neoplanner
1.0.0
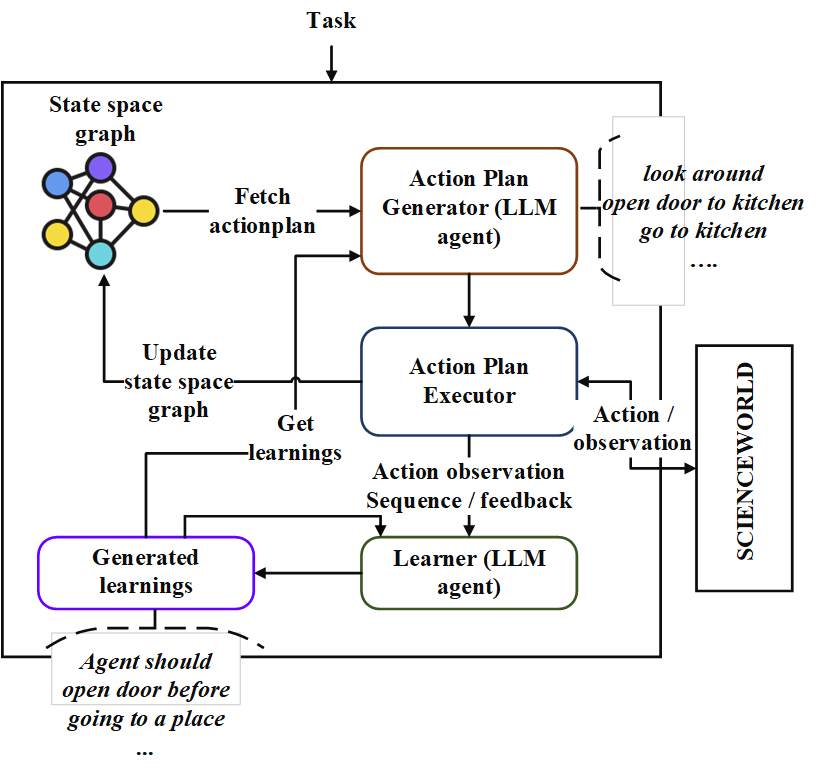
该仓库包含了一个名为“ Neoplanner”的顺序规划代理的实现。该计划者适用于具有较大状态空间和动作空间的基于文本的环境。它通过查询与基础LLM的疑问协同结合了两种状态空间搜索,以获得最佳的行动计划。奖励信号定量用于驱动搜索。通过最大化状态值的上限置信度来维持探索和剥削的平衡。在需要随机探索的地方,LLM被查询以生成动作计划。从每个试验中学习以文本格式存储为实体关系。这些用于LLM的将来查询以持续改进。科学世界环境中的实验揭示了与当前最佳方法相比提高了124%,这是在多个任务中获得的平均奖励。以下是架构。
首先,克隆回购并导航到Neoplanner目录并安装要求
git clone https://github.com/swarna-kpaul/neoplanner
cd neoplanner
python3 -m pip install -r requirements.txt然后,您需要修改config/keys.py文件以更新OpenAiaPikey 。您可以通过注册到OpenAI门户来获取API密钥。第一次用户可以免费获得5美元的信用额。您可以从此URL获取API键
此后可以进口包装
from solver import neoplanner初始化求解器对象
# task is the identifier of tasks as specified in
# stmloadfile is the name of the file (with full path) that contains saved state. The state will be loaded initially. default value is None
# stmstoragefile is the name of the file (with full path) whare intermediate states can be saved. default value is None
# beliefstorefile is the name of the file (with full path) whare intermediate learnings can be saved. default value is None
# beliefloadfile is the name of the file (with full path) that contains intermediate learnings. The learnings will be loaded initially. default value is None
# sigma is exploration probability constant. Increasing its value would increase random exploration by the the LLM.
solverobj = neoplanner ( task = "2-1" , stmloadfile = None , stmstoragefile = None , beliefstorefile = None , beliefloadfile = None , sigma = 0.3 )运行求解器。
env = solverobj . train ()
######## get actionplan from statespace graph
additionalinstructions , actionplan , _ , _ , _ = env . getinstructions ()培训将继续进行,直到达到目标。您可以中断培训过程之间。在这种情况下,请确保您提供stmstoragefile和ChielStoreFile,以保存中间状态和信念。
您可以加载stmstoragefile并查询env对象以从状态空间图中获取操作计划。
import pickle
from solver import scienv
env = scienv ( "2-1" )
stmstoragefile = < file name with full path >
with open ( stmstoragefile , 'rb' ) as f :
rootnodeid , invalidnodeid , DEFAULTVALUE , statespace , totaltrials , actiontrace , environment = pickle . load ( f )
env . model . rootnodeid = rootnodeid
env . model . invalidnodeid = invalidnodeid
env . model . DEFAULTVALUE = DEFAULTVALUE
env . model . statespace = statespace
env . model . totaltrials = totaltrials
env . environment = environment
env . reset ()
additionalinstructions , actionplan , _ , _ , _ = env . getinstructions ()预处理文件夹包含所有训练有素的状态空间和学习7个任务的文件。您可以使用上述代码来查看任务的求解操作计划,通过使用适当的文件名设置stmstoragefile
通过运行以下代码可以看到学习
import pickle
beliefloadfile = < belief load file name >
with open ( beliefloadfile , 'rb' ) as f :
beliefaxioms , totalexplore = pickle . load ( f )
print ( beliefaxioms ) @misc{paul2023sequential,
title={Sequential Planning in Large Partially Observable Environments guided by LLMs},
author={Swarna Kamal Paul},
year={2023},
eprint={2312.07368},
archivePrefix={arXiv},
primaryClass={cs.AI}
}


