최근 Meta AI가 모델 훈련을 위해 사용자 데이터를 사용하는 것에 대해 소셜 미디어에서 저항의 물결이 일고 있습니다. Downcodes의 편집자는 이 현상에 대한 심층 분석을 수행하고 그 이유, Meta의 대응 및 가능한 향후 개발 방향에 대해 논의할 것입니다.
최근 소셜미디어 플랫폼에는 메타AI(Meta AI)라는 작별의 물결이 일고 있다. Tom Brady와 음악가 Cat Power와 같은 유명인을 포함한 수많은 사용자는 Meta가 AI 모델을 훈련하기 위해 데이터를 사용하는 것을 방지하기 위해 Instagram에 성명을 게시했습니다. 이러한 현상은 데이터 개인 정보 보호와 AI 기술 적용에 대한 사용자의 깊은 우려를 반영하며, 기술 혁신과 사용자 권리의 균형을 맞추는 방법에 대해 거대 기술 기업에 새로운 과제를 제시합니다.
이러한 진술은 법적 구속력이 없으며 Meta는 이러한 텍스트가 법적 효력이 없음을 분명히 밝혔지만, 이를 단순히 사용자 측의 무지나 순진함으로 일축할 수는 없습니다. 오히려 이러한 행동은 AI 기술의 급속한 발전에 대한 사용자의 우려와 개인 데이터의 오용에 대한 두려움을 반영합니다.
실제로 Meta는 AI 모델을 훈련하기 위해 2007년 이후의 공개 Facebook 게시물과 사진을 사용합니다. 사용자가 EU에 속하지 않는 한 거부할 수 있는 옵션이 거의 없으며 이는 의심할 여지 없이 사용자의 불안감을 악화시킵니다. 이 경우 사용자는 게시물을 비공개로 설정해야만 데이터를 보호할 수 있는데, 이는 분명히 이상적인 솔루션이 아닙니다.
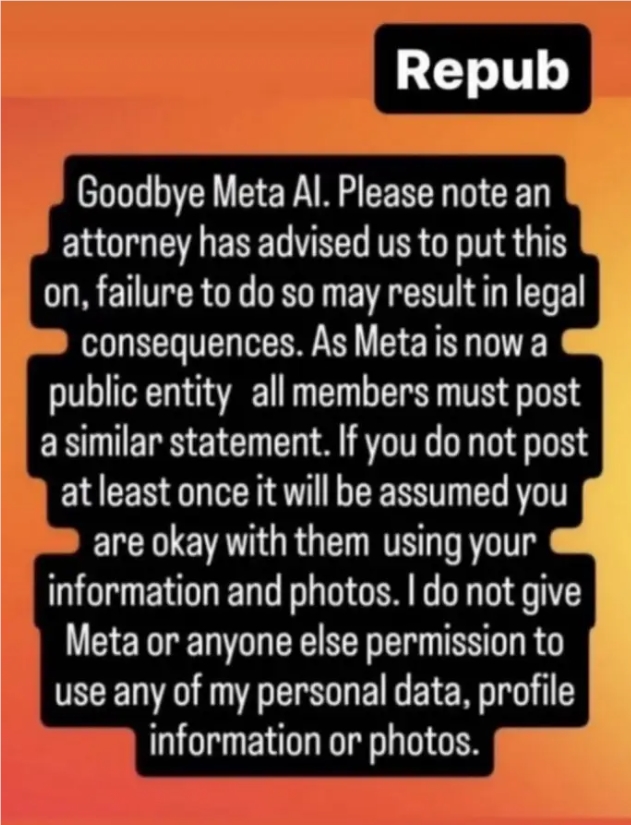
소셜 미디어에 퍼지는 이러한 보호 문구는 새로운 것이 아닙니다. 기술 회사로부터 사용자를 보호한다고 주장하는 유사한 콘텐츠가 수년에 걸쳐 Facebook과 Instagram에 나타났습니다. 이러한 주장은 종종 잘못된 것으로 판명되지만, 이는 사용자가 이러한 플랫폼을 사용할 때 느끼는 힘의 불균형을 반영합니다. 사용자는 무료 서비스를 즐기지만 자신의 데이터가 부적절하게 사용될 것을 걱정합니다. 이러한 양면성은 과거 Facebook의 사용자 개인 정보 보호에 대한 다양한 실수에서 비롯됩니다.
다가오는 Meta Connect 이벤트 전날, The Verge 기자 Alex Heath는 Mark Zuckerberg에게 직접 이 질문을 했습니다. 저커버그의 답변은 다소 모호해 보였다. 그는 모든 새로운 기술 분야에는 공정한 사용과 통제라는 경계 문제가 포함될 것이며 이러한 문제는 AI 시대에 재논의되고 검토되어야 한다고 말했다. 이 답변은 문제의 존재를 인정하지만 구체적인 해결책을 제시하지는 않습니다.
메타에게는 기술 혁신과 사용자 권리 보호 사이의 균형을 맞추는 것이 장기적이고 힘든 과제가 될 것입니다. 기업은 사용자의 의견을 주의 깊게 듣고 AI 훈련에 사용되는 데이터에 대한 우려 사항을 이해해야 합니다. 동시에 메타는 데이터 사용 정책을 보다 투명하게 설명하여 사용자가 자신의 데이터가 어떻게 사용되는지 명확하게 이해하고 더 많은 선택권을 제공할 필요가 있습니다.
또한 업계에서는 데이터 사용에 대한 윤리적 표준을 재검토해야 할 수도 있습니다. AI가 급격하게 발전하는 상황에서 사용자 데이터를 어떻게 합리적으로 활용할 것인지, 혁신과 개인정보 보호 사이의 균형을 어떻게 찾을 것인지는 시급히 해결해야 할 문제이다.
전체적으로 이번 'Goodbye, Meta AI' 물결은 AI 기술 발전과 데이터 개인정보 보호에 대한 대중의 우려를 반영하는 동시에 기술 기업에 새로운 과제를 제시합니다. 앞으로는 기술 혁신과 사용자 권리 사이의 균형을 어떻게 맞추느냐가 AI 기술이 지속 가능하게 발전할 수 있는지를 결정하는 핵심 요소가 될 것입니다.