linked list good taste
1.0.0
Em uma entrevista do TED de 2016 (14:10) Linus Torvalds fala sobre o que ele considera bom gosto pela codificação. Como exemplo, ele apresenta duas implementações de remoção de itens em listas vinculadas individualmente (reproduzidas abaixo). Para remover o primeiro item de uma lista, uma das implementações requer um caso especial, o outro não. Linus, obviamente, prefere o último.
Seu comentário é:
[...] Não quero que você entenda por que não tem a instrução IF. Mas quero que você entenda que, às vezes, pode ver um problema de uma maneira diferente e reescrevê -lo para que um caso especial desapareça e se torne o caso normal, e esse é um bom código . [...] - L. Torvalds
Os trechos de código que ele apresenta são pseudocódicos no estilo C e são simples o suficiente para seguir. No entanto, como Linus menciona no comentário, os trechos não têm uma explicação conceitual e não é imediatamente evidente como a solução mais elegante realmente funciona.
As próximas duas seções analisam a abordagem técnica em detalhes e demonstram como e por que a abordagem de abordagem indireta é tão arrumada. A última seção estende a solução da exclusão do item à inserção.
A estrutura básica de dados para uma lista de números inteiros vinculados é mostrada na Figura 1.

Figura 1 : Lista de números inteiros ligados individualmente.
Os números são os valores inteiros e setas escolhidas arbitrariamente indicam ponteiros. head é um ponteiro do tipo list_item * e cada uma das caixas é uma instância de uma estrutura list_item , cada uma com uma variável de membro (chamada next no código) do tipo list_item * que aponta para o próximo item.
A implementação C da estrutura de dados é:
struct list_item {
int value ;
struct list_item * next ;
};
typedef struct list_item list_item ;
struct list {
struct list_item * head ;
};
typedef struct list list ;Também incluímos uma API (mínima):
/* The textbook version */
void remove_cs101 ( list * l , list_item * target );
/* A more elegant solution */
void remove_elegant ( list * l , list_item * target ); Com isso no lugar, vamos dar uma olhada nas implementações de remove_cs101() e remove_elegant() . O código desses exemplos é fiel ao pseudocódigo do exemplo de Linus e também compila e executa.
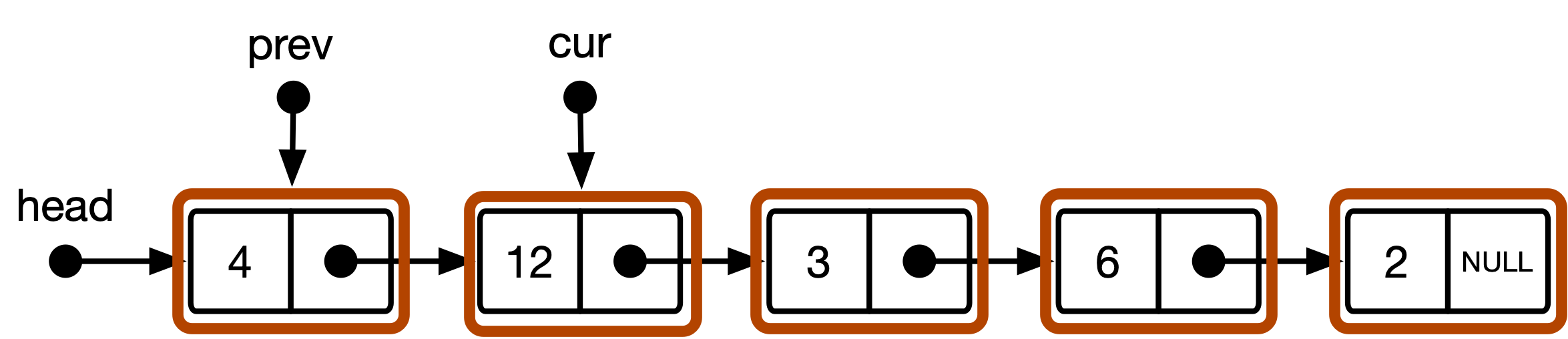
Figura 2 : O modelo conceitual para a estrutura de dados da lista no algoritmo CS101.
