linked list good taste
1.0.0
2016 년 TED 인터뷰 (14:10)에서 Linus Torvalds는 코딩에서 좋은 맛을 고려하는 것에 대해 이야기합니다. 예를 들어, 그는 단일 링크 된 목록에서 아이템 제거의 두 가지 구현을 제시합니다 (아래 재생). 목록에서 첫 번째 항목을 제거하려면 구현 중 하나에는 특별한 경우가 필요하며 다른 하나는 그렇지 않습니다. Linus는 분명히 후자를 선호합니다.
그의 의견은 다음과 같습니다.
[...] 왜 IF 진술이 없는지 이해하기를 원하지 않습니다. 그러나 때때로 다른 방식으로 문제를보고 다시 작성하여 특별한 경우가 사라지고 정상적인 경우가되기를 바랍니다. 좋은 코드 입니다. [...] - L. Torvalds
그가 제시하는 코드 스 니펫은 C 스타일의 의사 코드이며 따라갈 수있을 정도로 간단합니다. 그러나 Linus가 의견에서 언급했듯이 스 니펫에는 개념적 설명이 부족하며 더 우아한 솔루션이 실제로 어떻게 작동하는지 명백하지는 않습니다.
다음 두 섹션은 기술적 접근 방식을 자세히 살펴보고 간접 주소 지정 접근 방식이 어떻게 깔끔한지를 보여줍니다. 마지막 섹션은 솔루션을 항목 삭제에서 삽입으로 확장합니다.
단일 링크 된 정수 목록의 기본 데이터 구조는 그림 1에 나와 있습니다.

그림 1 : 단독으로 연결된 정수 목록.
숫자는 임의로 선택된 정수 값을 선택하고 화살표는 포인터를 나타냅니다. head 는 유형 list_item * 의 포인터이며 각 상자는 list_item Struct의 인스턴스이며, 각각은 다음 항목을 가리키는 유형 list_item * 의 멤버 변수 (코드에서 next 코드로 불림)를 갖습니다.
데이터 구조의 C 구현은 다음과 같습니다.
struct list_item {
int value ;
struct list_item * next ;
};
typedef struct list_item list_item ;
struct list {
struct list_item * head ;
};
typedef struct list list ;우리는 또한 (최소) API를 포함합니다.
/* The textbook version */
void remove_cs101 ( list * l , list_item * target );
/* A more elegant solution */
void remove_elegant ( list * l , list_item * target ); 이를 통해 remove_cs101() 및 remove_elegant() 의 구현을 살펴 보겠습니다. 이 예제의 코드는 Linus 예제의 의사 코드에 충실하며 컴파일 및 실행됩니다.
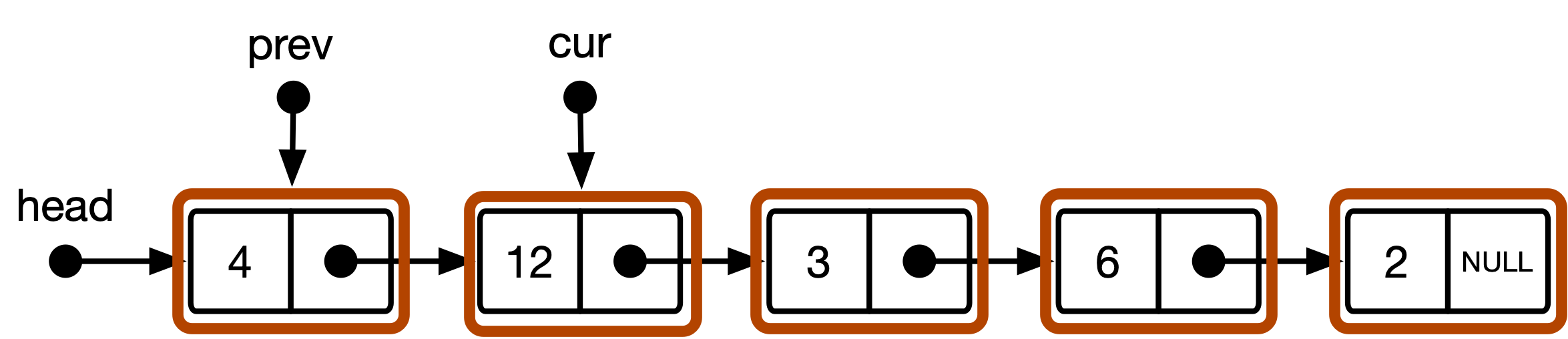
그림 2 : CS101 알고리즘의 목록 데이터 구조에 대한 개념 모델.
