linked list good taste
1.0.0
Dans une interview TED 2016 (14:10), Linus Torvalds parle de ce qu'il considère comme bon goût dans le codage. Par exemple, il présente deux implémentations de la suppression des éléments dans des listes liées individuellement (reproduites ci-dessous). Afin de supprimer le premier élément d'une liste, l'une des implémentations nécessite un cas spécial, l'autre ne le fait pas. Linus, évidemment, préfère ce dernier.
Son commentaire est:
[...] Je ne veux pas que vous compreniez pourquoi il n'a pas la déclaration IF. Mais je veux que vous compreniez que parfois vous pouvez voir un problème d'une manière différente et la réécrire afin qu'un cas spécial disparaisse et devienne le cas normal, et c'est un bon code . [...] - L. Torvalds
Les extraits de code qu'il présente sont un pseudocode de style C et sont assez simples à suivre. Cependant, comme Linus le mentionne dans le commentaire, les extraits n'ont pas d'explication conceptuelle et il n'est pas immédiatement évident comment la solution plus élégante fonctionne réellement.
Les deux sections suivantes examinent en détail l'approche technique et démontrent comment et pourquoi l'approche de l'adressage indirect est si soignée. La dernière section étend la solution de la suppression des éléments à l'insertion.
La structure de données de base pour une liste des entiers liée individuellement est illustrée à la figure 1.

Figure 1 : Liste des entiers liés individuellement.
Les nombres sont des valeurs entières arbitrairement choisies et les flèches indiquent des pointeurs. head est un pointeur de type list_item * et chacune des cases est une instance d'une structure list_item , chacune avec une variable membre (appelée next dans le code) de type list_item * qui pointe vers l'élément suivant.
La mise en œuvre C de la structure des données est:
struct list_item {
int value ;
struct list_item * next ;
};
typedef struct list_item list_item ;
struct list {
struct list_item * head ;
};
typedef struct list list ;Nous incluons également une API (minimale):
/* The textbook version */
void remove_cs101 ( list * l , list_item * target );
/* A more elegant solution */
void remove_elegant ( list * l , list_item * target ); Avec cela en place, jetons un œil aux implémentations de remove_cs101() et remove_elegant() . Le code de ces exemples est fidèle au pseudocode à partir de l'exemple de Linus et compile et s'exécute également.
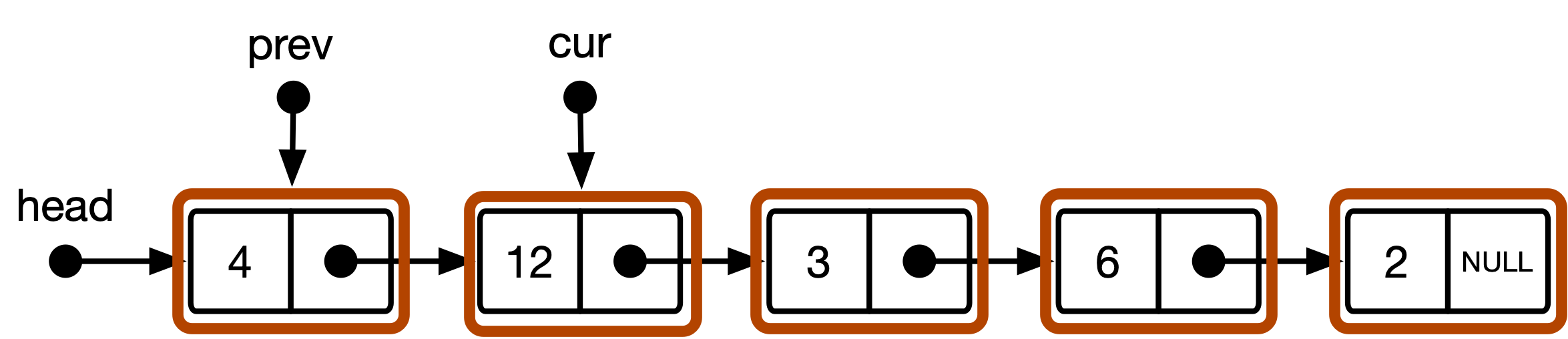
Figure 2 : Le modèle conceptuel de la structure des données de liste dans l'algorithme CS101.
