linked list good taste
1.0.0
في مقابلة TED لعام 2016 (14:10) يتحدث Linus Torvalds عما يعتبره ذوقًا جيدًا في الترميز. على سبيل المثال ، يقدم تطبيقين لإزالة العناصر في قوائم مرتبطة منفردة (مستنسخة أدناه). من أجل إزالة العنصر الأول من قائمة ، يتطلب أحد التطبيقات حالة خاصة ، والآخر لا. لينوس ، من الواضح ، يفضل الأخير.
تعليقه هو:
[...] لا أريدك أن تفهم سبب عدم وجود بيان if. لكنني أريدك أن تفهم أنه في بعض الأحيان يمكنك رؤية مشكلة بطريقة مختلفة وإعادة كتابتها حتى تختفي حالة خاصة وتصبح الحالة العادية ، وهذا رمز جيد . [...] - L. Torvalds
قصاصات الكود التي يقدمها هي رمز كاذب على غرار C وبساطة بما يكفي لمتابعة. ومع ذلك ، كما يذكر Linus في التعليق ، تفتقر القصاصات إلى تفسير مفاهيمي وليس من الواضح على الفور كيف يعمل الحل الأكثر أناقة بالفعل.
يبحث القسمان التاليان في النهج الفني بالتفصيل ويوضحون كيف ولماذا نهج المعالجة غير المباشر أنيق للغاية. يمتد القسم الأخير الحل من حذف العنصر إلى الإدراج.
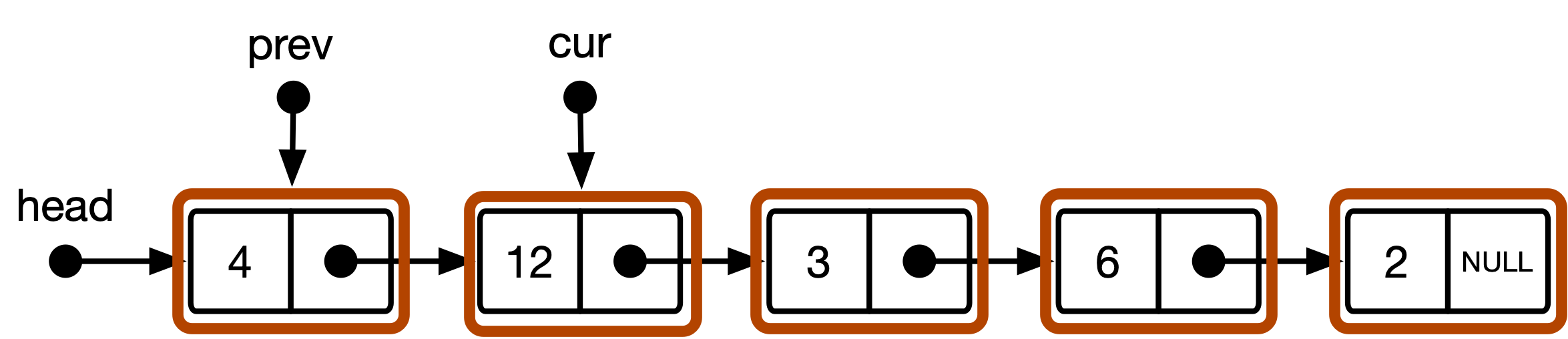
يوضح الشكل 1 بنية البيانات الأساسية لقائمة من أعداد صحيحة منفردة.

الشكل 1 : قائمة المرتبطة المنفردة من الأعداد الصحيحة.
يتم اختيار الأرقام التي يتم اختيارها بشكل تعسفي قيم وسباق عدد صحيح وتشير الأسهم إلى مؤشرات. head هو مؤشر من النوع list_item * وكل مربع هو مثيل لهيكل list_item ، ولكل منهما متغير عضو (يسمى next في الكود) من type list_item * الذي يشير إلى العنصر التالي.
تطبيق C لهيكل البيانات هو:
struct list_item {
int value ;
struct list_item * next ;
};
typedef struct list_item list_item ;
struct list {
struct list_item * head ;
};
typedef struct list list ;ندرج أيضًا واجهة برمجة التطبيقات (الحد الأدنى):
/* The textbook version */
void remove_cs101 ( list * l , list_item * target );
/* A more elegant solution */
void remove_elegant ( list * l , list_item * target ); مع ذلك في مكانه ، دعنا نلقي نظرة على تطبيقات remove_cs101() و remove_elegant() . رمز هذه الأمثلة ينطبق على الرمز الكاذب من مثال Linus ويقوم أيضًا بتجميع ويدير.