void remove_cs101 ( list * l , list_item * target )
{
list_item * cur = l -> head , * prev = NULL ;
while ( cur != target ) {
prev = cur ;
cur = cur -> next ;
}
if ( prev )
prev -> next = cur -> next ;
else
l -> head = cur -> next ;
} A abordagem CS101 padrão utiliza dois ponteiros de travessia cur e prev , marcando a posição de travessia atual e anterior na lista, respectivamente. cur começa na head da lista e avança até que o alvo seja encontrado. prev começa no NULL e é posteriormente atualizado com o valor anterior do cur sempre que os avanços cur . Depois que o alvo é encontrado, os testes do algoritmo se prev não forem NULL . Se sim, o item não está no início da lista e a remoção consiste em redirecionar a lista vinculada em torno cur . Se prev for NULL , cur está apontando para o primeiro elemento da lista; nesse caso, a remoção significa mover a lista da lista.
A versão mais elegante tem menos código e não requer uma ramificação separada para lidar com a exclusão do primeiro elemento em uma lista.
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
* p = target -> next ;
} O código usa um ponteiro indireto p que mantém o endereço de um ponteiro para um item da lista, começando com o endereço da head . Em todas as iterações, esse ponteiro é avançado para manter o endereço do ponteiro para o próximo item da lista, ou seja, o endereço do next elemento no atual list_item . Quando o ponteiro para o item da lista *p é igual target , saímos do loop de pesquisa e removemos o item da lista.
O principal insight é que o uso de um ponteiro indireto p tem dois benefícios conceituais:
head uma parte integrante da estrutura de dados. Isso elimina a necessidade de um caso especial para remover o primeiro item.while sem ter que deixar de lado o ponteiro que aponta para target . Isso nos permite modificar o ponteiro que aponta para target e se safar de um único iterador, em oposição ao prev e cur .Vamos olhar cada um desses pontos por sua vez.
head O modelo padrão interpreta a lista vinculada como uma sequência de instâncias list_item . O início da sequência pode ser acessado através de um ponteiro head . Isso leva ao modelo conceitual ilustrado na Figura 2 acima. O ponteiro head é apenas considerado uma alça para acessar o início da lista. prev e cur são ponteiros do tipo list_item * e sempre apontam para um item ou NULL .
A implementação elegante usa o esquema de endereçamento indireto que gera uma visão diferente da estrutura de dados:
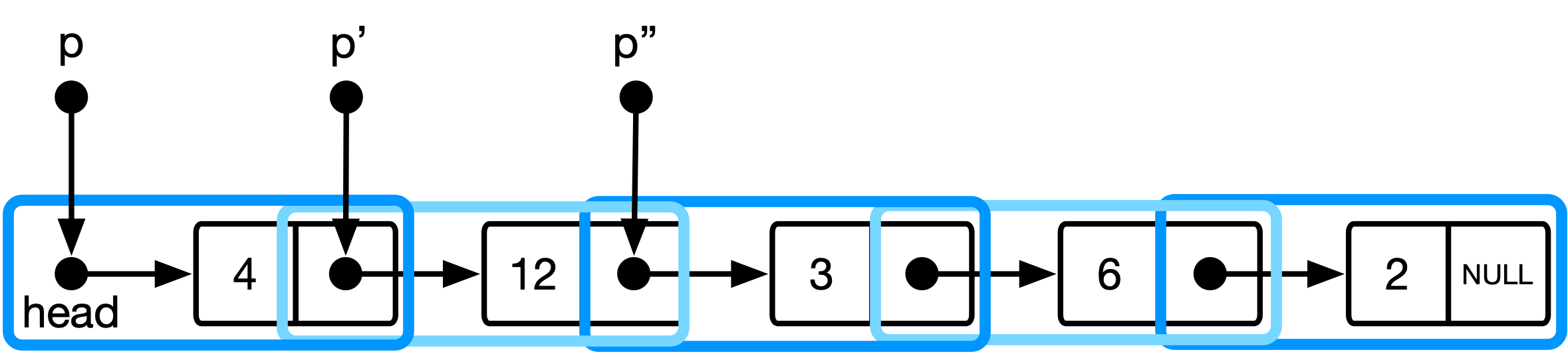
Figura 3 : O modelo conceitual para a estrutura de dados da lista na abordagem mais elegante.
