head ,然后前进,直到找到目标为止。 prev从NULL开始,随后每次cur Advances cur的先前值都会更新。找到目标后,算法测试如果prev为非NULL 。如果是,则该项目不在列表的开头,删除包括重新列出cur围绕的链接列表。如果prev为NULL , cur指向列表中的第一个元素,在这种情况下,删除意味着将列表向前移动。
更优雅的版本的代码较少,并且不需要单独的分支来处理列表中第一个元素的删除。
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
* p = target -> next ;
}该代码使用间接指针p ,该指针p从head地址开始,该指针P指向列表项目的地址。在每次迭代中,指针都将要保存指针的下一个列表项目的地址,即当前list_item中next元素的地址。当指向列表项目*p等于target时,我们将退出搜索循环并从列表中删除该项目。
关键见解是,使用间接指针p具有两个概念上的好处:
head指针成为数据结构不可或缺的一部分的方式来解释链接列表。这消除了特殊情况以删除第一项的需求。while循环的状况,而不必放开target的指针。这使我们能够修改指向target的指针,并逃脱单个迭代器,而不是prev和cur 。让我们依次看看这些要点。
head指针标准模型将链接列表解释为list_item实例的序列。可以通过head指针访问序列的开始。这导致了上面图2所示的概念模型。 head指针仅被视为访问列表开始的处理方法。 prev和cur是类型list_item *的指针,始终指向项目或NULL 。
优雅的实施使用间接的寻址方案,对数据结构产生不同的看法:
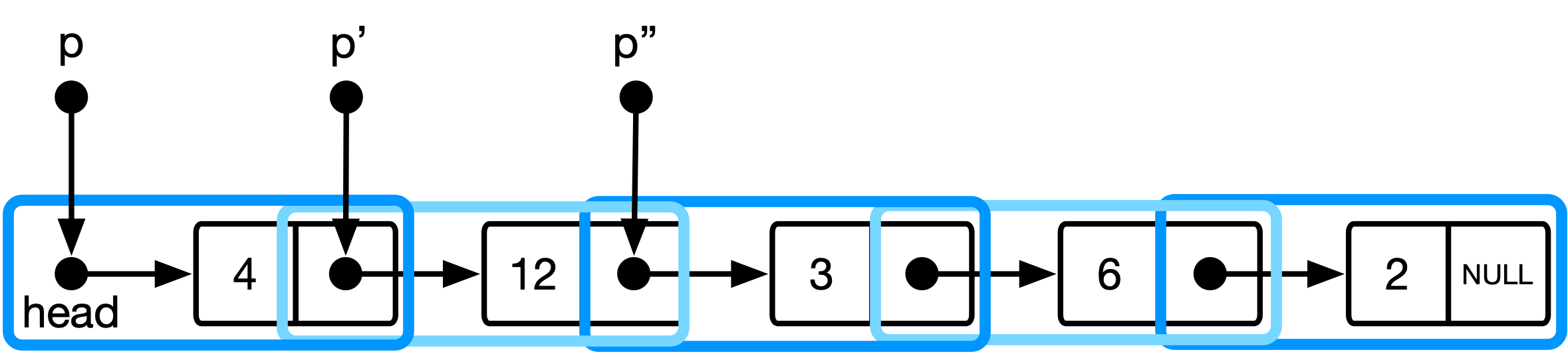
图3 :更优雅的方法中列表数据结构的概念模型。
在这里, p是类型list_item ** ,并保留指向当前列表项目的指针的地址。当我们推进指针时,我们将指针的地址转发到下一个列表项目的地址。
在代码中,这转化为p = &(*p)->next ,意味着我们
(*p) :取消指向当前列表项目的指针的地址->next :再次取消指针,然后选择保留下一个列表项目地址的字段& :获取该地址字段的地址(即获取指针)这对应于数据结构的解释,其中列表是list_item s的一系列指针(参见图3)。
该特定解释的另一个好处是,它支持在整个遍历中编辑当前项目的前身的next指针。
p持有指向列表项目的指针的地址,搜索循环中的比较变为
while ( * p != target )如果*p等于target ,则搜索循环将退出,一旦达到目标,我们仍然能够修改*p ,因为我们持有其地址p 。因此,尽管迭代循环直到达到target ,但我们仍然维护一个手柄( next字段或head指针的地址),该手柄可用于直接修改指向项目的指针。
这就是为什么我们可以使用*p = target->next指向其他位置的输入指针的原因,以及为什么我们不需要prev和cur来穿越列表以删除项目。
事实证明,可以应用remove_elegant()背后的想法来产生列表API中另一个函数的特别简洁实现: insert_before() ,即在另一个项目之前插入给定项目。
首先,让我们将以下声明添加到list.h中的列表API。
void insert_before ( list * l , list_item * before , list_item * item );该函数将在该列表中的项目before将指针转到列表l ,并在该列表中的项目中进行指针,并将其指向该功能之前将在before插入的新列表item 。
在继续前进之前,我们将搜索循环重构为单独的功能
static inline list_item * * find_indirect ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
return p ;
}并在remove_elegant()中使用该功能
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = find_indirect ( l , target );
* p = target -> next ;
}insert_before()使用find_indirect() ,实现insert_before() :
void insert_before ( list * l , list_item * before , list_item * item )
{
list_item * * p = find_indirect ( l , before );
* p = item ;
item -> next = before ;
}一个特别优美的结果是,实现对边缘情况具有一致的语义:如果在列表before指向列表头,则新项目将在列表的开头插入,如果before是NULL或无效的(即该项目不存在于l中),则新项目将在最后应用。
项目删除更优雅的解决方案的前提是一个简单的更改:使用间接的list_item **指针指向列表项目的指针。其他一切都从那里流动:不需要特殊情况或分支,并且单个迭代器足以找到和删除目标项目。事实证明,相同的方法为一般的项目插入提供了优雅的解决方案,尤其是在现有项目之前插入。
因此,回到Linus的最初评论:它的味道好吗?很难说,但这肯定是众所周知的CS任务的一种不同,创造性且非常优雅的解决方案。


