เมื่อเร็ว ๆ นี้ มีการต่อต้านบนโซเชียลมีเดียต่อการใช้ข้อมูลผู้ใช้ของ Meta AI เพื่อฝึกโมเดล ผู้ใช้จำนวนมากได้ออกมาแสดงความเห็นต่อสาธารณะ ทำให้เกิดการอภิปรายอย่างกว้างขวางเกี่ยวกับความเป็นส่วนตัวของข้อมูลและการประยุกต์ใช้เทคโนโลยี AI บรรณาธิการของ Downcodes จะทำการวิเคราะห์เชิงลึกของปรากฏการณ์นี้ และหารือถึงสาเหตุที่อยู่เบื้องหลัง การตอบสนองของ Meta และทิศทางการพัฒนาที่เป็นไปได้ในอนาคต
ล่าสุดมีการกล่าวคำอำลา Meta AI บนแพลตฟอร์มโซเชียลมีเดีย ผู้ใช้จำนวนมาก รวมถึงคนดังอย่าง Tom Brady และนักดนตรี Cat Power ได้โพสต์ข้อความบน Instagram เพื่อพยายามป้องกันไม่ให้ Meta ใช้ข้อมูลของตนเพื่อฝึกโมเดล AI ปรากฏการณ์นี้สะท้อนให้เห็นถึงความกังวลอย่างลึกซึ้งของผู้ใช้เกี่ยวกับความเป็นส่วนตัวของข้อมูลและการใช้เทคโนโลยี AI และยังก่อให้เกิดความท้าทายใหม่สำหรับยักษ์ใหญ่ด้านเทคโนโลยีในการสร้างสมดุลระหว่างนวัตกรรมทางเทคโนโลยีและสิทธิของผู้ใช้
แม้ว่าข้อความเหล่านี้จะไม่มีผลผูกพันทางกฎหมาย และ Meta ได้แสดงให้เห็นชัดเจนว่าข้อความเหล่านี้ไม่มีผลทางกฎหมาย เราไม่สามารถมองข้ามสิ่งนี้ว่าเป็นความไม่รู้หรือความไร้เดียงสาของผู้ใช้ได้ ในทางตรงกันข้าม สิ่งที่พฤติกรรมนี้สะท้อนให้เห็นคือความกังวลของผู้ใช้เกี่ยวกับการพัฒนาอย่างรวดเร็วของเทคโนโลยี AI และความกลัวต่อการใช้ข้อมูลส่วนบุคคลในทางที่ผิด
ในความเป็นจริง Meta ใช้โพสต์และรูปภาพ Facebook สาธารณะย้อนหลังไปถึงปี 2550 เพื่อฝึกโมเดล AI ผู้ใช้มีตัวเลือกไม่กี่ตัวเลือกในการเลือกไม่รับ เว้นแต่พวกเขาจะอยู่ในสหภาพยุโรป ซึ่งจะทำให้ความไม่มั่นคงของผู้ใช้รุนแรงขึ้นอย่างไม่ต้องสงสัย ในกรณีนี้ ผู้ใช้สามารถปกป้องข้อมูลของตนได้โดยการทำให้โพสต์เป็นแบบส่วนตัวเท่านั้น ซึ่งเห็นได้ชัดว่าไม่ใช่วิธีแก้ปัญหาที่ดีนัก
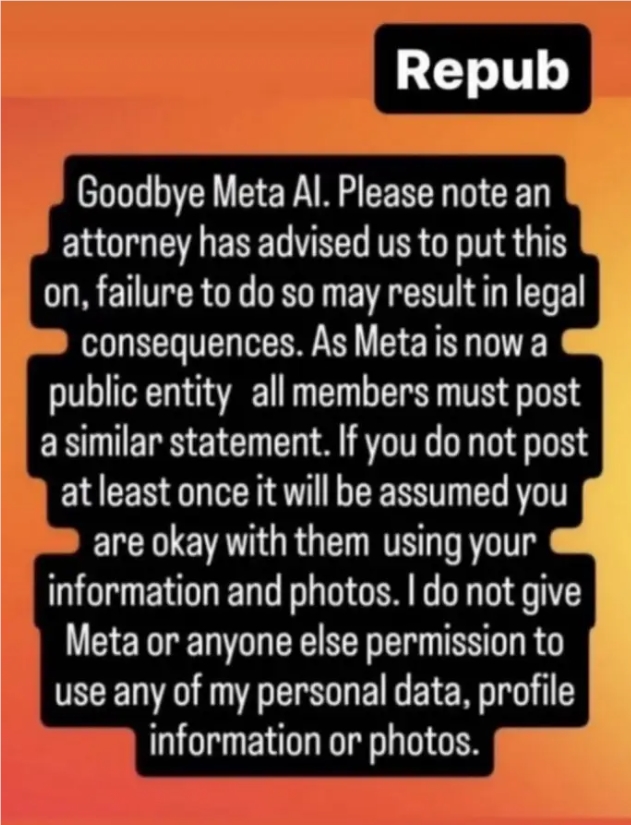