Aqui, p é do tipo list_item ** e mantém o endereço do ponteiro do item da lista atual. Quando avançamos no ponteiro, avançamos para o endereço do ponteiro para o próximo item da lista.
No código, isso se traduz em p = &(*p)->next , o que significa que nós
(*p) : Desrereferência o endereço para o ponteiro para o item atual da lista->next : Dereference That Pointer novamente e selecione o campo que mantém o endereço do próximo item da lista& : Pegue o endereço desse campo de endereço (ou seja, obtenha um ponteiro para ele) Isso corresponde a uma interpretação da estrutura de dados em que a lista é uma sequência de ponteiros para list_item s (cf. Figura 3).
Um benefício adicional dessa interpretação específica é que ela suporta a edição do next ponteiro do antecessor do item atual em toda a travessia.
Com p mantendo o endereço de um ponteiro para um item da lista, a comparação no loop de pesquisa se torna
while ( * p != target ) O loop de pesquisa sairá se *p for igual target e, uma vez que o fizer, ainda poderá modificar *p pois mantemos seu endereço p . Assim, apesar da iteração do loop até atingirmos target , ainda mantemos uma alça (o endereço do next campo ou o ponteiro head ) que pode ser usado para modificar diretamente o ponteiro que aponta para o item.
Esta é a razão pela qual podemos modificar o ponteiro de entrada para um item para apontar para um local diferente usando *p = target->next e por que não precisamos prev e cur para atravessar a lista para remoção de itens.
Acontece que a idéia por trás remove_elegant() pode ser aplicada para produzir uma implementação particularmente concisa de outra função na API da lista: insert_before() , ou seja, inserindo um determinado item antes de outro.
Primeiro, vamos adicionar a seguinte declaração à API da lista na list.h :
void insert_before ( list * l , list_item * before , list_item * item ); A função levará um ponteiro para uma lista l , um ponteiro before de um item nessa lista e um ponteiro para um novo item da lista que a função será inserida before .
Antes de seguirmos em frente, refatoramos o loop de pesquisa em uma função separada
static inline list_item * * find_indirect ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
return p ;
} e use essa função em remove_elegant() como assim
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = find_indirect ( l , target );
* p = target -> next ;
}insert_before() Usando find_indirect() , é simples implementar insert_before() :
void insert_before ( list * l , list_item * before , list_item * item )
{
list_item * * p = find_indirect ( l , before );
* p = item ;
item -> next = before ;
} Um resultado particularmente bonito é que a implementação possui semântica consistente para os casos de borda: se before apontar para a cabeça da lista, o novo item será inserido no início da lista, se before for NULL ou inválido (ou seja, o item não existe em l ), o novo item será anexado no final.
A premissa da solução mais elegante para a exclusão de itens é uma mudança simples e simples: usando um ponteiro list_item ** para iterar sobre os ponteiros para os itens da lista. Todo o resto flui a partir daí: não há necessidade de um caso ou ramificação especial e um único iterador é suficiente para encontrar e remover o item de destino. Acontece também que a mesma abordagem fornece uma solução elegante para inserção de itens em geral e para inserção antes de um item existente em particular.
Então, voltando ao comentário inicial de Linus: é bom gosto? Difícil dizer, mas é certamente uma solução diferente, criativa e muito elegante para uma tarefa CS bem conhecida.