void remove_cs101 ( list * l , list_item * target )
{
list_item * cur = l -> head , * prev = NULL ;
while ( cur != target ) {
prev = cur ;
cur = cur -> next ;
}
if ( prev )
prev -> next = cur -> next ;
else
l -> head = cur -> next ;
} 표준 CS101 접근법은 2 개의 트래버스 포인터 cur 및 prev 사용하여 각각 목록의 현재 및 이전 트래버스 위치를 표시합니다. cur 목록 헤드 head 에서 시작하여 대상이 발견 될 때까지 발전합니다. prev NULL 에서 시작하여 cur 발전 할 때마다 cur 의 이전 값으로 업데이트됩니다. 대상을 찾은 후에는 prev NULL 아닌 경우 알고리즘이 테스트됩니다. 그렇다면, 항목은 목록의 시작 부분에 있지 않으며 제거는 cur 주변의 링크 된 목록을 다시 라우팅하는 것으로 구성됩니다. prev 이 NULL 이면 cur 목록의 첫 번째 요소를 가리키며,이 경우 제거는 목록을 앞으로 이동하는 것을 의미합니다.
더 우아한 버전은 코드가 적으며 목록에서 첫 번째 요소를 삭제하기 위해 별도의 분기가 필요하지 않습니다.
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
* p = target -> next ;
} 코드는 head 주소부터 시작하여 목록 항목에 대한 포인터 주소를 보유하는 간접 포인터 p 사용합니다. 모든 반복에서, 해당 포인터는 다음 목록 항목에 대한 포인터의 주소, 즉 현재 list_item 의 next 요소의 주소를 고정하도록 고급됩니다. 목록 항목 *p 에 대한 포인터가 target 과 같으면 검색 루프를 종료하고 목록에서 항목을 제거합니다.
주요 통찰력은 간접 포인터 p 사용하는 데 두 가지 개념적 이점이 있다는 것입니다.
head 포인터를 데이터 구조에 필수 부분으로 만드는 방식으로 해석 할 수 있습니다. 이렇게하면 첫 번째 항목을 제거 할 특별한 경우가 필요하지 않습니다.target 을 가리키는 포인터를 놓지 않고도 while 루프 조건을 평가할 수 있습니다. 이를 통해 target 가리키고 prev 및 cur 아닌 단일 반복자로 도망 갈 수있는 포인터를 수정할 수 있습니다.이 각 점을 차례로 보자.
head 포인터 통합 표준 모델은 링크 된 목록을 list_item 인스턴스의 시퀀스로 해석합니다. 시퀀스의 시작은 head 포인터를 통해 액세스 할 수 있습니다. 이것은 위의 그림 2에 설명 된 개념적 모델로 이어진다. head 포인터는 단지 목록의 시작에 액세스하기위한 핸들로 간주됩니다. prev and cur list_item * 유형의 포인터이며 항상 항목이나 NULL 가리 킵니다.
우아한 구현은 데이터 구조에 대한 다른보기를 산출하는 간접 주소 지정 체계를 사용합니다.
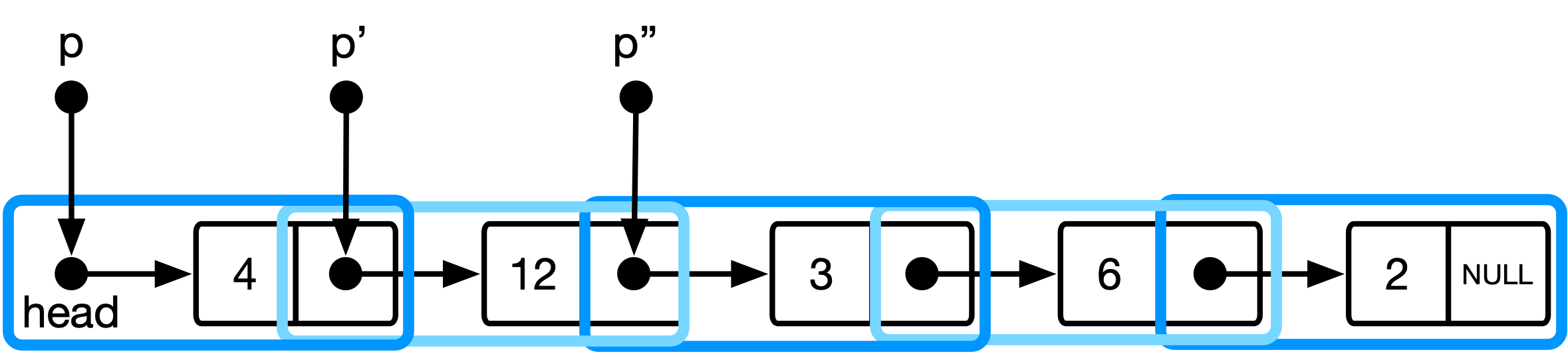
그림 3 :보다 우아한 접근법에서 목록 데이터 구조에 대한 개념적 모델.