ข้อความคุ้มครองดังกล่าวที่เผยแพร่บนโซเชียลมีเดียไม่ใช่เรื่องใหม่ เนื้อหาที่คล้ายกันปรากฏบน Facebook และ Instagram ในช่วงหลายปีที่ผ่านมา โดยอ้างว่าเพื่อปกป้องผู้ใช้จากบริษัทเทคโนโลยี แม้ว่าการกล่าวอ้างเหล่านี้มักจะพิสูจน์ได้ว่าไม่ถูกต้อง แต่ก็สะท้อนถึงความไม่สมดุลของพลังงานที่ผู้ใช้รู้สึกเมื่อใช้แพลตฟอร์มเหล่านี้ ผู้ใช้เพลิดเพลินกับบริการฟรี แต่กังวลว่าข้อมูลของพวกเขาจะถูกนำไปใช้อย่างไม่เหมาะสม ความสับสนนี้เกิดจากข้อผิดพลาดต่างๆ ของ Facebook ในด้านการปกป้องความเป็นส่วนตัวของผู้ใช้ในอดีต
ก่อนงาน Meta Connect ที่กำลังจะมาถึง Alex Heath นักข่าว The Verge ได้ถามคำถามนี้กับ Mark Zuckerberg โดยตรง คำตอบของ Zuckerberg ดูเหมือนจะคลุมเครือเล็กน้อย เขากล่าวว่าสาขาเทคโนโลยีใหม่ ๆ จะเกี่ยวข้องกับปัญหาขอบเขตของการใช้งานและการควบคุมโดยชอบธรรม และกล่าวว่าปัญหาเหล่านี้จำเป็นต้องได้รับการอภิปรายและตรวจสอบอีกครั้งในยุค AI การตอบสนองนี้รับทราบถึงการมีอยู่ของปัญหาแต่ไม่ได้นำเสนอวิธีแก้ปัญหาที่เป็นรูปธรรม
สำหรับ Meta การสร้างสมดุลระหว่างนวัตกรรมทางเทคโนโลยีและการปกป้องสิทธิ์ผู้ใช้จะเป็นความท้าทายระยะยาวและยากลำบาก บริษัทจำเป็นต้องรับฟังผู้ใช้อย่างรอบคอบและเข้าใจข้อกังวลของพวกเขาเกี่ยวกับข้อมูลที่ใช้สำหรับการฝึกอบรม AI ในเวลาเดียวกัน Meta ยังต้องอธิบายนโยบายการใช้ข้อมูลให้โปร่งใสมากขึ้น เพื่อให้ผู้ใช้สามารถเข้าใจได้อย่างชัดเจนว่าข้อมูลของพวกเขาจะถูกนำไปใช้อย่างไร และให้ทางเลือกมากขึ้น
นอกจากนี้ อุตสาหกรรมอาจจำเป็นต้องทบทวนมาตรฐานทางจริยธรรมสำหรับการใช้ข้อมูลอีกครั้ง ในบริบทของการพัฒนาที่รวดเร็วของ AI การใช้ข้อมูลผู้ใช้อย่างสมเหตุสมผล และวิธีหาสมดุลระหว่างนวัตกรรมและการปกป้องความเป็นส่วนตัว ถือเป็นประเด็นที่ต้องแก้ไขอย่างเร่งด่วน
โดยรวมแล้ว คลื่นแห่ง "ลาก่อน Meta AI" สะท้อนให้เห็นถึงความกังวลของสาธารณชนเกี่ยวกับการพัฒนาเทคโนโลยี AI และความเป็นส่วนตัวของข้อมูล และยังก่อให้เกิดความท้าทายใหม่สำหรับบริษัทเทคโนโลยีอีกด้วย ในอนาคต การสร้างสมดุลระหว่างนวัตกรรมทางเทคโนโลยีและสิทธิของผู้ใช้จะกลายเป็นปัจจัยสำคัญในการพิจารณาว่าเทคโนโลยี AI สามารถพัฒนาได้อย่างยั่งยืนหรือไม่