В последнее время в социальных сетях прокатилась волна сопротивления использованию Meta AI пользовательских данных для обучения моделей. Многие пользователи публично заявили о своем несогласии, что вызвало широкие дискуссии о конфиденциальности данных и применении технологий искусственного интеллекта. Редактор Downcodes проведет углубленный анализ этого явления и обсудит его причины, реакцию Меты и возможные направления дальнейшего развития.
В последнее время на платформах социальных сетей прошла волна прощания с Meta AI. Многочисленные пользователи, в том числе такие знаменитости, как Том Брэди и музыкант Cat Power, разместили в Instagram заявления, пытаясь помешать Meta использовать их данные для обучения моделей ИИ. Это явление отражает глубокую обеспокоенность пользователей по поводу конфиденциальности данных и применения технологий искусственного интеллекта, а также ставит новые задачи перед технологическими гигантами в том, как сбалансировать технологические инновации и права пользователей.
Хотя эти заявления не имеют юридической силы, и Мета ясно дала понять, что эти тексты не имеют юридической силы, мы не можем просто отмахнуться от этого как от невежества или наивности со стороны пользователя. Напротив, такое поведение отражает обеспокоенность пользователей по поводу быстрого развития технологий искусственного интеллекта и их страх перед неправомерным использованием персональных данных.
Фактически, Meta действительно использует общедоступные посты и фотографии Facebook, датированные 2007 годом, для обучения своей модели искусственного интеллекта. У пользователей мало возможностей отказаться, если они не находятся в ЕС, что, несомненно, усугубляет неуверенность пользователей. В этом случае пользователи могут защитить свои данные, только сделав публикации приватными, что, очевидно, не является идеальным решением.
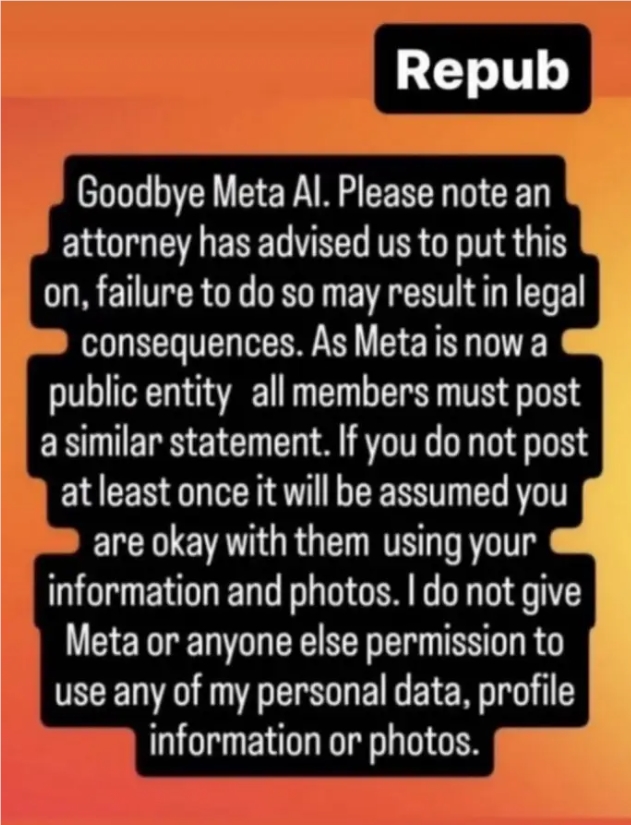
В таких защитных заявлениях, распространяемых в социальных сетях, нет ничего нового. Подобный контент на протяжении многих лет появлялся в Facebook и Instagram, утверждая, что он защищает пользователей от технологических компаний. Хотя эти утверждения часто оказываются необоснованными, они отражают дисбаланс сил, который испытывают пользователи при использовании этих платформ. Пользователи пользуются бесплатными услугами, но обеспокоены тем, что их данные будут использованы ненадлежащим образом. Эта двойственность связана с различными ошибками Facebook в защите конфиденциальности пользователей в прошлом.
Накануне предстоящего мероприятия Meta Connect репортер The Verge Алекс Хит напрямую задал этот вопрос Марку Цукербергу. Ответ Цукерберга показался немного расплывчатым. Он упомянул, что любая новая область технологий будет включать в себя пограничные вопросы добросовестного использования и контроля, и сказал, что эти вопросы необходимо заново обсудить и изучить в эпоху ИИ. Этот ответ признает существование проблемы, но не предлагает конкретных решений.
Для Meta вопрос о том, как сбалансировать технологические инновации и защиту прав пользователей, станет долгосрочной и трудной задачей. Компаниям необходимо внимательно прислушиваться к пользователям и понимать их обеспокоенность по поводу данных, используемых для обучения ИИ. В то же время Meta также необходимо более прозрачно объяснить свою политику использования данных, чтобы пользователи могли четко понимать, как их данные будут использоваться, и предоставлять больше выбора.
Кроме того, отрасли, возможно, придется пересмотреть этические стандарты использования данных. В условиях быстрого развития искусственного интеллекта вопросы, которые необходимо решить в срочном порядке, заключаются в том, как разумно использовать пользовательские данные и как найти баланс между инновациями и защитой конфиденциальности.
В целом, эта волна «Прощай, мета-ИИ» отражает обеспокоенность общественности по поводу развития технологий искусственного интеллекта и конфиденциальности данных, а также ставит новые задачи перед технологическими компаниями. В будущем то, как найти баланс между технологическими инновациями и правами пользователей, станет ключевым фактором, определяющим, сможет ли технология искусственного интеллекта развиваться устойчиво.