الشكل 2 : النموذج المفاهيمي لهيكل بيانات القائمة في خوارزمية CS101.
void remove_cs101 ( list * l , list_item * target )
{
list_item * cur = l -> head , * prev = NULL ;
while ( cur != target ) {
prev = cur ;
cur = cur -> next ;
}
if ( prev )
prev -> next = cur -> next ;
else
l -> head = cur -> next ;
} يستفيد نهج CS101 القياسي من مؤشرين اجتيازين cur و prev ، مما يمثل وضع التوقيت الحالي والسابق في القائمة ، على التوالي. يبدأ cur من head القائمة ، ويتقدم حتى يتم العثور على الهدف. يبدأ prev من NULL ويتم تحديثه لاحقًا مع القيمة السابقة لـ cur في كل مرة تقدم فيها cur . بعد العثور على الهدف ، اختبارات الخوارزمية إذا كانت prev غير NULL . إذا كانت الإجابة بنعم ، فإن العنصر ليس في بداية القائمة ويتكون الإزالة من إعادة توجيه القائمة المرتبطة حول cur . إذا كانت prev NULL ، فإن cur يشير إلى العنصر الأول في القائمة ، وفي هذه الحالة ، يعني الإزالة تحريك القائمة إلى الأمام.
يحتوي الإصدار الأكثر أناقة على رمز أقل ولا يتطلب فرعًا منفصلاً للتعامل مع حذف العنصر الأول في القائمة.
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
* p = target -> next ;
} يستخدم الرمز مؤشرًا غير مباشر p يحتفظ بعنوان مؤشر إلى عنصر قائمة ، بدءًا من عنوان head . في كل تكرار ، يتم تطوير هذا المؤشر لعقد عنوان المؤشر إلى عنصر القائمة التالي ، أي عنوان العنصر next في list_item الحالي. عندما يساوي المؤشر إلى عنصر القائمة *p target ، نخرج من حلقة البحث وإزالة العنصر من القائمة.
البصيرة الرئيسية هي أن استخدام مؤشر غير مباشر p له فوائد مفاهيمية:
head جزءًا لا يتجزأ من بنية البيانات. هذا يلغي الحاجة إلى حالة خاصة لإزالة العنصر الأول.while الاضطرار إلى التخلي عن المؤشر الذي يشير إلى target . يتيح لنا ذلك تعديل المؤشر الذي يشير إلى target والابتعاد عن تكرار واحد بدلاً من prev و cur .دعونا ننظر كل نقطة من هذه النقاط بدورها.
head يفسر النموذج القياسي القائمة المرتبطة كتسلسل من مثيلات list_item . يمكن الوصول إلى بداية التسلسل من خلال مؤشر head . هذا يؤدي إلى النموذج المفاهيمي الموضح في الشكل 2 أعلاه. يعتبر مؤشر head مجرد مقبض للوصول إلى بداية القائمة. prev و cur هي مؤشرات من النوع list_item * وتشير دائمًا إلى عنصر أو NULL .
يستخدم التنفيذ الأنيق مخطط المعالجة غير المباشر الذي ينتج عنه عرض مختلف على بنية البيانات:
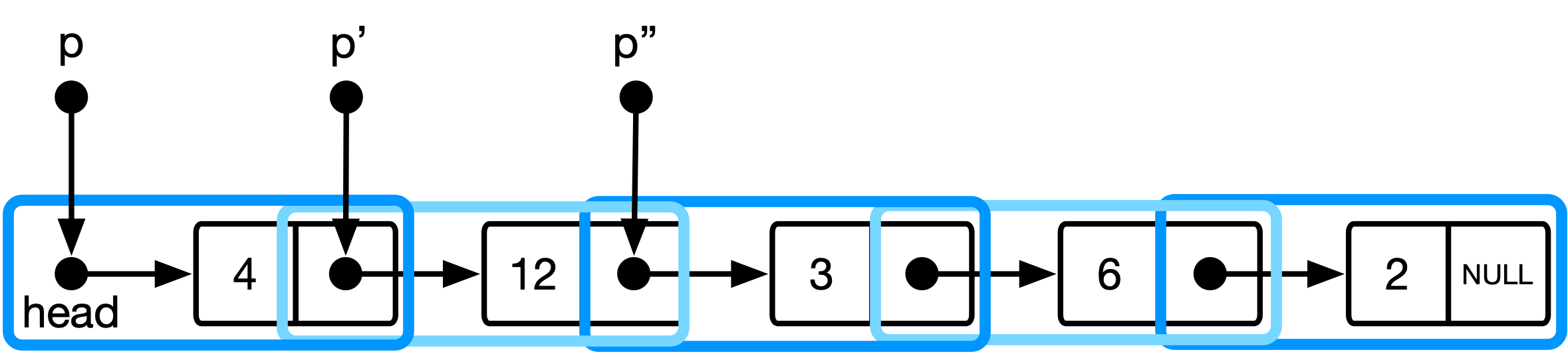
الشكل 3 : النموذج المفاهيمي لهيكل بيانات القائمة في النهج الأكثر أناقة.