void remove_cs101 ( list * l , list_item * target )
{
list_item * cur = l -> head , * prev = NULL ;
while ( cur != target ) {
prev = cur ;
cur = cur -> next ;
}
if ( prev )
prev -> next = cur -> next ;
else
l -> head = cur -> next ;
} L'approche CS101 standard utilise cur deux pointeurs prev traversée, marquant la position de traversée actuelle et précédente dans la liste, respectivement. cur commence à la head de la liste et avance jusqu'à ce que la cible soit trouvée. prev commence à NULL et est par la suite mis à jour avec la valeur précédente de cur chaque fois cur avance. Une fois la cible trouvée, l'algorithme teste si prev est non NULL . Si oui, l'article n'est pas au début de la liste et la suppression consiste à réacheminer la liste liée autour cur . Si prev est NULL , cur pointe vers le premier élément de la liste, auquel cas, le retrait signifie déplacer la tête de liste vers l'avant.
La version plus élégante a moins de code et ne nécessite pas de branche distincte pour gérer la suppression du premier élément d'une liste.
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
* p = target -> next ;
} Le code utilise un pointeur indirect p qui contient l'adresse d'un pointeur vers un élément de liste, en commençant par l'adresse de head . Dans chaque itération, ce pointeur est avancé pour maintenir l'adresse du pointeur vers l'élément de liste suivante, c'est-à-dire l'adresse de l'élément next dans la list_item actuelle. Lorsque le pointeur vers l'élément de liste *p est égal target , nous quittons la boucle de recherche et supprimons l'élément de la liste.
L'informatique clé est que l'utilisation d'un pointeur indirect p a deux avantages conceptuels:
head une partie intégrante de la structure de données. Cela élimine la nécessité d'un cas spécial pour supprimer le premier élément.while sans avoir à abandonner le pointeur qui pointe vers target . Cela nous permet de modifier le pointeur qui pointe vers target et de nous en sortir avec un seul itérateur par opposition à prev et cur .Regardons chacun de ces points tour à tour.
head Le modèle standard interprète la liste liée en tant que séquence d'instances list_item . Le début de la séquence est accessible via un pointeur head . Cela conduit au modèle conceptuel illustré à la figure 2 ci-dessus. Le pointeur head est simplement considéré comme une poignée pour accéder au début de la liste. prev et cur sont des pointeurs de type list_item * et pointent toujours vers un élément ou NULL .
L'implémentation élégante utilise un schéma d'adressage indirect qui donne une vue différente sur la structure des données:
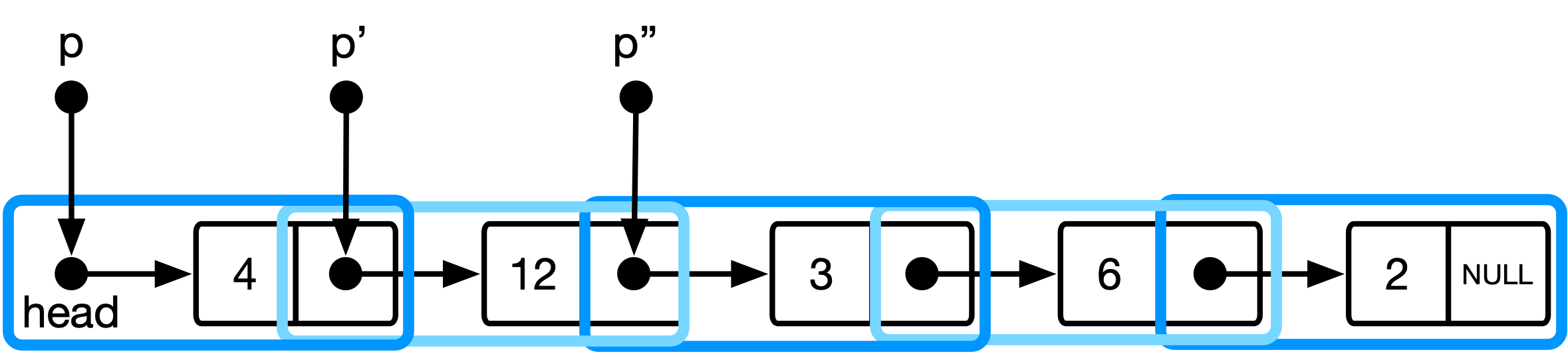
Figure 3 : Le modèle conceptuel de la structure des données de liste dans l'approche plus élégante.
