linked list good taste
1.0.0
En una entrevista de TED 2016 (14:10) Linus Torvalds habla sobre lo que considera el buen gusto en la codificación. Como ejemplo, presenta dos implementaciones de la eliminación de elementos en listas vinculadas individualmente (reproducidas a continuación). Para eliminar el primer elemento de una lista, una de las implementaciones requiere un caso especial, el otro no. Linus, obviamente, prefiere este último.
Su comentario es:
[...] No quiero que entiendas por qué no tiene la declaración IF. Pero quiero que entiendas que a veces puedes ver un problema de una manera diferente y reescribirlo para que un caso especial desaparezca y se convierta en el caso normal, y ese es un buen código . [...] - L. Torvalds
Los fragmentos de código que presenta son el pseudocódigo de estilo C y son lo suficientemente simples para seguir. Sin embargo, como Linus menciona en el comentario, los fragmentos carecen de una explicación conceptual y no es evidente de inmediato cómo funciona realmente la solución más elegante.
Las siguientes dos secciones analizan el enfoque técnico en detalle y demuestran cómo y por qué el enfoque de direccionamiento indirecto es tan ordenado. La última sección extiende la solución de la eliminación del elemento a la inserción.
La estructura de datos básica para una lista de enteros vinculados individualmente se muestra en la Figura 1.

Figura 1 : Lista de enteros vinculados individualmente.
Los números son valores enteros elegidos arbitrariamente y las flechas indican punteros. head es un puntero de type list_item * y cada uno de los cuadros es una instancia de una estructura list_item , cada una con una variable miembro (llamada next en el código) de type list_item * que apunta al siguiente elemento.
La implementación de C de la estructura de datos es:
struct list_item {
int value ;
struct list_item * next ;
};
typedef struct list_item list_item ;
struct list {
struct list_item * head ;
};
typedef struct list list ;También incluimos una API (mínima):
/* The textbook version */
void remove_cs101 ( list * l , list_item * target );
/* A more elegant solution */
void remove_elegant ( list * l , list_item * target ); Con eso en su lugar, echemos un vistazo a las implementaciones de remove_cs101() y remove_elegant() . El código de estos ejemplos es cierto al pseudocódigo del ejemplo de Linus y también se compila y se ejecuta.
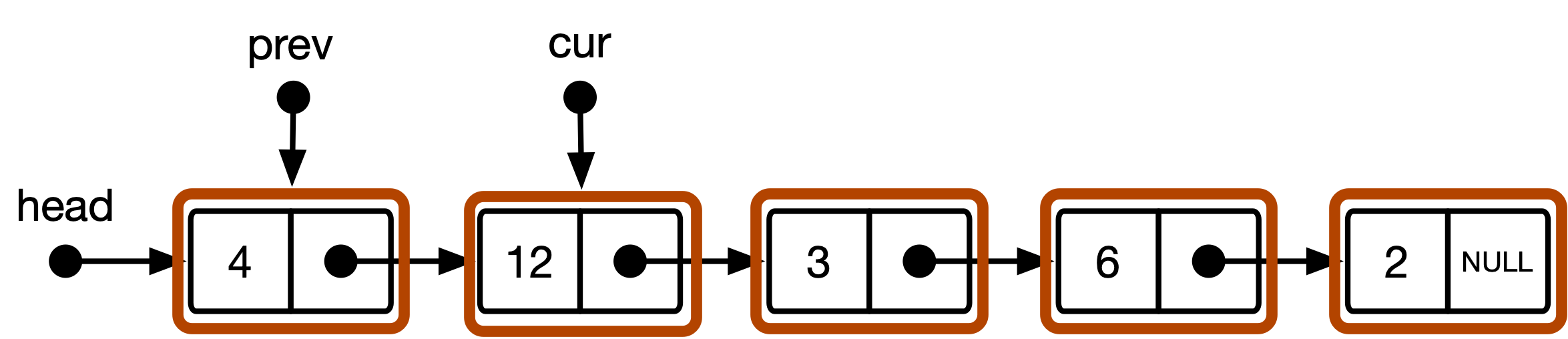
Figura 2 : El modelo conceptual para la estructura de datos de la lista en el algoritmo CS101.
