neoplanner
1.0.0
يحتوي هذا الريبو على تنفيذ وكيل تخطيط متسلسل يسمى "Neoplanner". هذا المخطط مناسب للبيئات المستندة إلى النص مع مساحة كبيرة للحالة ومساحة عمل. إنه يتفوق على كلا من البحث عن مساحة الدولة مع الاستعلامات إلى LLM التأسيسية للحصول على أفضل خطة عمل. يتم استخدام إشارات المكافأة كمياً لقيادة البحث. يتم الحفاظ على توازن الاستكشاف والاستغلال من خلال زيادة حدود الثقة العليا لقيم الحالات. في الأماكن التي يلزم الاستكشاف العشوائي ، يتم الاستعلام عن LLM لإنشاء خطة عمل. يتم تخزين التعلم من كل تجربة كعلاقات كيان بتنسيق النص. وتستخدم تلك في الاستعلامات المستقبلية إلى LLM للتحسين المستمر. تكشف التجارب في بيئة ScienceWorld عن تحسن بنسبة 124 ٪ من أفضل طريقة الحالية من حيث متوسط المكافأة المكتسبة عبر مهام متعددة. فيما يلي هو Architechture.
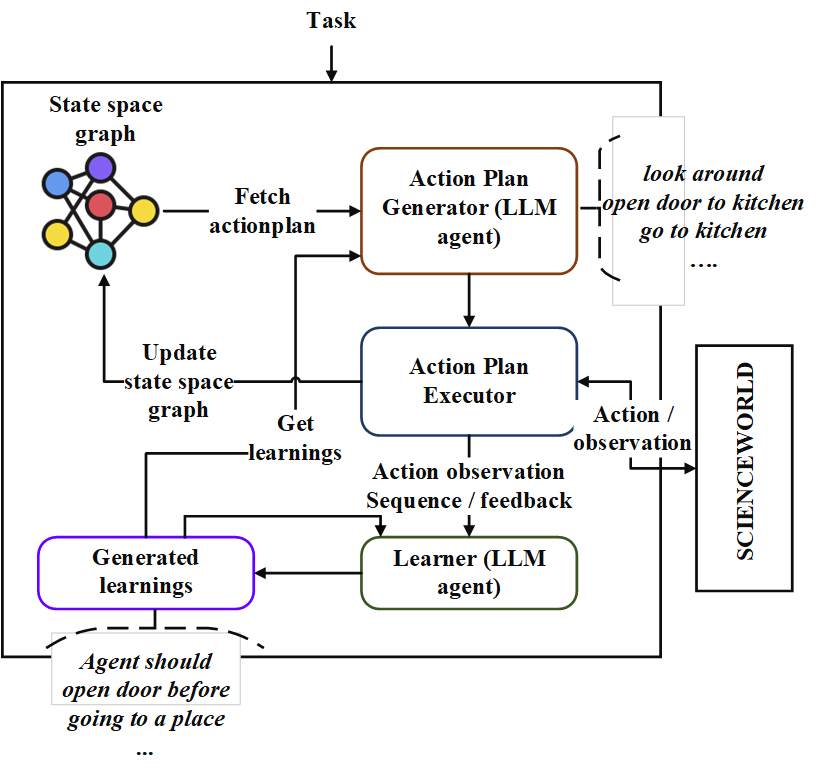
أولاً ، استنساخ الريبو وانتقل إلى دليل Neoplanner وتثبيت المتطلبات
git clone https://github.com/swarna-kpaul/neoplanner
cd neoplanner
python3 -m pip install -r requirements.txtثم تحتاج إلى تعديل ملف config/keys.py لتحديث OpenAiapikey . يمكنك الحصول على مفتاح API الخاص بك عن طريق تسجيل نفسك في Openai Portal. يمكن للمستخدمين لأول مرة الحصول على رصيد مجاني بقيمة 5 دولارات لتجربة. يمكنك الحصول على مفتاح API الخاص بك من عنوان URL هذا
بعد ذلك يمكن استيراد الحزمة
from solver import neoplannerتهيئة كائن Solver
# task is the identifier of tasks as specified in
# stmloadfile is the name of the file (with full path) that contains saved state. The state will be loaded initially. default value is None
# stmstoragefile is the name of the file (with full path) whare intermediate states can be saved. default value is None
# beliefstorefile is the name of the file (with full path) whare intermediate learnings can be saved. default value is None
# beliefloadfile is the name of the file (with full path) that contains intermediate learnings. The learnings will be loaded initially. default value is None
# sigma is exploration probability constant. Increasing its value would increase random exploration by the the LLM.
solverobj = neoplanner ( task = "2-1" , stmloadfile = None , stmstoragefile = None , beliefstorefile = None , beliefloadfile = None , sigma = 0.3 )قم بتشغيل Solver.
env = solverobj . train ()
######## get actionplan from statespace graph
additionalinstructions , actionplan , _ , _ , _ = env . getinstructions ()سيستمر التدريب في الركض حتى يتم الوصول إلى الهدف. يمكنك مقاطعة عملية التدريب بينهما. في هذه الحالة ، تأكد من توفير STMStorageFile و INTHSTOREFILE ، بحيث يتم حفظ الحالات والمعتقدات الوسيطة.
يمكنك تحميل STMStorageFile والاستعلام عن كائن ENV للحصول على خطة العمل من الرسم البياني للفضاء.
import pickle
from solver import scienv
env = scienv ( "2-1" )
stmstoragefile = < file name with full path >
with open ( stmstoragefile , 'rb' ) as f :
rootnodeid , invalidnodeid , DEFAULTVALUE , statespace , totaltrials , actiontrace , environment = pickle . load ( f )
env . model . rootnodeid = rootnodeid
env . model . invalidnodeid = invalidnodeid
env . model . DEFAULTVALUE = DEFAULTVALUE
env . model . statespace = statespace
env . model . totaltrials = totaltrials
env . environment = environment
env . reset ()
additionalinstructions , actionplan , _ , _ , _ = env . getinstructions ()يحتوي مجلد Protenfiles على جميع ملفات الدولة المدربين وملفات التعلم لمدة 7 مهام. يمكنك النظر في مخطط الإجراءات التي تم حلها للمهام باستخدام الكود أعلاه ، عن طريق تعيين STMStorageFile باسم الملف المناسب
يمكن رؤية التعلم من خلال تشغيل الكود التالي
import pickle
beliefloadfile = < belief load file name >
with open ( beliefloadfile , 'rb' ) as f :
beliefaxioms , totalexplore = pickle . load ( f )
print ( beliefaxioms ) @misc{paul2023sequential,
title={Sequential Planning in Large Partially Observable Environments guided by LLMs},
author={Swarna Kamal Paul},
year={2023},
eprint={2312.07368},
archivePrefix={arXiv},
primaryClass={cs.AI}
}