Ici, p est de type list_item ** et maintient l'adresse du pointeur vers l'élément de liste actuel. Lorsque nous avançons le pointeur, nous transmettions vers l'adresse du pointeur vers l'élément de liste suivante.
Dans le code, cela se traduit par p = &(*p)->next , ce qui signifie que nous
(*p) : déréférence l'adresse du pointeur vers l'élément de liste actuel->next : déréférence à nouveau ce pointeur et sélectionnez le champ qui contient l'adresse de l'élément de liste suivante& : Prenez l'adresse de ce champ d'adresse (c'est-à-dire obtenir un pointeur) Cela correspond à une interprétation de la structure de données où la liste est une séquence de pointeurs vers list_item S (cf. Figure 3).
Un avantage supplémentaire de cette interprétation particulière est qu'il prend en charge l'édition du pointeur next du prédécesseur de l'élément actuel tout au long de la traversée.
Avec p tenant l'adresse d'un pointeur vers un élément de liste, la comparaison dans la boucle de recherche devient
while ( * p != target ) La boucle de recherche quittera si *p égalise target , et une fois le cas, nous sommes toujours en mesure de modifier *p puisque nous tenons son adresse p . Ainsi, malgré l'itération de la boucle jusqu'à ce que nous atteignions target , nous maintenons toujours une poignée (l'adresse du champ next ou du pointeur head ) qui peut être utilisée pour modifier directement le pointeur qui pointe vers l'élément.
C'est la raison pour laquelle nous pouvons modifier le pointeur entrant vers un élément pour pointer vers un emplacement différent en utilisant *p = target->next et pourquoi nous n'avons pas besoin de pointeurs prev et cur pour traverser la liste pour la suppression des éléments.
Il s'avère que l'idée derrière remove_elegant() peut être appliquée pour produire une implémentation particulièrement concise d'une autre fonction dans l'API de la liste: insert_before() , c'est-à-dire en insertant un élément donné avant un autre.
Tout d'abord, ajoutons la déclaration suivante à l'API de la liste dans list.h :
void insert_before ( list * l , list_item * before , list_item * item ); La fonction prendra un pointeur vers une liste l , un pointeur before un élément de cette liste et un pointeur vers un nouvel item de liste que la fonction inséra before .
Avant de passer à autre chose, nous refactorons la boucle de recherche dans une fonction distincte
static inline list_item * * find_indirect ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
return p ;
} et utilisez cette fonction dans remove_elegant() comme ainsi
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = find_indirect ( l , target );
* p = target -> next ;
}insert_before() En utilisant find_indirect() , il est simple d'implémenter insert_before() :
void insert_before ( list * l , list_item * before , list_item * item )
{
list_item * * p = find_indirect ( l , before );
* p = item ;
item -> next = before ;
} Un résultat particulièrement beau est que la mise en œuvre a une sémantique cohérente pour les cas Edge: si before pointe la tête de la liste, le nouvel élément sera inséré au début de la liste, si before est NULL ou invalide (c'est-à-dire que l'élément n'existe pas en l ), le nouvel élément sera annexe à la fin.
La prémisse de la solution plus élégante pour la suppression des éléments est un seul changement simple: en utilisant un pointeur indirect list_item ** pour itérer les pointeurs vers les éléments de la liste. Tout le reste s'écoule à partir de là: il n'y a pas besoin d'un cas ou de ramification spécial et un seul itérateur est suffisant pour trouver et supprimer l'élément cible. Il s'avère également que la même approche fournit une solution élégante pour l'insertion des éléments en général et pour l'insertion devant un élément existant en particulier.
Alors, revenir au commentaire initial de Linus: est-ce bon goût? Difficile à dire, mais c'est certainement une solution différente, créative et très élégante à une tâche CS bien connue.