void remove_cs101 ( list * l , list_item * target )
{
list_item * cur = l -> head , * prev = NULL ;
while ( cur != target ) {
prev = cur ;
cur = cur -> next ;
}
if ( prev )
prev -> next = cur -> next ;
else
l -> head = cur -> next ;
} El enfoque CS101 estándar hace uso de dos punteros de recorrido cur y prev , marcando la posición transversal actual y anterior en la lista, respectivamente. cur comienza en el head de la lista y avanza hasta que se encuentra el objetivo. prev comienza en NULL y posteriormente se actualiza con el valor anterior de cur cada vez que avanza cur . Después de encontrar el objetivo, el algoritmo prueba si prev no es NULL . En caso afirmativo, el elemento no está al comienzo de la lista y la eliminación consiste en redirigir la lista vinculada en torno cur . Si prev es NULL , cur apunta al primer elemento en la lista, en cuyo caso, la eliminación significa mover el cabezal de la lista hacia adelante.
La versión más elegante tiene menos código y no requiere una rama separada para lidiar con la eliminación del primer elemento en una lista.
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
* p = target -> next ;
} El código utiliza un puntero indirecto p que contiene la dirección de un puntero a un elemento de lista, comenzando con la dirección de head . En cada iteración, ese puntero avanza para mantener la dirección del puntero al siguiente elemento de la lista, es decir, la dirección del next elemento en la list_item actual_item. Cuando el puntero al elemento de la lista *p es igual target , salimos del bucle de búsqueda y eliminamos el elemento de la lista.
La idea clave es que el uso de un puntero indirecto p tiene dos beneficios conceptuales:
head sea parte integral de la estructura de datos. Esto elimina la necesidad de un caso especial para eliminar el primer elemento.while sin tener que dejar de lado el puntero que apunta al target . Esto nos permite modificar el puntero que apunta a target y escapar con un solo iterador en lugar de prev y cur .Veamos cada uno de estos puntos a su vez.
head El modelo estándar interpreta la lista vinculada como una secuencia de instancias list_item . Se puede acceder al comienzo de la secuencia a través de un puntero head . Esto conduce al modelo conceptual ilustrado en la Figura 2 anterior. El puntero head se considera simplemente como un mango para acceder al inicio de la lista. prev y cur son punteros de type list_item * y siempre apuntan a un elemento o NULL .
La elegante implementación utiliza un esquema de direccionamiento indirecto que produce una vista diferente sobre la estructura de datos:
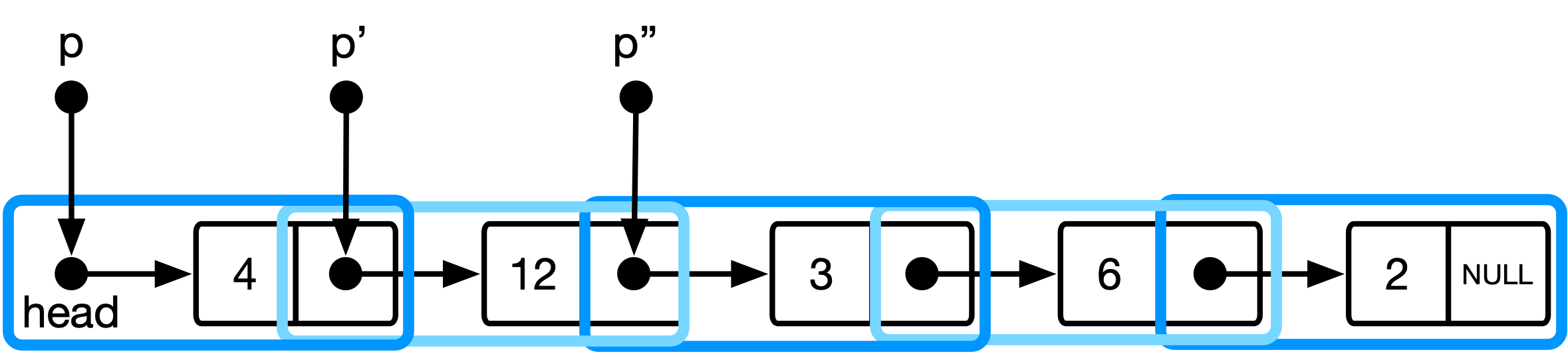
Figura 3 : El modelo conceptual para la estructura de datos de la lista en el enfoque más elegante.
