neoplanner
1.0.0
Este repo contém a implementação de um agente de planejamento seqüencial chamado "Neoplanner". Esse planejador é adequado para ambientes baseados em texto com grande espaço de estado e espaço de ação. Ele severa sinergiza a pesquisa de espaço de estado com consultas para o LLM fundamental para obter o melhor plano de ação. Os sinais de recompensa são usados quantitativamente para direcionar a pesquisa. Um equilíbrio de exploração e exploração é mantido, maximizando os limites de confiança superior dos valores dos estados. Em locais onde é necessária uma exploração aleatória, o LLM é consultado para gerar um plano de ação. Os aprendizados de cada tentativa são armazenados como relacionamentos de entidade no formato de texto. Essas são usadas em consultas futuras no LLM para melhoria contínua. Experimentos no ambiente ScienceWorld revelam uma melhoria de 124% do melhor método atual em termos de recompensa média obtida em várias tarefas. A seguir, a arquitethture.
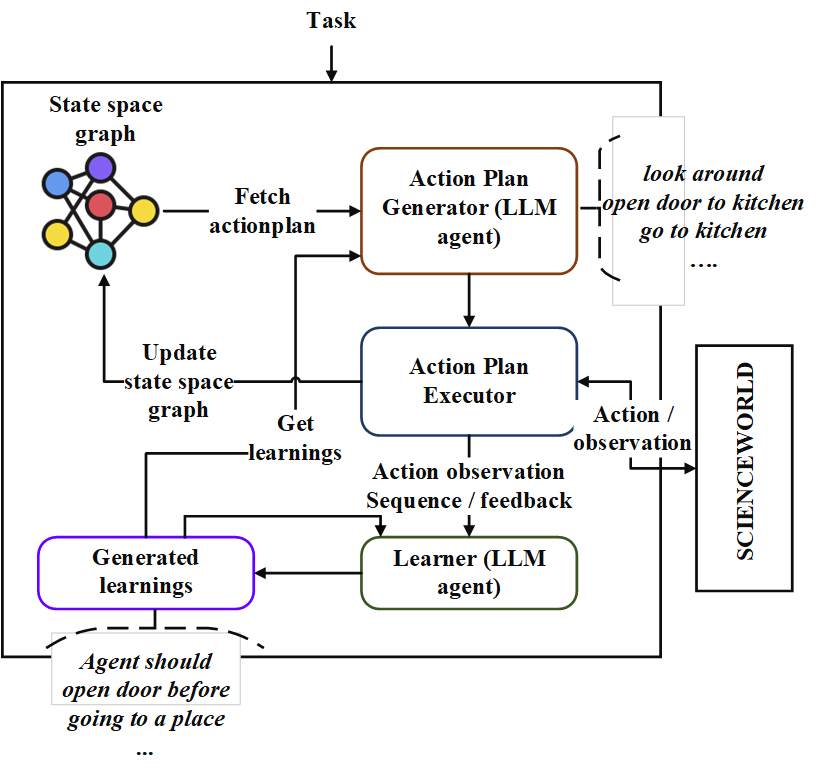
Primeiro, clone o repositório e navegue no diretório Neoplanner e instale os requisitos
git clone https://github.com/swarna-kpaul/neoplanner
cd neoplanner
python3 -m pip install -r requirements.txtEm seguida, você precisa modificar o arquivo config/keys.py para atualizar o OpenAiapikey . Você pode obter sua chave da API registrando -se no portal OpenAI. Os usuários iniciantes podem obter um crédito gratuito de US $ 5 para experimentar. Você pode obter sua chave de API deste URL
Depois disso, o pacote pode ser importado
from solver import neoplannerInicialize o objeto de solucionador
# task is the identifier of tasks as specified in
# stmloadfile is the name of the file (with full path) that contains saved state. The state will be loaded initially. default value is None
# stmstoragefile is the name of the file (with full path) whare intermediate states can be saved. default value is None
# beliefstorefile is the name of the file (with full path) whare intermediate learnings can be saved. default value is None
# beliefloadfile is the name of the file (with full path) that contains intermediate learnings. The learnings will be loaded initially. default value is None
# sigma is exploration probability constant. Increasing its value would increase random exploration by the the LLM.
solverobj = neoplanner ( task = "2-1" , stmloadfile = None , stmstoragefile = None , beliefstorefile = None , beliefloadfile = None , sigma = 0.3 )Execute o solucionador.
env = solverobj . train ()
######## get actionplan from statespace graph
additionalinstructions , actionplan , _ , _ , _ = env . getinstructions ()O treinamento continuará funcionando até que o objetivo seja alcançado. Você pode interromper o processo de treinamento no meio. Nesse caso, certifique -se de fornecer o STMStorageFile e o CREEFENDStoreFile, para que estados e crenças intermediários sejam salvos.
Você pode carregar o STMSTORAGEFILE e consultar o objeto Env para obter o plano de ação do gráfico do espaço do estado.
import pickle
from solver import scienv
env = scienv ( "2-1" )
stmstoragefile = < file name with full path >
with open ( stmstoragefile , 'rb' ) as f :
rootnodeid , invalidnodeid , DEFAULTVALUE , statespace , totaltrials , actiontrace , environment = pickle . load ( f )
env . model . rootnodeid = rootnodeid
env . model . invalidnodeid = invalidnodeid
env . model . DEFAULTVALUE = DEFAULTVALUE
env . model . statespace = statespace
env . model . totaltrials = totaltrials
env . environment = environment
env . reset ()
additionalinstructions , actionplan , _ , _ , _ = env . getinstructions ()A pasta Pré -RaiedFiles contém todos os arquivos estatais treinados e de aprendizado para 7 tarefas. Você pode analisar o plano de ação resolvido das tarefas usando o código acima, definindo o STMStorageFile com o nome de arquivo apropriado
Os aprendizados podem ser vistos executando o seguinte código
import pickle
beliefloadfile = < belief load file name >
with open ( beliefloadfile , 'rb' ) as f :
beliefaxioms , totalexplore = pickle . load ( f )
print ( beliefaxioms ) @misc{paul2023sequential,
title={Sequential Planning in Large Partially Observable Environments guided by LLMs},
author={Swarna Kamal Paul},
year={2023},
eprint={2312.07368},
archivePrefix={arXiv},
primaryClass={cs.AI}
}