هنا ، p من النوع list_item ** ويحتفظ بعنوان المؤشر إلى عنصر القائمة الحالي. عندما نتقدم للمؤشر ، نوجه إلى عنوان المؤشر إلى عنصر القائمة التالي.
في الكود ، هذا يترجم إلى p = &(*p)->next ، بمعنى أننا
(*p) : dereference العنوان إلى المؤشر إلى عنصر القائمة الحالي->next : dereference هذا المؤشر مرة أخرى وحدد الحقل الذي يحمل عنوان عنصر القائمة التالي& : خذ عنوان حقل العنوان هذا (أي احصل على مؤشر إليه) هذا يتوافق مع تفسير بنية البيانات حيث تكون القائمة عبارة عن سلسلة من المؤشرات إلى list_item s (راجع الشكل 3).
تتمثل فائدة إضافية في هذا التفسير بالذات في أنه يدعم تحرير المؤشر next لسلف العنصر الحالي في جميع أنحاء التمرير بأكمله.
مع عقد p لعنوان مؤشر إلى عنصر قائمة ، تصبح المقارنة في حلقة البحث
while ( * p != target ) ستخرج حلقة البحث إذا كان *p يساوي target ، وبمجرد وصوله ، لا نزال قادرين على تعديل *p لأننا نمسك عنوانه p . وبالتالي ، على الرغم من تكرار الحلقة حتى وصلنا إلى target ، ما زلنا نحافظ على مقبض (عنوان الحقل next أو مؤشر head ) الذي يمكن استخدامه لتعديل المؤشر مباشرةً الذي يشير إلى العنصر.
هذا هو السبب في أننا نتمكن من تعديل المؤشر الوارد إلى عنصر للإشارة إلى موقع مختلف باستخدام *p = target->next ولماذا لا نحتاج إلى مؤشرات prev و cur لاجتياز القائمة لإزالة العناصر.
اتضح أن الفكرة وراء remove_elegant() يمكن تطبيقها لتحقيق تنفيذ موجز بشكل خاص لوظيفة أخرى في API القائمة: insert_before() ، أي إدراج عنصر معين قبل واحد آخر.
أولاً ، دعنا نضيف الإعلان التالي إلى قائمة API في list.h .
void insert_before ( list * l , list_item * before , list_item * item ); ستأخذ الوظيفة مؤشرًا إلى قائمة l ، ومؤشر before إلى عنصر في تلك القائمة ومؤشر إلى item عنصر جديد ستقوم به الوظيفة من before .
قبل أن ننتقل ، نعيد صياغة حلقة البحث في وظيفة منفصلة
static inline list_item * * find_indirect ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
return p ;
} واستخدم هذه الوظيفة في remove_elegant() مثل ذلك
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = find_indirect ( l , target );
* p = target -> next ;
}insert_before() باستخدام find_indirect() ، من السهل تنفيذ insert_before() :
void insert_before ( list * l , list_item * before , list_item * item )
{
list_item * * p = find_indirect ( l , before );
* p = item ;
item -> next = before ;
} النتيجة الجميلة بشكل خاص هي أن التنفيذ له دلالات ثابتة لحالات الحافة: إذا كانت before النقاط إلى رأس القائمة ، فسيتم إدراج العنصر الجديد في بداية القائمة ، إذا كان before NULL أو غير صالح (أي أن العنصر غير موجود في l ) ، سيتم إلحاق العنصر الجديد في النهاية.
إن فرضية الحل الأكثر أناقة لحذف العناصر هي تغيير بسيط وبسيط: باستخدام مؤشر list_item ** للتكرار عبر المؤشرات إلى عناصر القائمة. كل شيء آخر يتدفق من هناك: ليست هناك حاجة لحالة خاصة أو تفرع ويكون مؤلف واحد كافٍ للعثور على العنصر المستهدف وإزالته. اتضح أيضًا أن نفس النهج يوفر حلًا أنيقًا لإدخال العنصر بشكل عام وللإدخال قبل عنصر موجود على وجه الخصوص.
لذا ، العودة إلى تعليق لينوس الأولي: هل هو ذوق جيد؟ من الصعب القول ، لكنه بالتأكيد حل مختلف وإبداعي وأنيق للغاية لمهمة CS المعروفة.