여기서 p 는 list_item ** 유형이며 현재 목록 항목에 대한 포인터의 주소를 보유합니다. 포인터를 발전 시키면 다음 목록 항목에 대한 포인터의 주소로 전달됩니다.
코드에서 이것은 p = &(*p)->next 변환됩니다.
(*p) : 현재 목록 항목에 대한 포인터에 대한 주소를 해석합니다.->next : Pointer의 Derefence Again과 다음 목록 항목의 주소를 보유하는 필드를 선택하십시오.& : 그 주소 필드의 주소를 가져 가십시오 (즉, 포인터를 얻으십시오) 이것은 목록이 list_item S에 대한 일련의 포인터 인 데이터 구조의 해석에 해당합니다 (그림 3).
이러한 특정 해석의 추가 이점은 전체 트래버스에서 현재 항목의 전임자의 next 포인터 편집을 지원한다는 것입니다.
p 목록 항목에 대한 포인터의 주소를 보유하면 검색 루프의 비교가됩니다.
while ( * p != target ) 검색 루프는 *p target 과 같으면 종료되며, 일단 그렇게하면 주소 p 유지하기 때문에 여전히 *p 수정할 수 있습니다. 따라서 target 때릴 때까지 루프를 반복하더라도, 우리는 여전히 항목 을 가리키는 포인터를 직접 수정하는 데 사용할 수있는 핸들 ( next 필드의 주소 또는 head 포인터)을 유지합니다.
이것이 *p = target->next 사용하여 다른 위치를 가리키기 위해 항목에 대한 들어오는 포인터를 수정할 수있는 이유이며, 항목 제거를 위해 목록을 가로 지르기 위해 prev 및 cur 포인터가 필요하지 않은 이유입니다.
remove_elegant() 의 아이디어는 목록 API : insert_before() 에서 다른 함수의 특히 간결한 구현을 생성하기 위해 적용될 수 있으며, 즉 다른 항목 앞에 주어진 항목을 삽입하는 것입니다.
먼저 list.h : List API에 다음 선언을 추가하겠습니다.
void insert_before ( list * l , list_item * before , list_item * item ); 이 함수는 목록 l 에 대한 포인터, 해당 목록의 항목에 before 포인터, before 에 기능이 삽입 할 새 목록 item 에 대한 포인터를 사용합니다.
계속 진행하기 전에 검색 루프를 별도의 기능으로 리팩터링합니다.
static inline list_item * * find_indirect ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
return p ;
} 그리고 그 함수를 remove_elegant() 처럼 사용하십시오
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = find_indirect ( l , target );
* p = target -> next ;
}insert_before() 구현 find_indirect() 사용하면 insert_before() 구현하는 것이 간단합니다.
void insert_before ( list * l , list_item * before , list_item * item )
{
list_item * * p = find_indirect ( l , before );
* p = item ;
item -> next = before ;
} 특히 아름다운 결과는 구현이 Edge Case에 대한 일관된 의미를 가지고 있다는 것입니다. 목록 NULL 를 가리 before before 목록 시작 l 에 새 항목이 삽입됩니다.
항목 삭제를위한보다 우아한 솔루션의 전제는 단일의 간단한 변경입니다. 간접 list_item ** 포인터를 사용하여 포인터를 목록 항목으로 반복합니다. 다른 모든 것은 거기에서 흘러 나옵니다. 특별한 케이스 나 분기가 필요하지 않으며 단일 반복기는 대상 항목을 찾고 제거하기에 충분합니다. 또한 동일한 접근법은 일반적으로 품목 삽입 및 특히 기존 항목 이전에 삽입을위한 우아한 솔루션을 제공한다는 것이 밝혀졌습니다.
그래서 Linus의 초기 의견으로 돌아가는 것 : 좋은 취향입니까? 말하기는 어렵지만 잘 알려진 CS 과제에 대한 다르고 창의적이며 매우 우아한 솔루션입니다.