Aquí, p es de tipo list_item ** y mantiene la dirección del puntero al elemento de la lista actual. Cuando avanzamos el puntero, reenviamos a la dirección del puntero al siguiente elemento de la lista.
En código, esto se traduce en p = &(*p)->next , lo que significa que nosotros
(*p) : desreferencia la dirección al puntero al elemento de la lista actual->next : DEFERENCIA ESE PUNTER nuevamente y seleccione el campo que contiene la dirección del siguiente elemento de la lista& : Tome la dirección de ese campo de dirección (es decir, obtener un puntero) Esto corresponde a una interpretación de la estructura de datos donde la lista es una secuencia de punteros para list_item s (cf. Figura 3).
Un beneficio adicional de esa interpretación en particular es que admite la edición del next puntero del predecesor del elemento actual en todo el recorrido.
Con p manteniendo la dirección de un puntero a un elemento de lista, la comparación en el bucle de búsqueda se convierte en
while ( * p != target ) El bucle de búsqueda saldrá si *p es igual target , y una vez que lo haga, todavía podemos modificar *p ya que mantenemos su dirección p . Por lo tanto, a pesar de iterar el bucle hasta que llegamos a target , todavía mantenemos un mango (la dirección del campo next o el puntero head ) que puede usarse para modificar directamente el puntero que apunta al elemento.
Esta es la razón por la que podemos modificar el puntero entrante a un elemento para señalar una ubicación diferente usando *p = target->next y por qué no necesitamos punteros prev y cur para atravesar la lista para la eliminación del elemento.
Resulta que la idea detrás de remove_elegant() puede aplicarse para producir una implementación particularmente concisa de otra función en la API de la lista: insert_before() , es decir, insertar un elemento dado antes de otro.
Primero, agregemos la siguiente declaración a la API de la lista en list.h :
void insert_before ( list * l , list_item * before , list_item * item ); La función llevará un puntero a una lista l , un puntero before a un elemento en esa lista y un puntero a un nuevo item de la lista que la función insertará before .
Antes de seguir adelante, refactorizamos el bucle de búsqueda en una función separada
static inline list_item * * find_indirect ( list * l , list_item * target )
{
list_item * * p = & l -> head ;
while ( * p != target )
p = & ( * p ) -> next ;
return p ;
} y use esa función en remove_elegant() como
void remove_elegant ( list * l , list_item * target )
{
list_item * * p = find_indirect ( l , target );
* p = target -> next ;
}insert_before() Usando find_indirect() , es sencillo implementar insert_before() ::
void insert_before ( list * l , list_item * before , list_item * item )
{
list_item * * p = find_indirect ( l , before );
* p = item ;
item -> next = before ;
} Un resultado particularmente hermoso es que la implementación tiene una semántica consistente para los casos de borde: si before los puntos al cabezal de la lista, el nuevo elemento se insertará al comienzo de la lista, si before es NULL o no es válido (es decir, el elemento no existe en l ), el nuevo elemento se agregará al final.
La premisa de la solución más elegante para la eliminación de elementos es un solo cambio simple: usar un puntero indirecto list_item ** para iterar sobre los punteros a los elementos de la lista. Todo lo demás fluye desde allí: no hay necesidad de un caso o ramificación especial y un solo iterador es suficiente para encontrar y eliminar el elemento de destino. También resulta que el mismo enfoque proporciona una solución elegante para la inserción del elemento en general y para la inserción ante un elemento existente en particular.
Entonces, volviendo al comentario inicial de Linus: ¿es un buen gusto? Es difícil decirlo, pero ciertamente es una solución diferente, creativa y muy elegante para una tarea CS bien conocida.


